零基础教你使用OpenVINO™工具套件部署YOLOv3模型
 openlab_4276841a
更新于 4年前
openlab_4276841a
更新于 4年前
以下文章来源于英特尔物联网 ,作者王一凡
概述
目标检测(Obiect Detection)近年来一直是深度学习视觉领域理论和应用的研究热点,目标检测即是在给定的图像中找到期望的物体,同时确定物体的标签和位置。YOLOv3(You Only Look Once,Version 3)是一种实时目标检测算法。本文在YOLOv3算法的基础上,介绍了目标检测模型的训练和部署,具体步骤如下。
第一步,使用PaddleX可视化客户端训练模型,并同样使用PaddleX进行了推理预测
第二步,使用OpenVINO™ 对训练的YOLOv3目标检测模型进行优化加速,再对模型行推理预测。
第三步,对已发布的YOLOv3 IR模型在不同平台(CPU/iGPU)上进行性能的测试与对比。
训练目标检测模型需要极大的算力,本文的硬件平台选择为英特尔® NUC(N ext Unit of Computer)产品线系列的幻影峡谷,英特尔® NUC 是英特尔® 公司设计制造的功 能强大的迷你计算机(Mini PC),而该系列中的幻影峡谷是一款具备 AI 训练能力的迷你计算机。如图1所示。
图1 幻影峡谷实物图
本文使用的幻影峡谷与深度学习模型训练相关的参数如下。
11th Gen Intel® Core™ i7-1165G7
Intel® Iris® Xe Graphic***r>
NVIDIA GeForce RTX 2060
本文需要的软件运行环境及其对应版本如下。
PaddleX Version 1.1.7
ONNX 1.9.0
OpenVINO 2021.2
使用PaddleX进行模型训练
第一步,标注数据集并导入。
首先从Kaggle直接下载猫狗数据集,使用Labelimg进行标注,将标注完毕的.xml格式文件和原文件的.jpg格式放在同一文件夹中,本文放在D:\MyDataset路径中。
打开PaddleX GUI可视化客户端新建数据集,选择标注数据对应存储路径导入标注好的数据集。校验成功后按照实际需求划分训练集、验证集以及测试集的比例。之后在可视化客户端新建项目,新建项目的任务类型需和数据集的任务类型保持一致。本文的YOLOv3算法选择目标检测这一任务类型。
第二步,配置参数训练模型。
项目创建完成后,载入客户端加载数据集,根据实际需求对模型参数、训练参数、优化策略三个方面进行参数配置,获得最佳任务效果。参数配置完成后即可开始训练,训练过程中可以通过VisualDL查看模型训练过程中参数的变化,如图2所示。
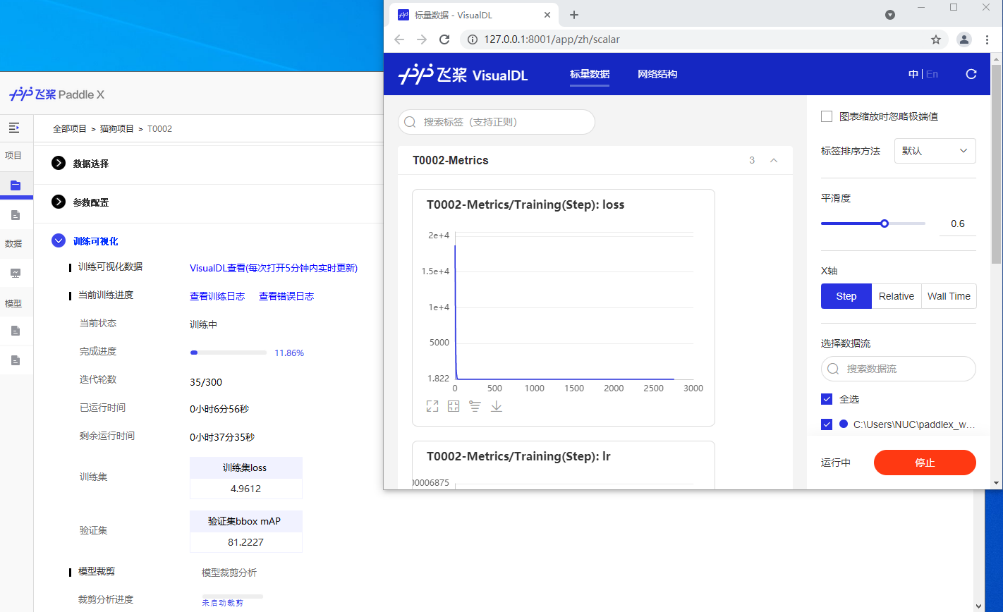
图2 使用PaddleX GUI进行模型训练
第三步,导出模型推理预测。
模型训练完毕,进入模型评估阶段,如果在混淆矩阵、模型精度、召回率等指标得到最优效果后,可以将模型导出,根据实际生产环境需求,将模型发布为需要的版本。使用PaddleX客户端模型训练完毕后,导出模型,使用python脚本对已发布的模型进行推理预测,模型预测代码见代码清单1。
代码清单1 使用PaddleX进行预测
#使用PaddleX进行预测
import paddlex as pdx
#导入预测图片路径和模型
test_jpg = "D:/MyDataset/JPEGImages/1140.jpg"
model = pdx.load_model("C:/Users/NUC/paddlex_workspace/P0002-T0002_export_model/inference_model")
#predict接口并未过滤低置信度识别结果,用户根据score值进行过滤
result = model.predict(test_jpg)
#可视化结果存储在./visualized_test.jpg中
pdx.det.visualize(test_jpg,result,threshold=0.5,save_dir="./")可得到如下图3所示推理结果。

图3 使用PaddleX推理结果
使用OpenVINO™工具套件优化推理
PaddleX支持将训练好的深度学习模型通过OpenVINO™工具套件对模型优化部署,在初始化 OpenVINO™工具套件使用环境,安装完毕 OpenVINO™工具套件相关依赖后即可进行加速部署。
第一步,OpenVINO优化
通过命令行<paddlex –export_inference –model-dir=./path/to/paddle_model –save_dir=./inference_model –fixed_input_shape=[w,h]>将paddle模型导入为inference格式模型,导出包括.succes*****odel__、__params__和 model.yml 四个文件的inference_model文件。
将PaddleX代码仓下载到本地文件夹中,初始化OpenVINO环境,再通过命令行<python converter.py --model_dir /path/to/inference_model --save_dir /path/to/openvino_model --fixed_input_shape [w,h]>转换代码,将inference格式模型转换为OpenVINO模型。如图4所示。
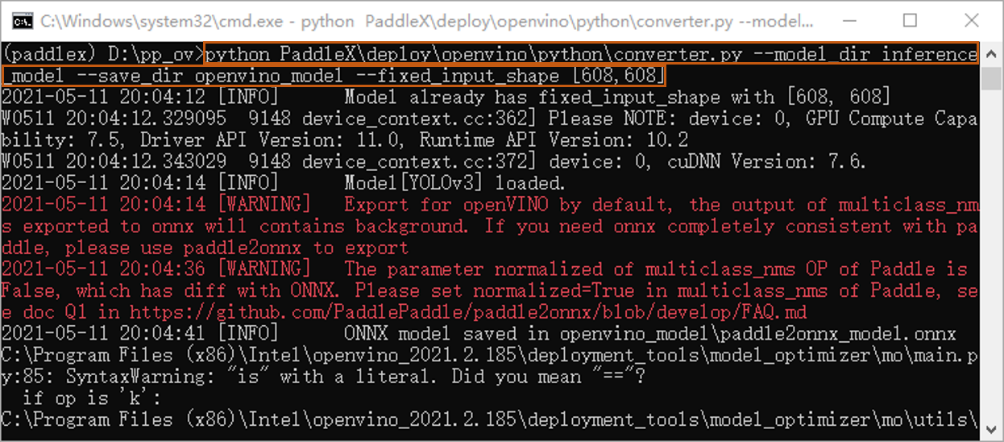
图4 转化为openvino_model
第二步,OpenVINO推理预测
加载OpenVINO模型,输入命令<python PaddleX\deploy\openvino\python\demo.py -m openvino_model\paddle2onnx_model.xml -i images\0001.jpg -c inference_model\model.yml>执行推理程序。推理结果如图5所示。
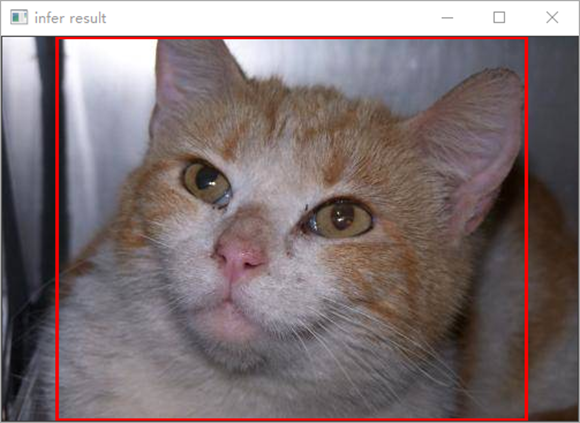
图5 使用OpenVINO推理预测结果
YOLOv3 IR模型性能分析
将上述训练并发布的YOLOv3 IR模型中paddle2onnx_model.xml和paddle2onnx_model.bin来做性能测试。通过响应延迟(Latency)和吞吐量(Throughput)是评价模型推理优化性能。
进入openvino默认安装路径的C:\Program File (x86)\Intel\openvino_2021.2.185\deployment_tools\tools\benchmark_tool的Windows命令行窗口,打开虚拟环境初始化OpenVINO, 输入命令<python benchmark_app.py -m PATH_TO_MODEL -d CPU|GPU>分别指定CPU和iGPU测试性能。
基于幻影峡谷的中央处理器第11代英特尔®酷睿™i7-1165G7和英特尔® Iris® Xe Graphics集成显卡,所得到的YOLOv3 IR模型性能测试结果见表1。
表1 YOLOv3 IR模型性能预测结果

由上述数据可以看到,YOLOv3模型经过OpenVINO优化后,在Iris® Xe Graphics集成显卡上的吞吐量可以达到19.56FPS,该速度完全满足大部分AI工程实践应用。
总结
本文使用了PaddleX的可视化客户端模式对目标检测模型进行了训练,PaddleX还提供Python API的模型训练模式,其使用方法以及模型零基础从训练到部署的详细步骤。
扫描下方二维码或点击阅读原文查看《零基础教你使用OpenVINO™工具套件部署YOLOv3模型》电子书全文。

无代码的模型训练方式以及像OpenVINO™工具套件对模型的加速和优化,这些模型训练和部署模式已经成为了新的趋势,能够把模型训练的复杂度降到最低,特别是在使用OpenVINO™工具套件对模型进行加速优化后的YOLOv3模型,在英特尔®11代i7-1165G7上可以跑到10.56FPS的性能,在Iris® Xe Graphics集成显卡上可以跑出19.56FPS的性能,模型的推理计算性能有了很显著的提升,完全能满足常见的AI应用需求,并且在一定程度上能够摆脱对独立显卡的依赖。
由此可见,像PaddleX和OpenVINO这样的深度学习模型训练和部署的工具,必然会在未来的AI工程应用中大放异彩。源于产业实践,关注行业需求,节约生产成本,加快创意落地才是王道,才能更快更好的赋能于产业实践。
0个评论