OpenVINO™ 手写字符识别模型与使用
 openlab_4276841a
更新于 4年前
openlab_4276841a
更新于 4年前
原创 贾志刚 英特尔物联网
引言

图-1 (原图)
模型介绍
在OpenVINO™ 2021.4版本中支持的手写数字识别模型为handwritten-score-recognition-0003,
支持<digit> or <digit>.<digit> 格式的数字识别与小数点识别。该模型的结构有两个部分组成,前面是一个典型的CNN骨干网络,采用的是VGG-16类似的架构,实现特征提取;后面是一个双向的LSTM网络,实现序列预测;最终的预测结果基于CTC解析即可。其输入与输出格式如下:
输入格式为:[NCHW]= [1x1x32x64]
输出格式为:[WxBxL]=[16x1x13]
其中13表示"0123456789._#",#表示空白、_表示非数字的字符
对输出格式的解码方式支持CTC贪心与Beam搜索,演示程序使用CTC贪心解码,这种方式相对简单,前面一篇文章中我们已经详细介绍过了,后面就直接套用即可!
模型使用与演示
Step 1: 读取图象并二值化
代码如下
Mat src = imread("D:/images/zsxq/ocr.png");
imshow("input", src);
Mat gray, binary;
cvtColor(src, gray, COLOR_BGR2GRAY);
adaptiveThreshold(gray, binary, 255, ADAPTIVE_THRESH_GAUSSIAN_C, THRESH_BINARY_INV, 25, 10);其中adaptiveThreshold函数实现对灰度图象自适应二值化,参数blockSize=25表示高斯窗口大小,constants=10表示自适应常量值。需要注意的是参数blockSize值必须为奇数。输出二值图象见图-2

Step 2: 使用轮廓分析过填充过滤小噪点
代码如下
std::vector<vector<Point>> contour****r>std::vector<Vec4i> hireachy;
findContour***inary, contours, hireachy, RETR_EXTERNAL, CHAIN_APPROX_SIMPLE);
int image_height = src.row****r>int image_width = src.col****r>for (size_t t = 0; t < contours.size(); t++) {
double area = contourArea(contours[t]);
if (area < 10) {
drawContour***inary, contours, t, Scalar(0), -1, 8);
}
}上面的代码findContours表示轮廓发现,RETR_EXTERNAL表示采用发现最外层轮廓,CHAIN_APPROX_SIMPLE表示采用简单的链式编码收集轮廓上的像素点集。contourArea表示计算一个轮廓的面积,计算方式基于格林积分公式。drawContours表示绘制轮廓,其中thickness参数为-1表示填充,大于零表示绘制边缘。这里通过对白色噪点填充为黑色,完成噪声去除,下图是去干扰之后的图象:
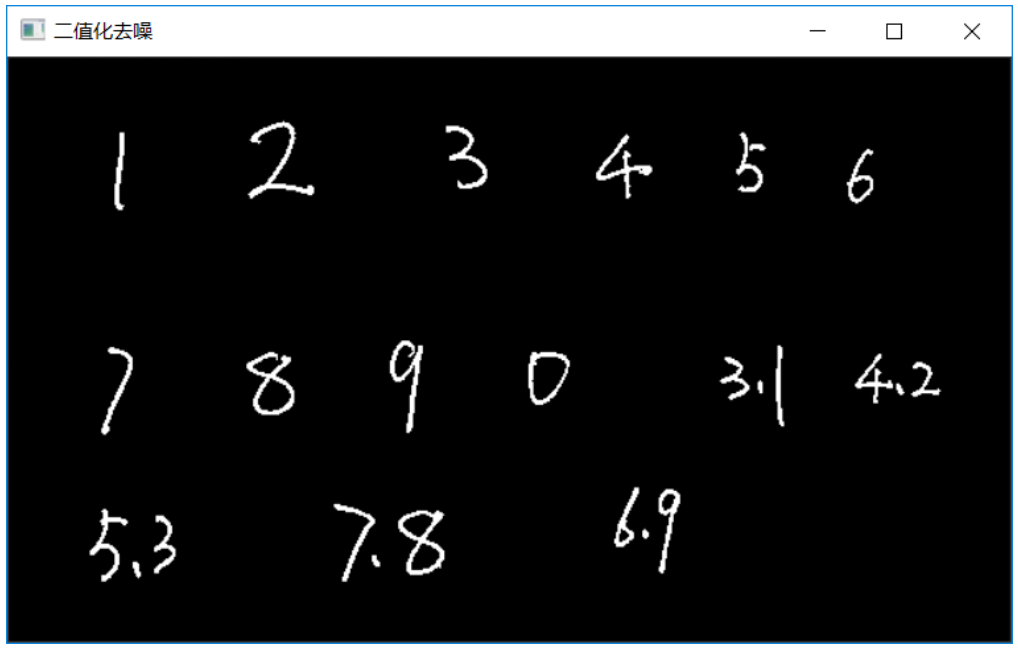
图-3(去噪之后)
Step 3:膨胀预处理
对第二步输出的图象我们不能直接通过轮廓发现截取ROI,然后交给数字识别网络去识别,原因是这样会导致ROI区域的宽高比失衡,导致输入的数字resize之后发现畸变,识别精度会降低,所以通过膨胀操作,把数字适度的加宽与加高,主要是加宽,这样保持输入ROI区域resize之后不变性,就很容易识别了。这部分预处理的代码如下:
Mat se = getStructuringElement(MORPH_RECT, Size(45, 5));
Mat temp;
dilate(binary, temp, se);其中dilate表示膨胀操作、然后对得到temp图象。这步操作的输出如下:
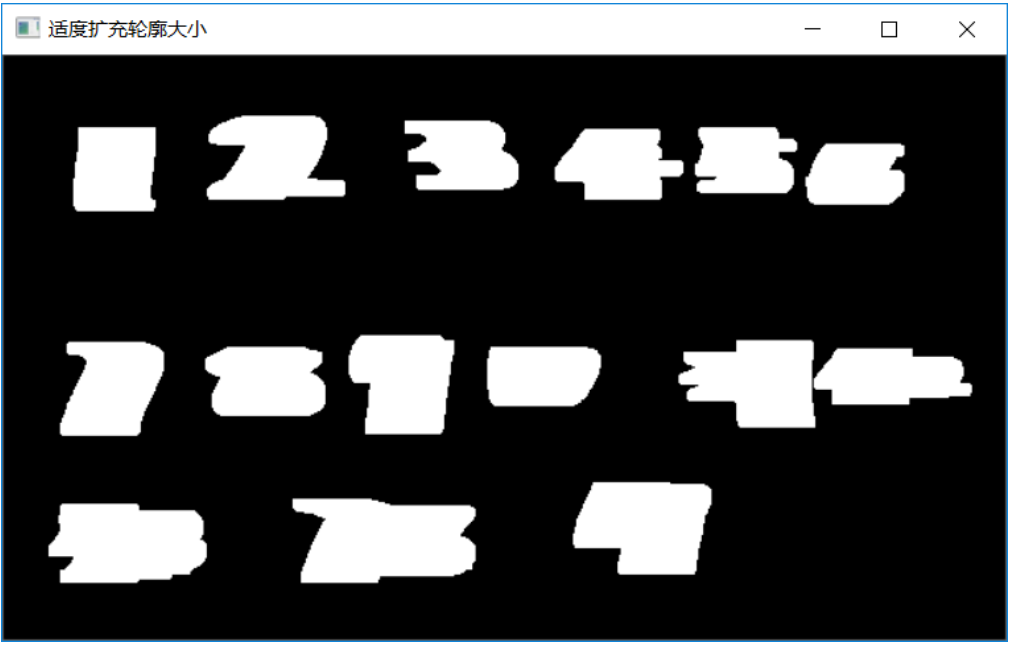
图-4(适度扩充之后)
Step 4:数字识别推理与解析
对图-4进行轮廓发现,截取ROI,遍历每个轮廓,调用识别推理即可输出。其中加载模型与获取推理请求,这里就不再赘述了,截取ROI与推理解析部分的代码如下:
// 处理输出结果
findContours(temp, contours, hireachy, RETR_EXTERNAL, CHAIN_APPROX_SIMPLE);
for (size_t t = 0; t < contours.size(); t++) {
Rect box = boundingRect(contours[t]);
Mat roi = gray(box);
size_t image_size = h*w;
Mat blob_image;
resize(roi, blob_image, Size(w, h));
// NCHW
unsigned char* data = static_cast<unsigned char*>(input->buffer());
for (size_t row = 0; row < h; row++) {
for (size_t col = 0; col < w; col++) {
data[row*w + col] = blob_image.at<uchar>(row, col);
}
}
// 执行预测
infer_request.Infer();
auto output = infer_request.GetBlob(output_name);
const float* blob_out = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(output->buffer());
const SizeVector reco_dims = output->getTensorDesc().getDim******r>const int RW = reco_dims[0];
const int RB = reco_dims[1];
const int RL = reco_dims[2];
std::string ocr_txt = ctc_decode(blob_out, RW, RL);
std::cout << ocr_txt << std::endl;
cv::putText(src, ocr_txt, box.tl(), cv::FONT_HERSHEY_PLAIN, 1.0, cv::Scalar(255, 0, 0), 1);
cv::rectangle(src, box, Scalar(0, 0, 255), 2, 8, 0);
}首先进行轮廓发现,然后根据每个轮廓截取ROI区域,设置输入数据,推理,解析输出采用CTC方式,最终得到的输出如下图所示:
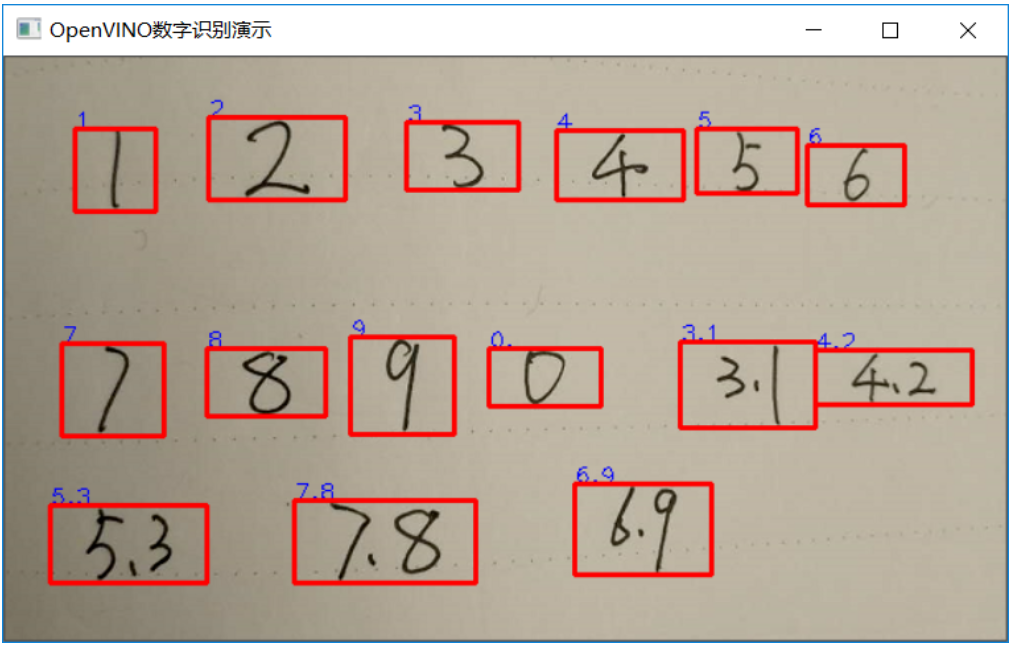
图-5(运行结果)
扩展探索
这里我没有采用场景文字检测来获取ROI,而是采用传统的二值图象分析来完成,主要是避免跟前面的文字内容重叠,同时启发更多的思路。另外采用膨胀扩展,有时候并非是上上之选,还可以直接修改ROI大小来扩展,这部分其实可以参考上一篇场景文字识别的代码,图-6就来是二值化之后,轮廓发现获取外接矩形,直接修改ROI大小的方式,同时根据横纵比过滤非数字符号。改动部分就是去掉第三步膨胀,然后直接在第四步循环中添加下面的代码;
Rect box = boundingRect(contours[t]);
float rate = box.width / box.height;
if (rate > 1.5) {
continue;
}
box.x = box.x - 15;
box.width = box.width + 30;
box.y = box.y - 5;
box.height = box.height + 10;
0个评论