西门子医疗利用至强® + OpenVINO™ 提升心脏 MRI 分析
 openlab_4276841a
更新于 4年前
openlab_4276841a
更新于 4年前
执行概要
健康和生命科学行业正在实施医疗保健数字化转型,并利用人工智能(AI) 加速临床工作流程,旨在提高准确性、优化诊断工作、降低医院成本,并为医学研究提供支持。人工智能可以快速提供解剖系统的状况并识别异常,从而帮助临床医生了解患者护理的侧重点。放射科医生和心脏病专家利用目标检测与图像分割等人工智能技术来更快、更准确地识别和比较相关规律及其他成像数据。若想利用人工智能应用,则必须拥有全新的系统性能水平才能跟上放射科医生的工作流程。西门子医疗和英特尔携手合作, 利用集成英特尔® 深度学习加速技术的第二代英特尔® 至强® 可扩展处理器和英特尔® OpenVINO™ 工具套件分发版,致力推进人工智能在心脏成像中的应用。
英特尔在人工智能软硬件技术方面具有显著优势,这为广泛的需要加速获取洞察的高性能、高准确度医疗成像应用和解决方案领域创造了机会,助力利用人工智能造福健康和生命科学行业。
挑战
心血管疾病导致的死亡人数占所有死亡人数的三分之一(平均每分钟 34 例,每年高达 1,800 万例)2。心脏 MRI 已成为评估心脏功能、心腔容积和心肌组织评估的黄金标准3。为从 CMR 图像中提取定量测量数据,心脏病专家通常使用手动或半自动的工具。然而, 这个步骤不仅十分耗时、容易出错,而且在解读图像时会受到用户间主观性的影响。除此之外,可用的心血管数据类型种类繁多,医生在解读和测量数据时存在个人主观性, 这可能会导致漏诊或误诊。西门子医疗是在医疗领域运用人工智能的先锋企业。他们研究新型人工智能用例,并将研究结果运用到他们的扫描仪、放射学应用和心脏学应用中。这些人工智能用例需要无缝实施到临床工作流程中,从而节省时间以及提高测量和诊断的一致性与准确性。
但是,在临床工作流程中运用人工智能万万不能以延迟作为代价。用于支持人工智能的计算系统需要及时应对扫描仪产生的数据,这就意味着系统要为人工智能推理提供低延迟和高吞吐量。只有这样,医疗机构才能提高每日病患接诊量。
提到人工智能工作负载,人们通常会想到使用 GPU 等加速器, 但这可能会增加系统和运营成本及复杂性,而且不利于向后兼容。西门子医疗部署的大部分系统已由英特尔® CPU 提供支持; 现在,西门子医疗希望利用基于现有 CPU 的基础设施来运行人工智能推理工作负载。
西门子医疗正在研发用于心脏磁共振成像 (MRI) 检查分析的基于人工智能的技术。心腔自动描绘是其中的一个例子,它是许多其他用例的基础,比如从心脏 MRI 中自动提取形态和功能特征, 用于诊断和疾病监控;对整个心脏进行定量功能分析;准确量化心腔容积、射血分数 (Ejection Fraction, EF) 和心肌质量。
西门子医疗十分关注如何使用集成英特尔® 深度学习加速技术的第二代英特尔® 至强® 可扩展处理器加快语义分割模型的推理速度。
解决方案
西门子医疗和英特尔紧密合作,针对第二代英特尔® 至强® 可扩展 处理器优化西门子医疗的心腔检测和量化模型。1 该人工智能模型执行左右心室的语义分割,并且可扩展到所有四个心腔。向人工智能模型输入的是一叠跳动心脏的 MRI 图像,输出的是心脏的区域或结构,其中每个结构用不同颜色标示。因此,需要耗费大量人力的手动图像分割流程实现了自动化,缩短了获得结果的时间。第二代英特尔® 至强® 可扩展处理器为人工智能模型的推理提供高性价比且灵活的平台,尤其是搭配英特尔® OpenVINO™ 工具套件分发版等工具一起使用时,可帮助加快高性能计算机视觉和深度学习推理在视觉应用中的发展,且不影响医疗行业所特有的时间关键型诊断以及决策的速度与精准度。
“现在,通过使用英特尔® 至强® 可扩展处理器, 我们可以开发多个近实时且非常重要的医疗成像用例,如心脏 MRI 等,并且避免了使用加速器所造成的成本或复杂性增加。”
——Dorin Comaniciu 博士,西门子医疗高级副总裁
第二代英特尔® 至强® 可扩展处理器内置英特尔® 深度学习加速技术,有助于加快深度学习用例。该技术在指令集中新增了矢量 神经网络指令 (VNNI)。卷积等任务在过去通常需要多条指令才能完成,而现在只需一条指令。其目标工作负载包括图像分类、图像分割、语音识别、语言翻译、对象检测等。为了充分利用这些指令,通常需要将以浮点 32 (fp32) 训练的模型量化为 int8。这种量化可以加快这些工作负载,但是若要保持模型准确性, 则必须小心对待。
团队使用英特尔® OpenVINO™ 工具套件分发版优化、量化和执行模型。最终获得的解决方案实现了高达 5.5 倍的速度提升, 且准确性几乎不受影响。
速度的提升使得未来的解决方案能够:
· 以出色的效率处理心脏 MRI 数据;在 200 fps 进行全面的心脏 MRI 检查时,可在一秒内完成短轴时空堆叠分析
· 使心脏 MRI 的近实时临床应用成为可能,在采集到可用数据后立即对数据进行解读
在处理大量人工智能工作负载时,第二代英特尔® 至强® 可扩展处理器能够更好地满足整合人工智能模型的产品需求。这也使得医疗设备公司能够以更低的成本向客户提供人工智能解决方案。高性能平台功能使他们不再需要专用加速器。
解决方案组件
第二代英特尔® 至强® 可扩展处理器
英特尔® 深度学习加速技术
英特尔® OpenVINO™ 工具套件分发版
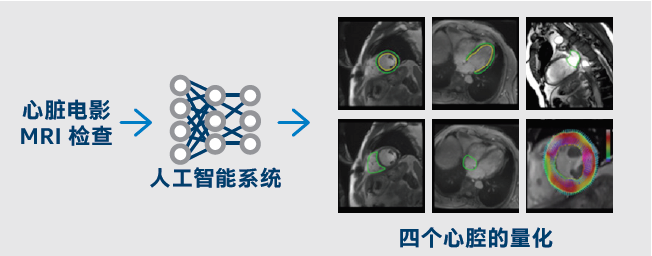
图 1. 西门子医疗和英特尔使用第二代英特尔® 至强® 可扩展处理器来加快心脏 MRI 的人工智能分析速度,从而提高性能并优化人工智能工作负载
工作原理
在第二代英特尔® 至强® 可扩展处理器上,与 fp32 模型基准相比,int8 的速度提升了高达 5.5 倍,这得益于英特尔® 深度学习加速技术带来的高效低精度卷积、int8 中的有效连接和重采样操作优化。神经网络经过训练,可识别心脏的各个区域。神经网络的权重和激活表示为 fp 数字。模型通常以 fp32 精度训练。一旦获得所需精度水平后,模型便可以整合到产品中。虽然如今产品中广泛部署了 fp32 模型,但将模型量化为 int8 可带来明显的性能优势。通常情况下,如果正确执行量化,所产生的模型几乎没有精度损失。我们的目标是将精度损失控制在 0.5% 以下。测试表明,最终产生的精度损失小于 0.001%。
英特尔使用英特尔® OpenVINO™ 工具套件分发版将西门子医疗训练过的模型从 fp32 量化为 int8,并确保精度不受影响。在图像验证集上,产生的精度变化低至 0.001%;能够维持成像结果,便于以较高的计算速度进行分析。
图 2a 应用于心脏电影 MRI 的 Deep-Dense Net 展示了从图像强度的分层编码到心脏结构的解码4
图 2b 显示了心脏的分割图像。人工智能模型对心脏的各个结构进行分割。ONNX 输出显示了量化前运行的解决方案。经过量化的 int8 输出显示了几乎相同的精度。
图 3 显示了为利用 VNNI 而量化深度学习模型所采用的整个过程。将用于心脏 MRI 图像分割的西门子医疗 ONNX fp32 模型作为输入提供给模型优化器,该模型优化器是英特尔® OpenVINO™ 工具套件分发版中的一个组件。所得到的模型进行了多项优化,如节点合并、批量规范化消除和常量折叠。然后, 校准工具使用该模型和图像的验证数据集生成中间表示与统计信息,如每个通道的最大和最小激活数。这样才能在量化的时候保持精度。生成内部表示的过程是一个一次性的离线过程。在运行时,英特尔® OpenVINO™ 工具套件分发版使用统计信息执行 int8 模型。
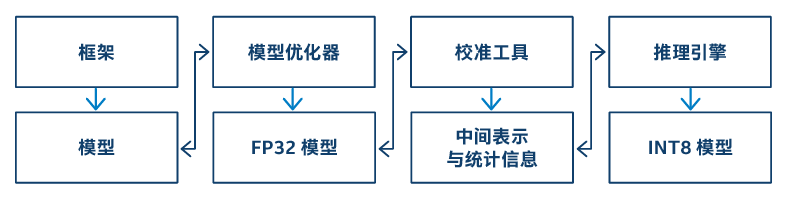
图 3. 使用英特尔® OpenVINO™ 工具套件分发版执行的量化过程
除了量化,英特尔和西门子医疗还进行了更多的优化。双方共同为英特尔® OpenVINO™ 工具套件分发版中的 CPU 扩展增加了 int8 支持,为重采样扩展增加了 int8 数据类型,并为英特尔® OpenVINO™ 工具套件分发版 CPU 插件创建了自定义合并多个数组原语以便并行执行操作。

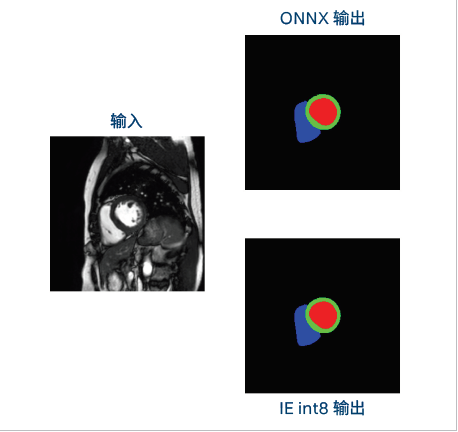
图 2a. 应用于心脏电影 MRI 的 Deep-Dense Net 展示了从图像强度的分层编码到心脏结构的解码4
图 2b. 成像结果显示几乎没有变化,而性能却有所提升
结果
通过以上优化,我们在第二代英特尔® 至强® 可扩展处理器上对模型进行了基准测试:在第二代英特尔® 至强® 可扩展处理器单路上使用 14 个推理流,每个推理流含两个线程。结果表明,其速度较基准模型提升了高达 5.5 倍,总吞吐量为每秒 201.36 张 图像。1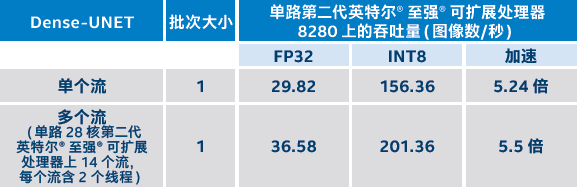
结论
心脏 MRI 图像分割模型的优化体现了第二代英特尔® 至强® 可扩展处理器的强大功能,使西门子医疗能够满足健康和生命科学行业对数据密集型人工智能应用与日俱增的需求。优化过程表明了团队如何定制解决方案从而满足对性能和准确性的特定实际要求。西门子医疗将继续完善和发展人工智能训练模型,旨在提高准确性并支持不断演进的工作负载和用例。
通过英特尔和西门子医疗的共同努力,健康和生命科学行业可以利用人工智能来集成和分析大量数据,提高诊断准确性,实施更具针对性的治疗,并改善医疗现状。
0个评论