精度不变,两行代码无痛实现推理加速1.34倍,极市平台联合OpenVINO™加速AI开发部署
 openlab_4276841a
更新于 4年前
openlab_4276841a
更新于 4年前
在AI落地应用的浪潮中,极市平台通过云平台形式专注赋能开发者,不断为万千开发者提供AI开发应用全流程中的各类最新服务,包括数据、算力、训练环境、模型、部署加速工具等等。
在模型开发和部署方面,极市平台集成了最新版本的OpenVINO™工具,助力开发者在最小化代码修改的条件下加速AI算法在各类生产环境中规模化部署应用,尤其是在Intel丰富的硬件资源平台上(CPUs、iGPUs、VPUs等等)。
本文重点介绍了极视角与英特尔开发人员共同研发的OpenVINO™最新功能,无缝集成TensorFlow框架,对于熟悉TensorFlow开发的开发者来说,在原有代码的基础上只需要添加几行简单代码就可以无痛实现模型精度不变的前提下推理加速1.34倍以上,避免了显式地进行OpenVINO™转换以及推理部分代码的重新编写,大大简化OpenVINO™工具的使用,加速AI算法在生产环境中的应用部署。
无痛实现 1.34 倍加速推理
我们先来看看本文方法在模型推理加速上具体表现:
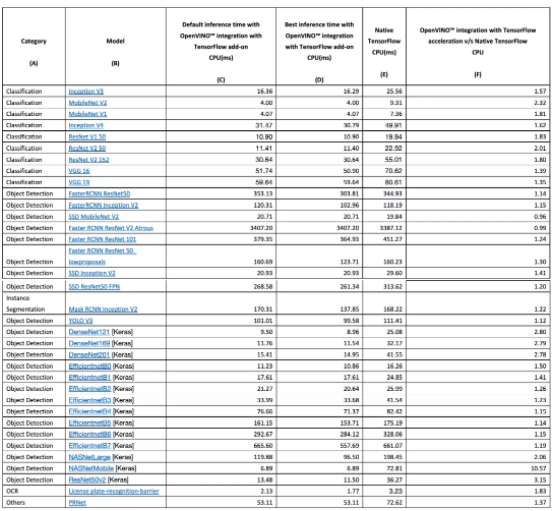
可以看到,在同一测试环境下,OpenVINO™ 与 TensorFlow 的集成实现了 1.34 的加速几何平均值,同时,模型的准确性保持不变:

具体实操
OpenVINO™ 与 TensorFlow 的集成专为使用 OpenVINO™ 工具套件的开发人员而设计——通过最少的代码修改来提高推理应用程序的性能。该集成为提高TensorFlow 兼容性提供以 OpenVINO™ 工具套件内联优化和所需运行时,并加速了各种英特尔芯片上多类AI模型的推理。
通过将以下两行代码添加到 Python 代码或 Jupyter Notebooks 中,就可以极大地加速你的 TensorFlow 模型的推理:
import openvino_tensorflow
openvino_tensorflow.set_backend('<backend_name>')OpenVINO™ 与 TensorFlow 的集成通过将 TensorFlow 图巧妙地划分为多个子图,再将这些子图分派到 TensorFlow 运行时或 OpenVINO™ 运行时,从而实现最佳加速推理。
# 工作流概述
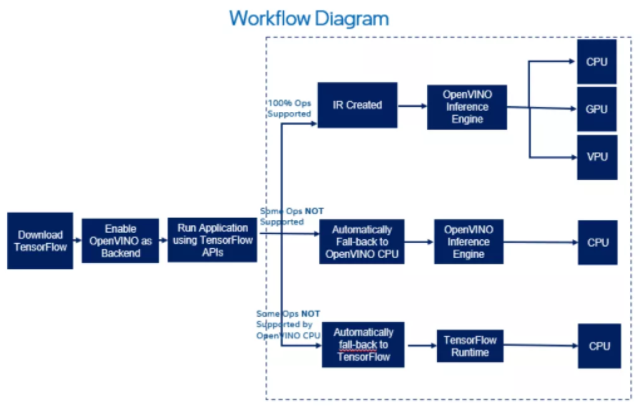
同时,通过 openvino_tensorflow ,我们能够非常轻松地使用不同硬件:
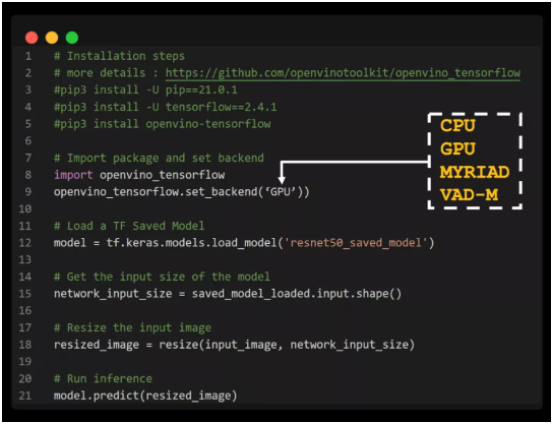
更多的详细信息可以前往 Github:
https://github.com/openvinotoolkit/openvino_tensorflow
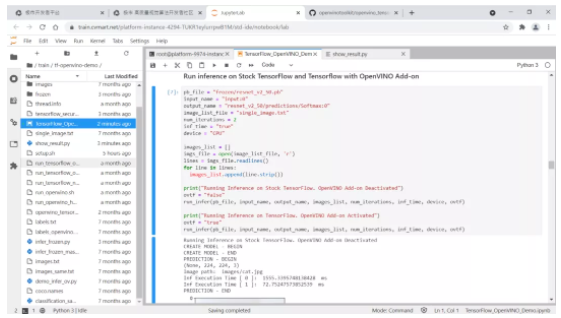
# 在Extreme Vision notebooks中集成
在Extreme Vision IDE中可以直接将OpenVINO™与TensorFlow集成。如下图所示,你只需要简单地导入openvino_tensorflow,即可无缝加速 Jupyter Notebook 中在CPU上推理的所有 TensorFlow模型,同时可以继续使用标准的TensorFlow API,而无需代码重构。
对推理加速更深的讨论
从前文对推理加速上的结果展示中,我们可以看到通过添加 2 行代码激活OpenVINO™与 TensorFlow 的集成后,可以获得最高达 10 倍的推理加速。但也有个别模型出现了异常情况,如Mask RCNN Atrous 和 SSD Mobilenet V2,因此我们对如何获得最佳性能进行了讨论:
#01 OPENVINO_TF_MIN_NONTRIVIAL_NODES 变量
该变量设置了聚类中可以存在的最小操作数。如果操作数小于指定的数量,则聚类将回退到 TensorFlow。默认情况是根据总图大小计算的,但除非手动设置,否则不能小于 6。另外,我们将此变量设置为 15 和 22 来观察模型进一步的性能增强,并以此得到了最终的最佳推理性能。因此,在具体的开发应用中应通过默认值或实验来确定能够为模型提供最佳性能的变量最佳值。
#02 冻结 Keras 模型以获得最佳性能
一些 Keras 模型可能包含训练操作,这会导致 TensorFlow 产生控制流。由于 OpenVINO™ 工具套件不支持这些操作,因此图形可能会被划分为较小的聚类。因此,在使用 OpenVINO™ 与 TensorFlow 的集成时,冻结模型可以避免这些操作并提高整体性能。
使用 Keras API 的 DenseNet121 推理应用代码示例:
import tensorflow as tf
from tensorflow import kera***r>from tensorflow.keras.applications.densenet import DenseNet121
# Add two lines of code to enable OpenVINO integration with TensorFlow
import openvino_tensorflow
openvino_tensorflow.set_backend("CPU")
model = DenseNet121(weights='imagenet')
# Run the inference using Keras API
model.predict(input_data)下面是冻结和运行 Keras 模型的一个示例代码,通过这种方式,我们能够优化使用 OpenVINO™ 与 TensorFlow 的集成实现的最佳性能。
import tensorflow as tf
from tensorflow import kera***r>from tensorflow.keras.applications.densenet import DenseNet121
from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2
# Add two lines of code to enable OpenVINO integration with TensorFlow
import openvino_tensorflow
openvino_tensorflow.set_backend("CPU")
model = DenseNet121(weights='imagenet')
# Freeze the model first to achieve the best performance
# using OpenVINO integration with TensorFlow
full_model = tf.function(lambda x: self.model(x))
full_model = full_model.get_concrete_function(
tf.TensorSpec(model.inputs[0].shape,
model.inputs[0].dtype, name=model.inputs[0].name))
frozen_func = convert_variables_to_constants_v2(full_model)
frozen_func.graph.as_graph_def()
session = tf.compat.v1.Session(graph=frozen_func.graph)
prob_tensor = frozen_func.graph.get_tensor_by_name(full_model.outputs[0].name)
# Run the inference on the frozen model
session.run(prob_tensor, feed_dict={full_model.inputs[0].name : input_data})#03 Mask RCNN Atrous和SSD Mobilenet
如上文的结果所示,OpenVINO™与TensorFlow的集成可以加速大多数TensorFlow模型,但由于一些模型具有OpenVINO™与TensorFlow集成尚不完全支持的工作组件(例如运算符、层等),如Mask RCNN Atrous和SSD Mobilenet V2等一些模型仍在开发完善中。
为了扩大模型覆盖范围以及进一步提升性能,极视角技术团队将会继续测试和完善OpenVINO™与TensorFlow的集成,以帮助更多使用TensorFlow开发人员能够更好地应用极市平台。
**本文转自:极市平台