使用OpenVINO优化和部署DenseNet模型并在DevCloud上完成性能测试_下篇
 openlab_4276841a
更新于 4年前
openlab_4276841a
更新于 4年前
2. 使用 Intel® DevCloud 不同边缘节点
面向边缘的 Intel® DevCloud 是一项云服务,旨在帮助开发人员使用 Intel® OpenVINO™ 工具套件构建原型并试验计算机视觉应用,注册成功后,可以访问一系列的基于 Python 和 C++的 Iupyter* Notebook 教程和示例解决方案,并通过 web 浏览器直接执行。本文通过 Jupyter* Notebook 中给出的基于Python 语言的 Benchmark_APP 示例,访问不同的边缘节点进行性能测试。
使用 Intel® DevCloud 在不同的边缘节点进行性能测试一共分为四个步骤:
● 第一步,在 Intel® DevCloud 的 Benchmak_APP 目录下创建 IR_models 文件夹目录结构
● 第二步,将 FC-DenseNet-103 IR 模型导入 IR_models 内对应数据格式子文件夹
● 第三步,使用 Benchmark_APP 对不同的边缘节点进行性能测试
● 第四步,通过测试结果进行性能分析,选出高性能 AI 部署
解决方案
具体步骤如流程图 2-1 所示:

2.1 生成 IR_models 目录结构并导入模型
在 Jupyter* Notebooks 的 Reference-samples/iotdevcloud/openvino-dev-latest/develop-samples/python/benchmarkAPP-python 的所在目录中,创建 IR_models 目录结构,因为 Benckmark_APP 的路径是固定的,需要配合其固定好的目录结构,让 Benchmark_APP 能够找到对应的IR_modes。首先创建 IR_models 文件夹,并在文件夹中创建 FP16、FP16-INT8、FP32 三个不同数据格式的子文件夹,上传自己的模型到对应的子文件夹中。其具体步骤如下:第一步,首先进入网址 https://devcloud.intel.com/edge/,注 册 并 登 录, 然 后 进 入 网 址 https://software.intel.com/content/www/us/en/develop/tools/devcloud/edge/build.html后,点击页面中显示的“Connect and Create”按键,如图 2-1所示。即可转入 Jupyter* Notebooks 界面,然后即可运行相关测试
第二步,进入 Reference-samples/iot-devcloud/openvinodev-latest/develop-samples/python/benchmarkAPPpython 路径目录下,然后点开右上方的“New”选项,在弹出的选项框中选择“Teminal”进入命令行终端。如图 2-2 所示。
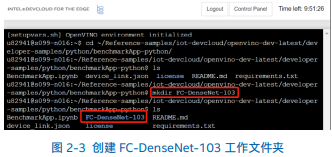
第三步,进入命令行终端后即可在命令行终端使用命令创建 IR_models 文 件 夹 目 录 结 构, 进 入 Teminal 后, 使 用 命令 < cd ~/Reference-samples/iot-devcloud/openvinodev-latest/developer-samples/python/benchmarkApppython > 进入 benchmarkAPP-python 的文件夹目录下,再使用命令 列出其全部子文件夹,然后使用命令 创建 FC-DenseNet-103 模型所对应的工作文件夹,如图 2-3 所示。
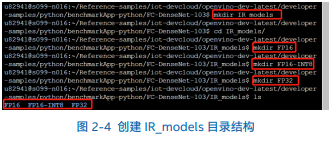
第四步,使用命令 进入其 FC-DenseNet103 目录下,使用命令 创建 IR_models文件夹,继续使用命令进入其目录下,分别使用命令 ,创建三种不同数据类型的子文件夹,以配合 Benchmark_APP 需要的目录结构,三种不同数据格式的子文件夹创建完毕后,如图 2-4 所示,即可根据模型的数据格式上传到对应文件夹。
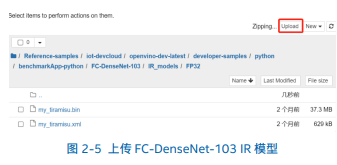
2.2 访问边缘节点进行性能测试
将“创建 IR_models 目录结构”和“导入本地 FC-DenseNet-03模型”的准备工作做完后,即可访问 Intel® DevCloud 的边缘节点,对不同的 Intel 硬件进行性能的测试本文。使用 Intel®DevCloud 提供的基于 Python 语言的 Benchmark_APP 示例,访问不同的边缘节点进行性能测试。其步骤如下:第一步,打开 Reference-samples/iot-devcloud/openvinodev-latest/developer-samples/python/benchmarkApppython 路径下的“BenchmarkAPP.ipynb”,点击左边目录“1.9Creating lists of FP16 and FP32 models”查看其 Python 脚本,并在脚本中添加语句“models = [“FC-DenseNet-103”]”,从头运行到 1.9 节,可以看到以及读入 FP32 数据格式的 FCDenseNet-03 IR 模型,如图 2-6 所示。

第二步,读入 IR 模型后,请先运行“BenchmarkAPP.ipynb”里“Intel® Distribution of OpenVINO™ Toolkit version check:”和“Wait until the benchmarking report files are written”两个部分。然后即可使用深度学习模型对单个系统进行基准测试。
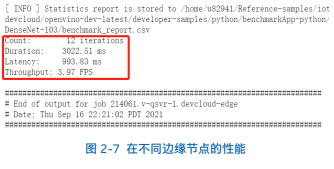
在“Benchmark Individual system with the deep learning model”这一部分单元格中,列举五个不同硬件的边缘节点来进行推理工作。首先以“3.0.1 Run the Benchmark tool app with Intel® Core™ CPU”单元格为例,此单元格将作业提交给配备 Intel® Core™ i5 6500TE CPU 的 IEI Tank* 870 的边缘节点,推理工作将在 CPU 上运行。运行完此单元格后,会在“benchmarkAPP-python” 路 径 下 生 成 相 关 的“benchmark_app_job.sh…”相关运行日志文件。点开日志文件,便可以显示出在此边缘节点推理的吞吐量和延迟,如图 2-7 所示:
第三步,确定 Intel® DevCloud 所支持的边缘节点群,边缘计算节点是面向物联网边缘机器学习推理构建和配置的工业计算系统,并已经托管在 DenCloud 中,一边使用预先开发的示例或者试验各种架构和解决方案。首先确定 Intel® DevCloud 所支持的边缘节点群,以及他们的 Group ID。进入网址 https://
devcloud.intel.com/zh/edge/resource_docs/selecting_targets/-u8fb9-u7f18-u8282-u70b9 即可查看 Intel® DevCloud 所支持的边缘节点群及其相关的配置信息,如图 2-8
所示:

3. 对不同边缘节点进行性能分析
在边缘节点群中可以根据需求选择不同的边缘节点,对不同 的 架 构 或 解 决 方 案 进 行 试 验, 在 本 步 骤 以 Group ID 为idc046,CPU 为 Intel® Core™ i5 1145G7E,GPU 为 Intel® Iris®Xe Graphics 边 缘 节 点 为 例, 介 绍 怎 样 在“BenchmarkAPP.ipynb”中添加新的边缘节点并使用 Benchmark_APP 对其边缘节点的模型部署进行性能测试和分析。3.1 使用 CPU 边缘节点进行性能分析
使用 Intel® Core™ i5 1145G7E CPU 边缘节点进行性能分析的具体操作步骤如下:第一步,在“BenchmarkAPP.ipynb”中重新打开一个单元格,并将单元格“3.0.1 Run the Benchmark tool app with Intel®Core™ CPU”里的代码脚本**进新打开的单元格。
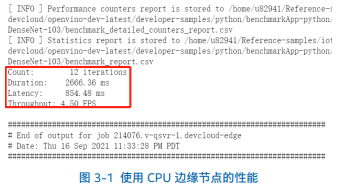
第二步,将单元格内脚本代码的第一行单引号里面的内容改为新的 Group ID,即为改成 ‘idc046’>。启动运行单元格,同 2.2 节第二步表述的过程一样,会在“benchmarkAPP-python”路径下生成相关的“benchmark_app_job.sh…”相关运行日志文件。点开日志文件,便可以显示出在 CPU 为 Intel® Core™ i5 1145G7E 边缘节点推理的吞吐量和延迟,如图 3-1 所示:
3.2 使用 GPU 边缘节点进行性能分析
使用 Intel® Iris® Xe Graphics GPU 边缘节点进行性能分析的具体操作步骤如下:第一步,在“BenchmarkAPP.ipynb”中重新打开一个单元格,并 将 单 元 格“3.0.3 Run Benchmark tool application with Intel® HD Graphics 530 GPU”里的代码脚本**进新打开的单元格。
第二步,将单元格内脚本代码的第一行单引号里面的内容改为新的 Group ID,即为改成 ‘idc046’>。
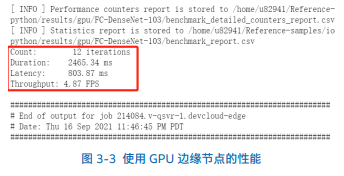
第三步,由于本次的 GPU 边缘节点为 Intel® Iris® Xe Graphics,且模型的数据格式为 FP32,所以请修改脚本中第十九行to_finish(job_id_gpu,verbose,model)> ,将双引号内的 GPU 版本更改为本次试验的 GPU 版本,即为 Iris® Xe Graphics GPU”] = wait_for_job_to_finish(job_id_gpu,verbose,model)>, 如图 3-2 所示:
3.3 FC-DenseNet-103 模型在不边同缘节点 性能
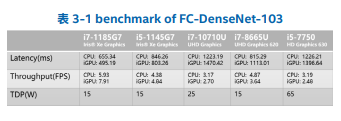
将 Group ID 为 idc046,CPU 为 Intel® Core™ i5 1145G7E,GPU 为 Intel® Iris® Xe Graphics 边缘节点的 CPU 和 GPU 吞吐量和延迟测试出来后,即可同样步骤对其他边缘节点进行性能的分析,本文选择了 7-11th CPU 的边缘节点,进行性能的测试与对比,结果如表 3-1 所示,在表中的边缘节点群中可以根据需求选择不同的边缘节点,对不同的架构或解决方案进行试验。
本文转自:英特尔物联网 王一凡
0个评论