转发技术风雨三十年,你经历过……
 小o
更新于 4年前
小o
更新于 4年前
作者简介:岳青伦,任职于华为产品与解决方案部,研究方向SDN/NFV
前言

记得刚到大学报道的那天,为了给家人报个平安,我在电话亭里足足等了两个小时,而我的父亲为了接这个电话也赶到近百米的土豪家。
作为我人生第一个通信工具Motorola BP机在我大学毕业使用两个月后迅速下岗,换了第一台GSM数字移动电话飞利浦989,从此满足了随时随地沟通和被沟通的需求;那个年代最蛋疼的莫过于双向收费,朋友为了测试通话质量是否OK浪费我六角钱让我至今还难以忘怀,因此成就了短信,也有了仅仅一个除夕夜中国三大运营商短信破百亿的历史记录;接下来的近十个年头,换遍了诺基亚的N个型号,N8250、N6810、N3250、N5800… 直到它光荣的死去。
有句话叫“你不革命就被人割命”,苹果,乔布斯……在即将跨入二十一世纪第二个十年时,发布了革命性的产品,世界从此改变!直到今天,苹果依旧是最科技最时尚的个人消费品代言人,2014年苹果公司的市值超7000亿,换成GDP超过105个国家,啧啧,只有羡慕+嫉妒+恨啊!
时代的变迁、社会的进步,背后的推手要么是伟大的思想家政治家,要么是科技的巨大进步。回头看看我们亲身经历的这三个十年的伟大变化,你会发现是科技的发展成就了这些,再具体点,就是信息技术、计算机技术、半导体技术、互联网技术,让我们的生活发生了翻天覆地的变化。
一、 IP起航
让我们先简单回顾下互联网大事记:
- 1957年前苏联发射人类第一颗人造地球卫星,作为响应,美国国防部组建ARPA;
- 1961年MIT的Leonard Kleinrock发表第一篇有关包交换的论文;
- 1969年美国国防部委托开发ARPANET,AT&T提供速率为50Kpbs的通信线路;
- 1971年BBN的Ray Tomlinson发明了通过分布式网络发送消息的email程序;
- 1973年ARPANET首次进行国际联网:伦敦大学(英国)和NORSAR(挪威);同年以太网诞生于美国施乐公司,速率为2.94Mpbs;
- 1974年Vinton Cerf和Bob Kahn发表了论文对TCP协议的设计作了详细的描述;
- 1976年英国女王伊丽莎白二世在皇家信号与雷达研究院发出一封电子邮件;
- 1978 TCP分解成TCP和IP两个协议;
- 1982年,正式把“互联网”定义为使用TCP/IP连接起来的一组网络;
- 1984年引入名字服务系统DNS,主机数超过1000台;
- 1986年美国建成NSFnet,主干网速率56Kbps;
- 1992年互联网协会(ISOC)成立,接入互联网的主机超过一百万;
- 1994年中国接入互联网,国际专线64Kbps;
- 1995年微软发布Windows95,从此Wintel联盟一发不可收拾;同年WWW、搜索引擎成为年度重大技术;
- 1998年谷歌成立;
- 2000年互联网泡沫破裂,NASDAQ指数一泻千里;
- 2001年英国电信公司的子公司MAN开通了欧洲第一个3G网络;
- 2007年苹果公司发布第一代iPhone,开创智能终端新时代;
- 2014年iPhone总销售突破5亿,苹果公司市值突破7000亿$;
- ……
2000年之前的十年离我们渐渐远去,那个时候拨号上网是唯一了解世界的途径,而且按分钟计费,像打电话一样;90年代校园局域网大发展,有web、bbs、email,甚至可以开设音乐视频点播服务,但都只限于局域网,HUB、交换机可以搞定;但到了出口,对不起,能给个2M的专线已经足够奢侈了,因为要跑路由,要3层隔离,所以必须使用一台路由器,会配会用路由器在当时显得特别牛,CCNA、CCNP、CCIE,也让大家谁都不能忘记一个大名鼎鼎的名字:Cisco!
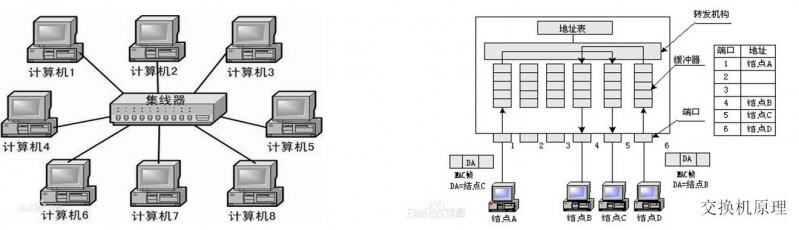
HUB(集线器),主要功能是将本端口收到的报文**到其它所有端口,除此以外基本不具备其它功能;交换机比HUB先进不少,首先交换机是真正意义上的存储转发架构的设备,有了这个架构就可以将报文存储下来,做更智能的事情,比如MAC地址学习、基于MAC学习表项的转发,甚至可以做报文过滤、端口限速等等。由于HUB、交换机主要是ASIC芯片完成,实现较为固化和简单,因此我们一笔带过。

路由器又称**,连接局域网和广域网,根据静态或动态的路由信息,生成转发表,到达路由器的IP报文就可以根据转发表把报文从目的端口发到下一跳。从图中我们大致可以了解路由器在网络中的位置,以及根据应用场合可以分为小型家用路由器和大型的汇聚路由器、骨干网核心路由器。从路由器的功能来看,有两个关键的技术点,一个是路由信息的生成,另一个是报文根据转发表进行转发,报文根据转发表进行转发,不但作用巨大,且挑战的技术难题很多,为了实现高性能大吞吐量,这些年已经发生了翻天覆地的技术革命,没有这些突破,就没有我们今天快乐的享受实时在线的通信和娱乐。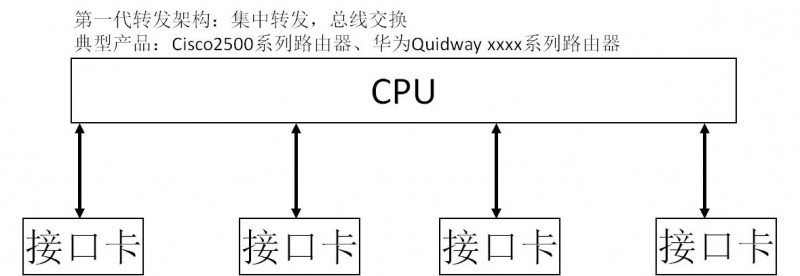
第一代转发架构采用集中式的CPU挂接多个接口卡,接口卡收到的报文通过内部总线送给核心CPU,由CPU上运行的软件对报文进行加工处理,处理完成后从目的端口所在的接口卡上发出去。最早期的路由器甚至就是普通的计算机加多个网卡构成,那个年代的CPU没有太多选择,Motorola的PowerPC系列在通信领域占据着主导地位,在通信产品中是当仁不让的冠军,能用个MPC860逼格已经足够高大上了。20年前的CPU还没有多核多线程概念,运行个多任务操作系统已经伟大的不行了。报文到达接口卡后产生中断给CPU,触发CPU的报文处理程序,直至报文处理结束发送给接口卡,由于单核单线程,控制转发合一,也没有并行处理、保序、pipeline之说,架构相当简单实用,以至于今天看来主频很低、实时性很差的CPU也能够应付当年的带宽需求。

随着网络用户的增多,网络流量不断增大,接口数量、总线带宽和CPU的瓶颈效应越来越突出。如何提高网络接口数量,如何降低CPU、总线的负担?为了解决这个问题,第二代路由器就在网络接口卡上进行一些智能化处理,由于网络用户通常只访问少数几个地方,因此可将少数常用的路由信息采用Cache技术保留在业务接口卡上,使大多数报文直接通过业务板Cache的路由表进行转发,减少对总线和CPU的请求,仅仅对Cache中找不到的报文送交CPU处理。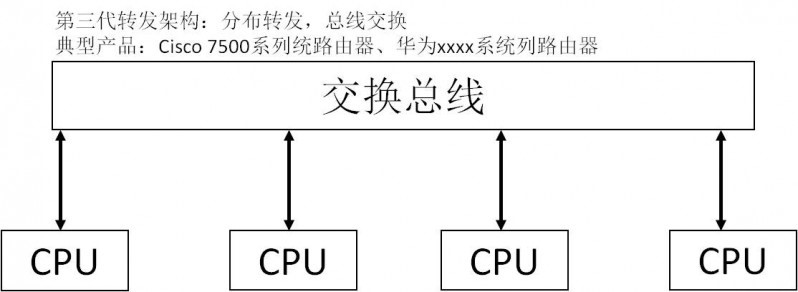
Web的出现使得互联网从黑白世界走向彩色世界,由于用户访问面极大的拓宽,经常无法从Cache找到路由的现象,总线、CPU的瓶颈效应再次出现。且联网计算机的增加(1992年突破100万),路由器接口数量不足问题再次暴露。改革势在必行,第三代路由器采用全分布式结构,路由与转发分离,由主控板负责整个设备的管理和路由的收集、计算功能,并将计算出的转发表下发到各业务板,而各业务板则根据保存的路由转发表独立地进行路由转发。此外,总线技术也得到了较大的发展,通过总线,业务板之间的数据转发完全独立于主控板,实现了并行高速处理,使路由器的处理性能成倍提高。第三代路由器将转发性能提高了数倍,并具备了一个业务灵活扩展、性能不断提升的体系结构,在90年代中期成为Internet骨干主流设备。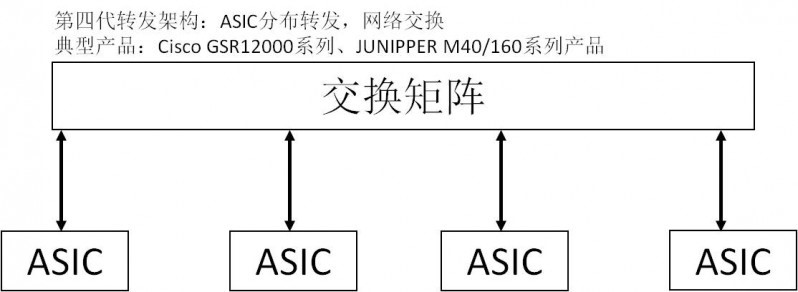
九十年代中后期,随着IP网络的商业化,后Web时代各种新应用如雨后春笋,如著名的QICQ、MSN、流媒体播放,Internet技术得到空前的发展,用户数目迅猛增加,网络流量特别是核心网络的流量以指数级数增长,以往基于软件的IP路由器无法再满足带宽的要求。一些厂商开始引入ASIC实现方式,将转发过程的所有细节全部通过硬件的方式来实现,此外交换网上也持续改进,采用了CrossBar无阻塞交换方式,解决内部交换瓶颈,使路由器的性能达到N个千兆比特,即早期的千兆交换式路由器GSR(Gigabit Switch Router)。
上世纪九十年代这十年是互联网发展奠定基础的十年,用户数、网络规模、全球互联、网络带宽、网络应用已经初具规模,IP也在这个时期干掉了ATM,摇身变为大哥,从此引领世界开拓疆场、走向未来!从我们聚焦的转发技术上看,控制转发分离、分布式交换的最核心技术框架已经形成,为后面在吞吐量、时延、扩展性上的继续突破奠定了坚实的基础。
二、 IP黄金十年
2000年,中国互联网开始向海外上市冲刺,新浪网于4月13日率先出手,网易、搜狐紧跟其后,三大门户网站在几个月内相继登陆纳斯达克,中国互联网业在一片喧嚣浮躁中正式拉开大幕。“中国人离信息高速公路还有多远?向北1500米。”而在大洋彼岸,NASDAQ指数比仅仅一年前翻了一倍还多,只要写个.COM,哪怕是个乞丐一样可以融资千万。是泡沫总归要破的,随后短短6个交易日NASDAQ指数下跌900点,互联网公司全线遭到抛售,恐慌气氛蔓延全球,直到2001年。
泡沫破裂人们回归理性,当坐下来面壁思过的时候,发现过去其实做了很多伪需求,比如一味的投资提升带宽,但却没有跟得上的高价值应用;IP网固有的缺陷,少了严格的QOS保证、网络无法有效管理和运营、IP组网的开放无序、IP地址枯竭、网络的安全等,让人们对IP、对互联网产生了怀疑。理性的不仅有投资者,技术大拿们也从业务、运维、管理、安全的角度重新思考着互联网的未来,需要设计一种新的技术来支撑互联网的理性发展。
2000年的深秋,在美丽的东湖畔,国内某著名研究所的多名博士、专家聚集在一个简陋的会议室,认真的听着来自Level-One公司(Intel于2000年6月宣布并购Level-One)CTO的讲解。讲解的主题是一个神奇的芯片,这款芯片可以帮助客户基于Level-One的解决方案快速开发自己的产品,而这样一款产品一旦上市,将是革命性的的!好吧,不卖官子了,这就是intel网络处理器IXP家族的鼻祖IXP1200。

IXP1200有6个包转发引擎,相当于6个独立的RISC CPU,各自有独立的指令空间和寄存器,但又共享内存和总线;每个转发引擎有4个硬线程,共享指令空间,寄存器有线程独占和共享两种,可以充分发挥并行性,当一个线程进行内存或总线的IO访问从而等待时,切换出去让其它线程执行指令,吞吐量一下子提升4倍(不考虑切换线程的开销和没有完全消除的IO等待时延),总共6个引擎,性能可以达到同规格单核单线程CPU的24倍(理论值)。转发引擎完全可编程,具有2K条汇编指令空间,包转发引擎指令专门为包转发处理进行了特别设计,移位、bit操作、比较、跳转等都是单条指令,效率比通用CPU提升明显。
IXP1200处理RFC1812规定的IPV4标准处理过程时性能可达到1Gbps 64字节以太网报文线速,这在2000年的时候,已经非常非常牛了。国内的华为、中兴就是从这款处理器起步,慢慢的在IP宽带设备上追着巨人思科,直到差距越来越小,并逐渐超越。

网络处理器提升吞吐量的关键是靠流水线处理和并行处理。流水线方式下将对报文的处理分成若干个细微的过程,比如报文接收一个阶段、报文解析一个阶段、报文查找一个阶段、报文修改一个阶段、报文发送一个阶段,这样做的好处是每个阶段的指令总数控制在比较小的值,可以让报文在规定的时间内完成处理,保证线速;另一方面报文处理使用的指令基本上一样,可以简化引擎设计,提升指令执行效率。并行处理的好处就是充分发挥所有处理器所有硬线程的威力,隐藏IO访问时延,做到最大限度的吞吐量提升。今天像EZChip的NPS已经可以做到4K个硬线程,试想想如果我们的马路都有4K个车道,还会天天堵车吗?实际上流水线和并行处理在网络处理器的设计中是常常结合起来的,首先整体上分成流水线,然后在性能瓶颈的模块采用并行处理,这样既满足了吞吐量带宽要求,又满足了复杂业务不降低整体性能的要求。
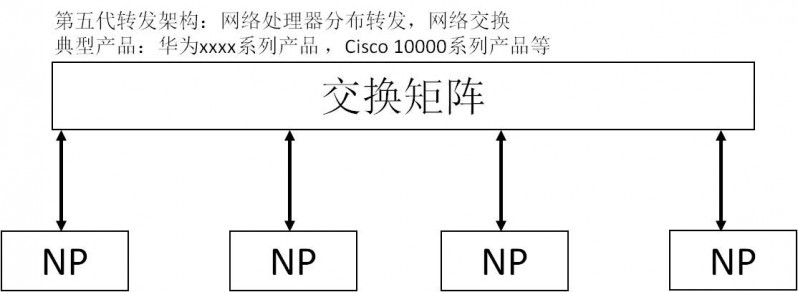
网络处理器的另一个大杀器就是灵活编程,在2000之后的十年中,大量建成的各种VPN网络、MPLS网络、IPV4/IPV6混合网络、精细的流量管理、各种安全**,无一不得益于这种灵活的可编程性;曾经有个时期BT一度让运营商大为烦恼,带宽极度消耗但又不增值,对于这种传输层端口号不固定的应用,如何识别这种数据流并加以限制,灵活的网络处理器发挥了极大的作用。
网络处理器这种既可灵活编程又兼具性能的设计,无疑是这个领域的一颗核弹,其威力无人能及。在新世纪开始的头几年,已经有2.5G/5G处理能力的网络处理器问世,到2005年前后已经有10G的芯片商用。让我们记住这些当年的英雄们:
- Agere(Lucent)APP系列,处理能力2.5Gbps;
- C-Port(Motorola)C-5(16个RISC核,32个串接数据处理器),处理能力5Gbps;
- IBM,Rainer(高端NP,16个RISC处理器核,处理能力4Gbps),Charm(低端);
- Intel,IXP1200(6个引擎,1Gbps)、IXP425、IXP2400(8个引擎,2.5Gbps)、IXP2800(16个引擎,10Gbps);
- MMC,nP3400(2.5Gbps,集成4Gbps交换结构);
- EZchip,NP1、NP2(10Gbps);
- Xelerated,X11(10Gbps)。
网络处理器为产业发展立下了汗马功劳,IXP系列NP广泛应用于宽带BRAS、城域网路由器、RAN传输等多个领域,华为的无线产品正是在IXP的基础上实现了全IP化,让华为的无线产品一举成为世界老二,直追E///;在数通路由器产品中,也大量使用NP芯片,极大的缩短了我们与世界第一的差距。
然而世事难料,网络处理器的好日子并没有持久。Intel无法忍受长期以来的亏损,于2006年6月把IXP卖给了Marvell,2012年Xelerated也卖给了Mavell,其它那些早年的英雄们几乎全部折戟沙场,唯独EZchip凭借着以色列人的聪慧和美国风投的执着,还在挣扎着,也许EZchip的确有过人之处,让我们再多看她两眼吧。
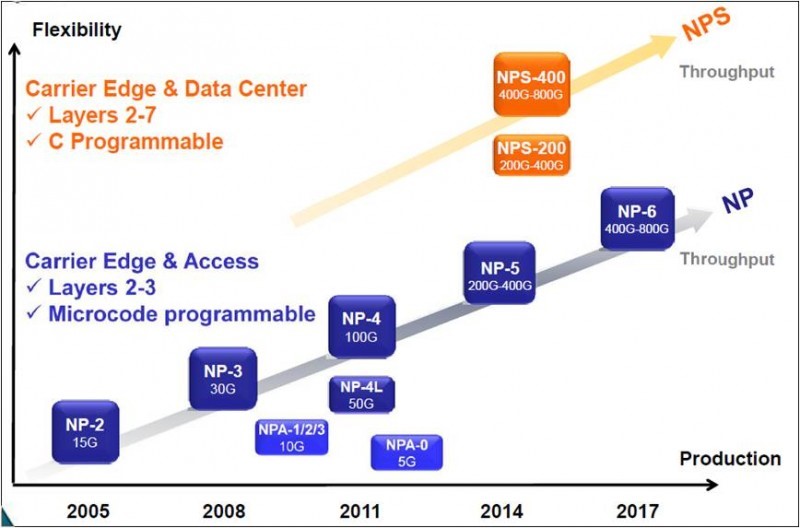
NP的消退肯定不是偶然的,有它必然的因素,首先NP诞生就是一个性能和灵活性折中的产物,这注定了它的性能始终比不过专用ASIC,而灵活性又比不过通用的CPU;其次,NP的开发门槛比较高,本人生平第一次接触的微码,那就是天书,尽管后面都采用了C语言编程,但对开发人员的要求还是相当高,要写出高性能的转发软件,必须对NP做到相当的熟悉;再有,NP转发引擎几乎都是裸跑,不支持OS,一个平台上的代码想移植到另一个平台上,对不起,工作量巨大,而且是不增值的工作。因此NP始终在一个狭窄的领域生长,属于细分市场,造就了大厂商如intel、ibm都不器重,只有小厂家玩,产业链始终不够成熟。NP在这个多彩的世界中扮演了独特的角色,如今已经慢慢褪去光环,作为一代微码工程师尽管有太多不舍,但时代就是在变,后NP时代更加精彩。
MIPS(Million Instructions Per Second),这名字取的就让人叫绝,著名的“龙芯”就是采用MIPS的指令集。MIPS公司设计的RISC处理器始于上世纪八十年代,1991年就推出第一款64位商用微处理器R4000。2000年之后MIPS战略重心放在嵌入式系统,和PowerPC成为通信领域、嵌入式领域两道靓丽的风景线。MIPS相对于X86的CISC,指令格式统一,种类和寻找方式较少,并采用了“超标量和超流水线结构”,大大提高了处理速度,适用于网络通信、信息安全、高端服务器等领域。MIPS被Cavium、RMI两大半导体公司发扬光大,基于MIPS架构开发的商业多核芯片,将网络连接、负责均衡、加/解密、应用加速等功能集成在一个芯片上,即片上系统SoC,并成功应用于通信领域各种场景,包括IP报文转发、加解密、查找等,在高度灵活性和较高性能方面,找到了最佳平衡点。

新一代多核处理器有Cavium的CN68XX、RMI的XLP732/832等,处理能力可达40Gbps,集成8/16/32个MIPS通用CPU内核,内置多个协处理器和加速引擎,提升数据包深层处理的性能。多核处理器和NP最大的不同在于它的CPU是通用的,可以运行vxworks或者Linux,这一点足以让NP汗颜;多核处理器没有NP的指令空间限制,对于包转发处理可以设计成流水线模式,也可以设计成RTC(Run-to-Completion)模式,构建业务的灵活性也是NP无法媲美的;基于Linux的SMP(Symmetric Multi-Processor),开发工作变得异常简单,尤其是移植其它通用平台的代码几乎是分分秒秒的事情。当然多核处理器也可以按照NP那样进行系统架构设计,可以基于裸核进行开发和调度管理,避免Linux系统开销,更大的发挥多核多线程的威力。多核处理器的硬加速协处理对于开发者来说就是一个函数调用而已,比如使用Cavium的加解密协处理器进行报文加解密时,仅仅就是一条普通的指令,程序员完全不需要关心更底层的细节。

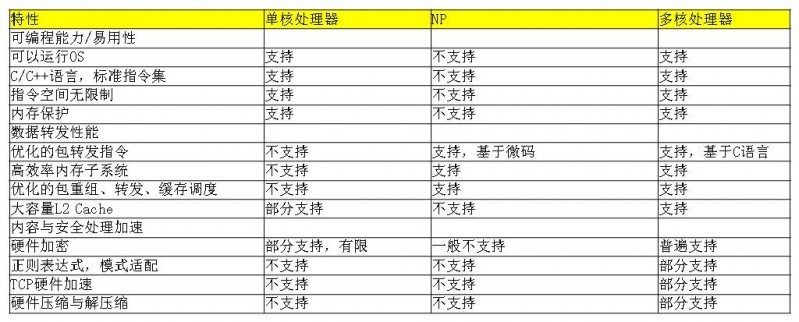
多核处理器一度被认为是完美的处理器,在40Gbps甚至80Gbps以下已经没有NP的什么事了,在安全、业务路由器、L4+报文处理领域完全没有敌手,在华为的无线产品中,单板全部由NP升级换代为多核处理器,为产品的容量提升、性价比提升提供了有力支撑,华为无线销售过百亿美金有多核处理器不可磨灭的功劳。
十年弹指而过,从懵懂初开的NP到枝繁叶茂的多核,IP转发技术经历一次次洗礼,算不上革命,但的确成熟了很多;黄金十年是从固网到移动大发展的十年,是从一味的追求急速带宽增长到IP理性健康发展的十年,是互联网泡沫之后回归的十年;这十年中世界经济大起大落,但互联网健康发展,人类追求的不再是盲目扩张,而是安全、运维、实用,虽然没有大的革命,但一次次的微创新,一次次的小改进,量变成质变,使人类开始享受互联网健康发展带来的可观受益,全民互联网时代也随之呼风唤雨的到来。
三、 继往开来

在美国硅谷心脏地带的101公路旁有一个巨幅广告,只有学习过高等数学的人才能看懂那是一道复杂的数学题。一些好奇的人解开难题,答案是一个网址。登陆网站后,会看到一系列难度递增的数学题,最终,7500人来到了数学迷宫的出口,看到的是谷歌公司的招聘广告。在这个看似游戏的谜题前,能走到最后的人,已经让谷歌甄别了非功利的兴趣,以及兑现这种兴趣的执着和到达目的地的智慧。谷歌用一道道别出心裁的谜题招呼着天下英杰。
进入新世纪第二个十年,全世界最风光的无疑是苹果和谷歌两家公司,在雅虎关闭邮箱服务、诺基亚手机宣布死亡、IBM转售服务器PC业务之际,这两家公司却让全世界为他们打工,过着皇帝般的日子。从搜索引擎到谷歌地图,从android系统到谷歌眼镜,从无人驾驶到热气球计划,谷歌每天都在吸引着全世界的眼球,它的创新无疑超越了其他所有人。

谷歌成功的背后是凝聚着先进技术的的基础设施、遍布全球的数据中心、数以万计的计算节点、存储节点、网络节点。2010年的时候投入运营的数据中心已经有36个,遍布美国、欧洲以及亚洲,最近几年在台湾、马来西亚、新加坡、印度以及美国本土都有新的数据中心投资建设。每个数据中心的规模至少都数十万台服务器上千台交换机,一个大型数据中心就相当于八十年整个Internet的规模。谷歌要保证分布在全球的数据中心之间高速互联,从用户使用谷歌服务的角度上不区分节点的物理位置。为了实现不同地域数据中心之间数据的同步、灾备,需要极大的广域网带宽,而这恰恰是最花钱的地方;网络流量有高峰和低谷,高峰流量可达平均流量的2~3倍,广域网带宽利用率只有30~40%,所以尽管谷歌自建了大量的光纤传输,但流量带宽的巨大浪费仍旧让谷歌心痛。

谷歌的工程师们观察到数据中心中的流量具有不同优先级:
- 用户数据拷贝到远程数据中心,以保证数据可用性和持久性,这个数据量最小,对延迟最敏感,优先级最高;
- 远程存储访问进行 MapReduce 之类的分布式计算;
- 大规模数据同步,以同步多个数据中心之间的状态,这个流量最大,对延迟不敏感,优先级最低。
- 谷歌发现高优先级流量仅占总流量的10%~15%,只要能区分出高优先级和低优先级流量,保证高优先级流量以低延迟到达,让低优先级流量把空余流量挤满,数据中心的广域网连接(WAN link)就能达到接近100%的利用率。要做到这个,需要几方面的配合:
- 应用(Application)需要提前预估所需要的带宽,由于数据中心是谷歌自家的,各种服务所需的带宽都可以预估出来;
- 低优先级应用需要容忍高延迟和丢包,并根据可用带宽自适应发送速度;
- 需要一个中心控制系统来分配带宽。
就这样,谷歌引入了Software Defined Networking (SDN)/OpenFlow,SDN把分散自主的路由控制集中起来,OpenFlow交换机按照Controller指定的规则对packet进行匹配,并执行相应动作。这样,Controller 就可以利用整个网络的拓扑信息和来自application的需求信息计算出一组接近全局最优的路由规则。谷歌已经看到该网络带来的一些好处包括:网络带宽利用率大大提高(谷歌宣称平均带宽利用率可达95%),网络更稳定,管理简化了,Cost降低了。
关于谷歌的数据中心,谷歌关于SDN的优秀实践,可以上度娘和谷歌进行查找和学习,下面我们再聚焦到SDN/OpenFlow上来。
IP网络经过几十年的发展,尤其是刚刚过去的健康理性发展的黄金十年,似乎已经完美了,这个时候有人又坐不住了,心里痒痒想对IP进行革命,他们就是斯坦福大学的一帮老鸟。让我们先回顾下SDN发展大事记:
- 2006年,SDN诞生于美国GENI项目资助的斯坦福大学Clean Slate课题,斯坦福大学Nick McKeown教授为首的研究团队提出了Openflow的概念用于校园网络的试验创新,后续基于Openflow给网络带来可编程的特性,SDN的概念应运而生。Clean Slate项目的最终目的是要重新发明英特网,旨在改变设计已略显不合时宜,且难以进化发展的现有网络基础架构
。 - 2008年Nick McKeown提出OpenFlow的概念,发表《OpenFlow: Enabling Innovation in Campus Networks》,详细介绍了OpenFlow概念。2009年SDN概念入围Technology Review年度十大前沿技术,获得了学术界和工业界的广泛认可和大力支持。
- 2009年12月,OpenFlow规范发布1.0版本,随后经历了1.1、1.2、1.3以及1.4版本。
- 2011年3月开放网络基金会ONF成立,致力于推动SDN架构、技术的规范和发展工作。ONF成员96家,其中创建该组织的核心会员有7家,分别是Google、Facebook、NTT、、Verizon、德国电信、微软、雅虎。
- 2012年4月,ONF发布了SDN***(Software Defined Networking:The New Norm for Networks),其中的SDN三层模型获得了业界广泛认同。
- 2012年4月,谷歌宣布其主干网络已经全面运行在OpenFlow上,并且通过10G网络链接分布在全球各地的12个数据中心,使广域线路的利用率从30%提升到接近饱和。
- 2012年7月SDN先驱Nicira以12.6亿被VMware收购。
- 2012年底,AT&T、英国电信(BT)、德国电信、Orange、意大利电信、西班牙电信公司和Verizon联合发起成立了网络功能虚拟化产业联盟(Network Functions Virtualisation,NFV),旨在将SDN的理念引入电信业。由52家网络运营商、电信设备供应商、IT设备供应商以及技术供应商组建。
- 2013年4月,思科和IBM联合微软、Big Switch、博科、思杰、戴尔、爱立信、富士通、英特尔、瞻博网络、NEC、惠普、红帽和VMware等发起成立了Open Daylight,与LINUX基金会合作,开发SDN控制器、南向/北向API等软件,旨在打破大厂商对网络硬件的垄断,驱动网络技术创新力,使网络管理更容易、更廉价。
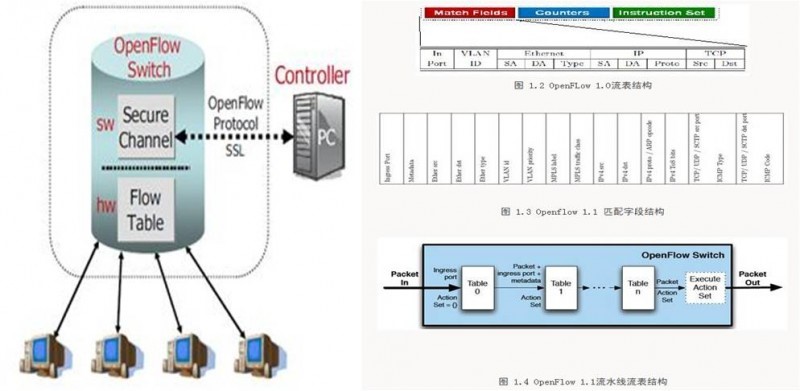
将原来网络设备盒子中的控制分离出来集中到Controller,以及基于流表的交换机取代原来各种路由器交换设备,是SDN/OpenFlow最核心的两个点。
OpenFlow提出的最初出发点是用于校园内网络研究人员实验其创新网络架构、协议,考虑到实际的网络创新思想需要在实际网络上才能更好地验证,而研究人员又无法修改在网的网络设备,故而提出了OpenFlow的控制转发分离架构,将控制逻辑从网络设备盒子中引出来,研究者可以对其进行任意的编程从而实现新型的网络协议、拓扑架构而无需改动网络设备本身。至于集中控制代替原来的分散控制全网(或局部)协调,是否一定有优势?至今也没有明确的结论,不过凭经验,应该是每种方案都适合特定的场合,最终可能是两种共存,看怎么融合了。
OpenFlow交换机的思路很简单,网络设备维护一个FlowTable并且只按照FlowTable进行转发,FlowTable本身的生成、维护、下发完全由外置的Controller来实现,注意这里的FlowTable并非是指IP五元组,事实上OpenFlow 1.0定义的了包括端口号、VLAN、L2/L3/L4信息的10个关键字,但是每个字段都是可以通配的,网络的运营商可以决定使用何种粒度的流,比如运营商只需要根据目的IP进行路由,那么流表中就可以只有目的IP字段是有效的,其它全为通配。这种控制和转发分离的架构对于L2交换设备而言,意味着MAC地址的学习由Controller来实现,V-LAN和基本的L3路由配置也由Controller下发给交换机。对于L3设备,各类IGP/EGP路由运行在Controller之上,Controller根据需要下发给相应的路由器。流表的下发可以是主动的,也可以是被动的,主动模式下,Controller将自己收集的流表信息主动下发给网络设备,随后网络设备可以直接根据流表进行转发;被动模式是指网络设备收到一个报文没有匹配的FlowTable记录时,将该报文转发给Controller,由后者进行决策该如何转发,并下发相应的流表。被动模式的好处是网络设备无需维护全部的流表,只有当实际的流量产生时才向Controller获取流表记录并存储,当老化定时器超时后可以删除相应的流表,故可以大大节省TCAM空间。OpenFlow 1.0的流表分为Match Fields、计数器和指令集三个部分,Match Fields是报文匹配的输入关键字,计数器是管理所需,指令集是决定报文如何转发,最基本的转发行为包括转发给某个端口、封装改写报文后转发以及丢弃。OpenFlow 1.1增加了对MPLS以及UDP/SCTP传输层协议的支持,同时针对流表开销过大的情况设计了多级流表,并增加分组策略功能。
OpenFlow标准最大的好处是将数据面的交换机行为进行了统一,如果推动整个产业链的话,硬件成本将大幅下降。但问题是,这一过程将异常的艰难,先不谈利益既得者会想尽一切办法阻止这一进程外,单从技术上看也是困难重重。
首先是路由器/交换机中广为使用的快速查找TCAM 存储器成本的问题。在传统设备中,需要采用TCAM的表包括FIB、MAC、MPLS Lable和ACL表,每个表的匹配字段长度不一,分开设计,并且设计了最大容量,以期达到最小的开销。而在OpenFlow设备中,不再区分匹配长度短的FIB、MAC、MPLS Lable表以及较长的ACL表,一律采用最大长度的FlowTable记录代替,对于OpenFlow1.0而言,FlowTable的匹配字段长度长达252比特,而一般IPV4 RIB TCAM匹配字段长度只有60-80个比特,开销增加了3倍以上,而对于路由器的线卡而言,TCAM成本占了约20-30%,功耗也占了很大一部分。因此如何减少FlowTable尺寸将是OpenFlow体系面临的一个极大问题,此外,TCAM体系下FlowTable记录的动态插入算法将更为复杂。
OpenFlow1.1设计了多级流表来减少Flowtable的开销,将流表进行特征提取,分解成多个步骤,形成流水线处理形式,从而降低总的流表记录条数,比如原始流表共有10000条,分解成先匹配VLAN+MAC,再匹配IP和传输层头部的两个独立流表,每个流表的数量可能均小于1000条,使得流表总数小于2000条。但流水线式架构使得匹配时延增加,在软件实现的转发模型中整体吞吐量必然下降;而且流量的生成、维护算法复杂度提高,至今也未见到针对真实网络的效果评估报告。
OpenFlow的关键是通过OpenFlow将网络转发的原子操作抽象出来,并以流表来驱动转发处理流程,我们所论述的一切好处是建立在OpenFlow FlowTable能够很好地将Primitive和WorkFlow抽象,支持设计新的协议在大部分情况下的确可以通过只修改Controller的逻辑来实现这一假定上。在OpenFlow最初应用的Switch领域,OpenFlow已经有杀鸡用牛刀的嫌疑。但是路由网络,尤其是包含有大量用户控制逻辑的边界路由器,如BRAS、无线网络的GGSN/PDSN/xGW等设备,OpenFlow需要扩展将用户控制逻辑抽象为原子操作和流程,那可能已经不适合叫FlowTable,叫AccessControlTable更合适,转发操作本身的匹配规则、转发操作中也需要增加对现存的各种接入协议和表征接入会话的协议字段的支持,比如PPPoE、GTP-U、PDP激活操作的匹配和转发封装支持。
关于OpenFlow的深入分析,请参考盛科网络张卫锋《深度解析SDN》。
SDN无疑是最近几年最热门的话题之一,但我们要讲的是转发技术的“继往开来”,只有SDN、OpenFlow显然不够,因为业界正在悄悄的发生着革命,ICT正在融合,一种新形式的网络设备正在逐步问世,这就是NFV(网络功能虚拟化)。
NFV,即网络功能虚拟化,Network Function Virtualization。通过使用x86等通用硬件以及虚拟化技术,来承载传统的网元功能。通过基于行业标准的x86服务器、存储和交换设备,来取代通信网的那些私有专用的网元设备。由此带来的好处是,一方面基于x86标准的IT设备成本低廉,能够为运营商节省巨大的投资成本,另一方面开放的API接口,也能帮助运营商获得更多、更灵活的网络能力。可以通过软硬件解耦及功能抽象,使网络设备功能不再依赖于专用硬件,资源可以充分灵活共享,实现新业务的快速开发和部署,并基于实际业务需求进行自动部署、弹性伸缩、故障隔离和自愈等。
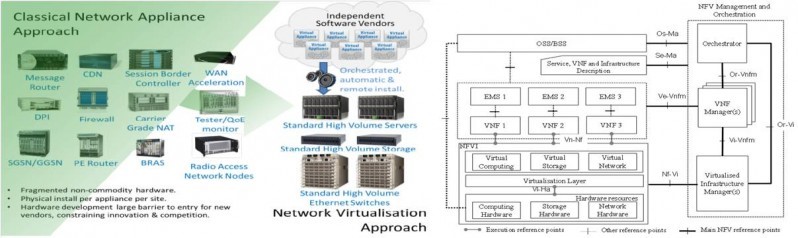
那么问题来了,NFV里面没有了专为数据包转发优化设计的NP、ASIC,甚至多核处理器都不行,转发怎么办?x86搞的定吗?
1995年Intel推出第一款PC服务器和工作站专用处理器Pentium Pro,自此之后的二十年中,处理器从16位到32位再到64位,从单核到双核、四核、到今天的十核,从150MHz到3GHz以上主频,从X86架构到IA64架构,从奔腾时代到崭新的酷睿、志强时代,从Nehalem到haswell,从Intel inside到Leap ahead,摩尔定律、Tick-Tock,不断增强的虚拟化技术,让我们领略到了英特尔领导服务器处理器发展潮流的雄姿与伟略,在英特尔“偏执”推动下,全球计算技术也在不断进步着。正是由于基于x86的服务器价格不断下降、性能不断提升,才有了今天CT巨头们有勇气提出的NFV架构。
当x86在服务器市场一路高歌猛进的时候,Intel意识到只有强大的计算并不是万能的,linux内核提供的socket收发包无法提供10Gbps的速率,当IO接口吞吐量不够时,CPU强大的性能只能浪费掉,好马必须配好鞍;为此Intel设计开发并为所有用户免费开放了DPDK(Data Plane Development Kit),配合Intel的高速网卡和IO虚拟化技术,解决了x86服务器这些年来最让人诟病的IO性能问题,NFV也因此有胆量抛弃所有的非标准(非x86cpu、非intel网卡或不支持IO虚拟化的网卡)组件,从网络IO到计算CPU,Intel帝国从此诞生,可喜、可敬、可恨,也可怕!
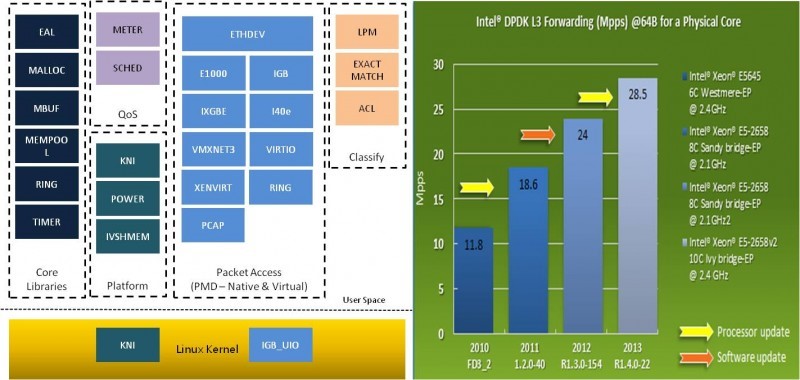
DPDK提供了一系列用于报文处理的库函数和驱动,运行在linux用户态,理论上可以运行在任何处理器上,当然目前都是在x86的cpu。DPDK提供的L3转发模型在intel最新的CPU上可以达到28Mpps/core性能,比linux内核态IO性能提升几十倍。
DPDK包括的技术有:
- PMD轮询收发包机制,抛弃中断采用轮询模式减少系统开销;
- 报文批量处理,提升吞吐量减少轮询开销;
- 线程绑定的RTC模式,最大限度提升CPU利用率;
- 网卡硬件分流技术,报文天然保序;
- 无锁设计;
- 优化的BUF、RING;
- 报文预取,提升cache命中率;
- DDIO技术;
- 内存大页技术;
- 虚拟化场景下硬件直通SR-IOV、passthrough;
- SSE、AVX矢量处理。
DPDK相对于以前的NP和多核处理器,在报文处理上并没有过人之处,反倒是它的这些技术是为了解决x86的短板而逼出来的;在多核处理器上已成为标配的协处理器、以及NP的数以百计甚至千记的硬线程数目,x86都还无法招架;x86相对较少的线程数直接影响处理的并行度,cache机制对性能影响巨大,在流表规格大于L3cache后性能直接腰斩,等等,x86在转发领域的确不够完美。但是,在硬件通用化、虚拟化大行其道的今天,DPDK的地位已经无法撼动,NFV已经明确要把DPDK加速纳入标准体系,所有的x86平台上只要跟IP相关,都逃不脱DPDK的绑架。NP已经被逼到只能和ASIC竞争高端路由交换市场,多核处理器也只能自降身份,沦为x86的配角,在智能网卡领地求得一丝喘息。
新世纪第二个十年刚刚过半,在IP技术沉寂了若干年后,有点革命意思的NFV、SDN的出现,让技术弄潮们一度欢欣鼓舞;转发技术能否迎来革命,目前还不明朗,但大潮已不可阻挡,尽管还有这样那样的不成熟,尽管各种反对的力量此起彼伏,虽然技术最后没有定型,改进依然在进行,标准也还在制定中,但我们有理由相信,未来几年,在5G、物联网到来的时候,NFV、SDN必将是主流的,届时,ICT完全融合,云计算承载一切,大数据主导一切,互联网将迎来二次革命。
四、 结束语

“今天的世界充满无数惊喜进步,蕴藏无限神奇可能。很多人已受益于此,但仍有人与此无缘。华为认为,人类的真正进步,在于以创新成果普济天下。我们认为沟通互联并非专属特权,而是人人必需。我们相信,衡量信息通讯科技的影响,要看有多少人因其受惠。我们不断将宽带技术推向更高标准、更快速度,让它无处不至、无人不享。联接,就像空气和水一样,它终将融入到我们生活的每一个角落,无所不在。”
在2015年新年致辞中,华为轮值CEO**厚崑说:“我们预测,到2025年,全球将有超过1000亿的联接,这将是一个规模空前的市场,如何存储和处理、传送与分发、获取与呈现这些庞大的数据流量,既是一个巨大的挑战,也是我们面临的战略机遇。”
其微信公众号“大侠来了”已发布,有意者可交流讨论