没有GPU仅用CPU也可以玩转AI?英特尔openVINO工具套件课程总结
 openlab_4276841a
更新于 4年前
openlab_4276841a
更新于 4年前
首先介绍一下这个课程,也是我最近发现的一个好课。直接交你如何在自己电脑上跑视觉模型,仅仅用一块CPU,不用GPU,也不同任何的硬件加速就可以实现一些很好的模型。
下面是课程的链接,我觉得他们讲的非常清晰,如果我写的地方有不清楚的部分可以看一下他们的那个课程,全免费的:
http://edu.csdn.net/course/detail/27685?utm_source=coderacademy
基础视觉图像知识
首先呀我们必须明确一点,就是图片是它是什么呀?图片其实是一个像素,一个图片有很多的像素组成,就好像细胞一样,密密麻麻地排在一起。像素都是正方形的,像下面的这个图片中所示的一样,然后每个像素都有自己的属性。
我们可以看一下这个黑白的图片,每个像素(小正方形)他们的黑白程度是不一样的,有的很白,有的很黑,黑白的程度不相同,就可以直接把整张图形表现出来。

那我们平时的彩色图像又是怎么一回事呢?一般自然界可以说是RGB红绿蓝三色组成的,三种色的大小叠加可以生成下图圆形中的所有颜色,然后我们的像素,每个像素都是一种颜色,用RGB三色来生成。这样子就构成了彩色的图片组成,我们玩机器视觉就是建立在对这些像素的操作识别上的。

好,我们来看下这个滑板的边缘部分,你看每个像素的三色值的加权和是不是和边界很不一样,你看都是差了一百多,这样子我们就可以检测了滑板的边界。

在机器视觉CV中,最基础的一个软件库就是opencv了,甚至我们都把视觉叫CV哈哈。如果你使用OPENVINO其实就不用担心下载的问题,这个库已经集成在了VINO里面了。

好,上面讲了一张图片的组成,接下来我们讲一下视频的组成。视频的组成其实就是一张一张图片连续闪过你的眼前,利用你的视觉暂留效果就可以让你看起来图片好像会动一样。
但是这个很占空间,我们跟着下面来算下,一个画面有1920*1080个像素,每个像素又有三个值所以得乘上三倍,然后一面可以闪过25张图片,一分钟60秒,也就是闪过了1500张图片。
也就是说一分钟就有9.3G的内存。什么概念?你的手机一般最好的也就是256G吧,也就半个小时就可以把你手机填满。
所以不能一张一张图片地传,采用压缩技术就变得很有必要了,压缩后才是71MB

图片压缩技术有两种最常见的形式,第一种是你可以看到是天空中那一种,它的整体的颜色是没有太大变化的,所以我们就只用几个小像素去表示,在一段时间内,这个天空的颜色都是蓝色的。这样子一来,你就可以大大的减少像素的数量。

另一种的就是图片的像素会在视频当中出现比较多的变化,但是我们也不会把所有的变化都用一张一张图片连起来,为这样子的话整体的内存占用的像素会比较高。
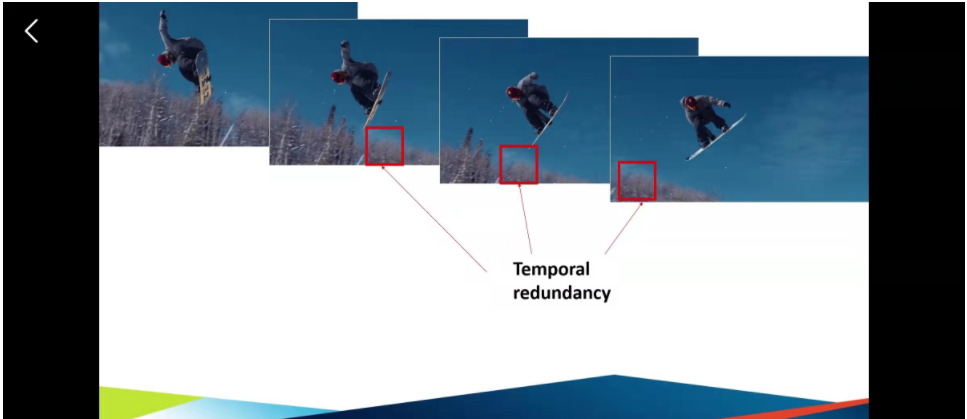
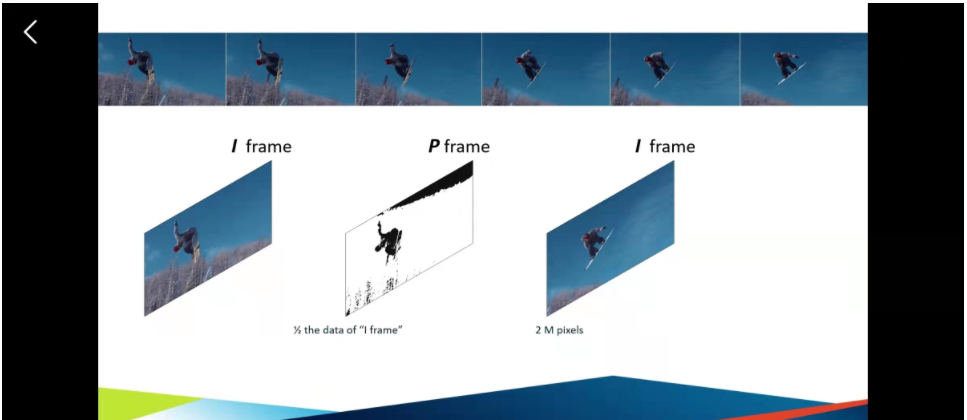
我们会采用抽样的形式,比如说两张图片,可以看出,比较明显的变化时,我们就抽取这两张图片,中间再补充一张图片。这样子,两端抽取的图片叫做I frame ,中间再补充一个中间值的图片,我们称为P frame
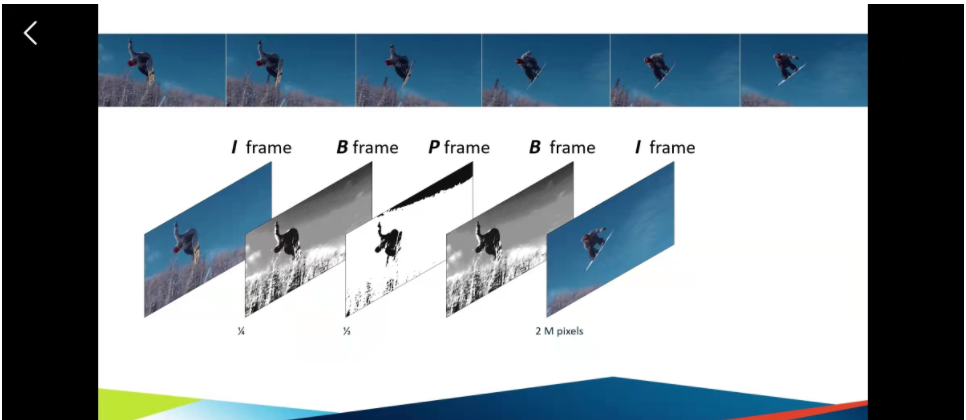
为了更加的精确,然后我们会在中间只跟两端之间再进行一次抽取,然后就称这一个抽取为B frame
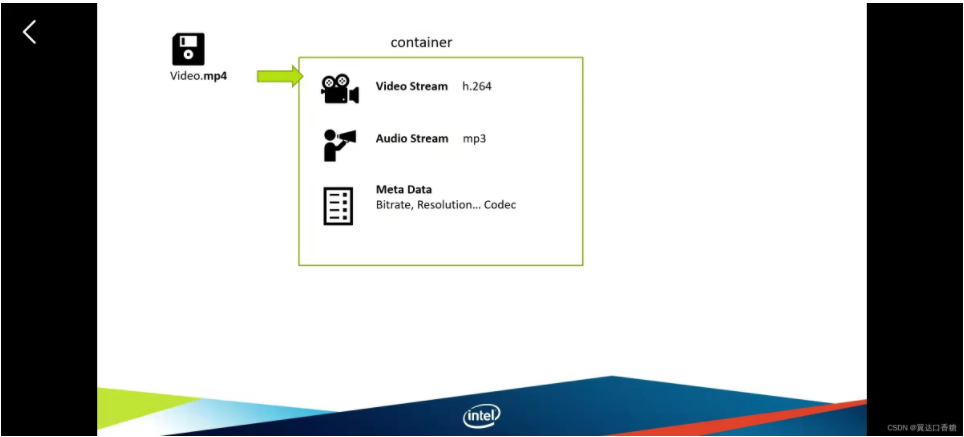
所以一个MP4视频的话,它是由好几部分组成的,分别是MP3对视频的解码压缩、视频的大小长度,清晰度等等视频信息组成的。
基础神经网络
现在我们来谈一下基础的神经网络。首先的话,我们要从一张图片中去识别一个小猫。然后一个小猫有比如说有四个特征,首先,小猫是有四条腿,然后是有尾巴,然后是有颜色的毛,然后大小呢,他不算是很大。然后呢,我们把有这四个特征的动物就可以把他判断为它是一只小猫。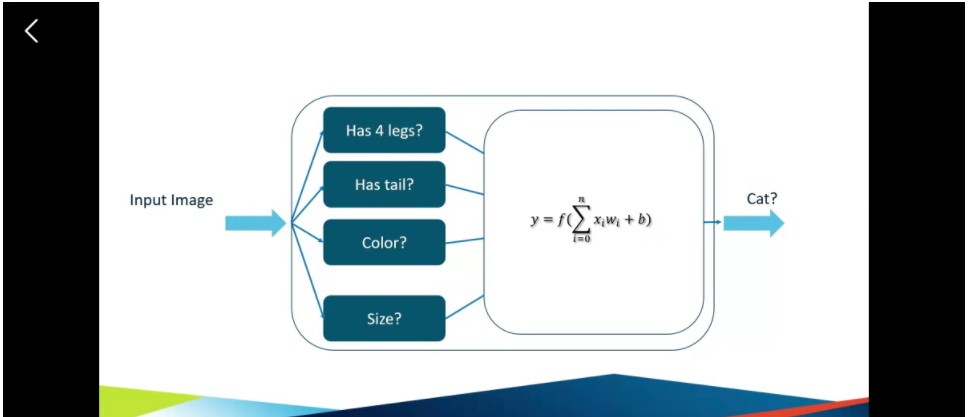
但是四条腿的时候就一定是小猫吗?其实不然,很多动物都有四条腿,所以都有可能是小猫。所以四条腿在判断的时候是有一个权重的,我们称它为w1,也就是计算时候的系数。
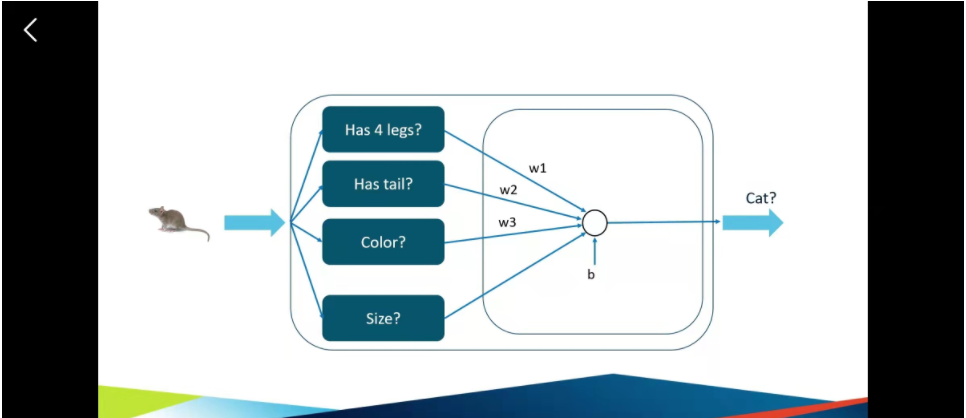
这样子,我们根据前面的四个特征,就可以将它们传递到下一个节点。这个就是单层的神经网络,然后在前面加入了多个隐藏层,就组成了一个简单的神经网络。
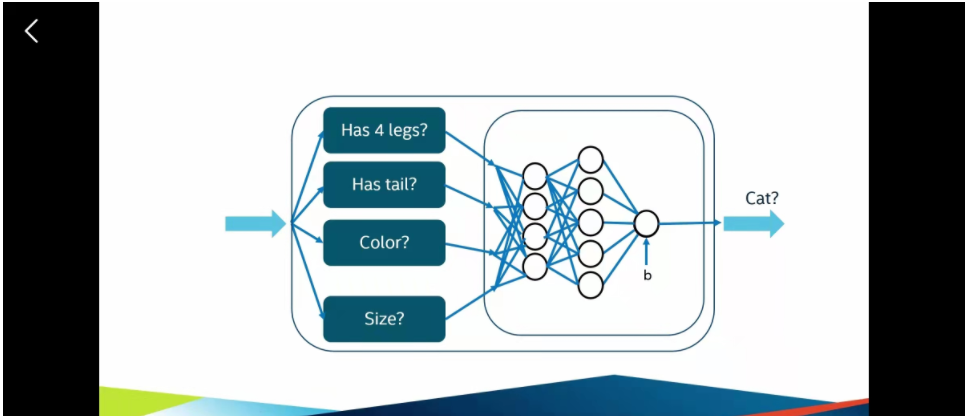
通过这个网络,我们就可以去识别照片中的小动物,是不是一个小猫
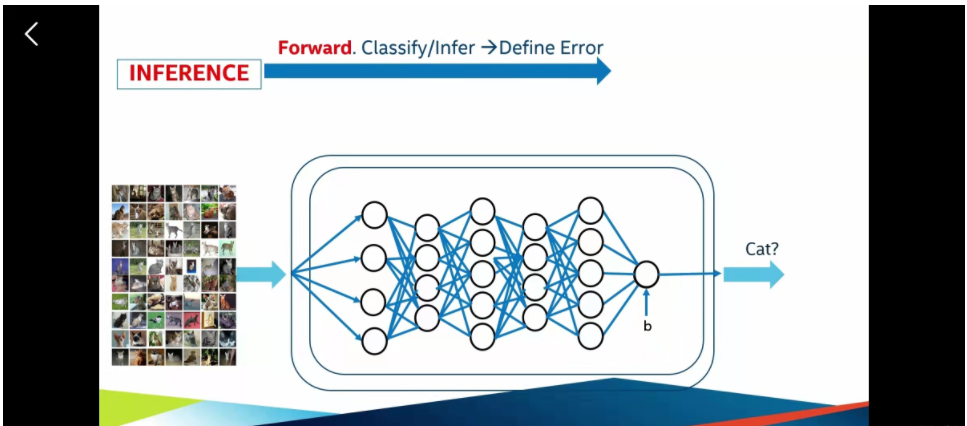
神经网络典型的一个是resnet 50,他是有50多个隐藏层,所以会带来非常复杂的运算,这也就是为什么需要通过硬件来进行加速。

DLDT深度学习推理套件
这是一个深度学习的核心套件。

我们把训练好的模型然后转化成中间表示(IR)、然后推理引擎就可以把他们在多个硬件设备上使用。看下下图。
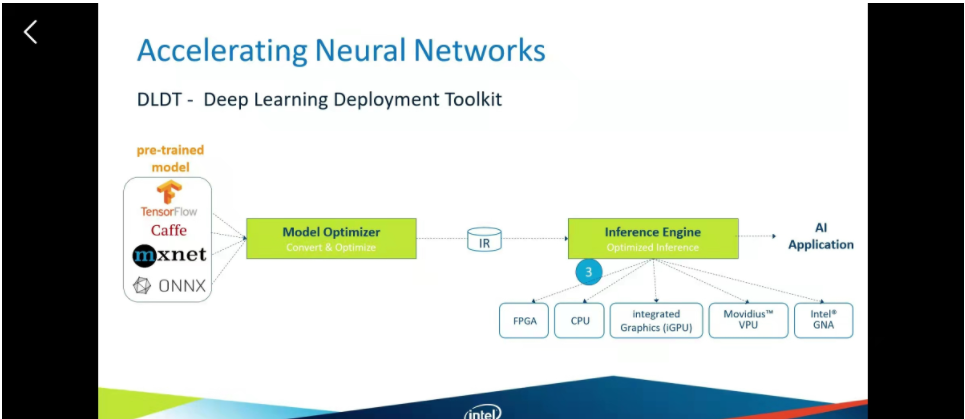
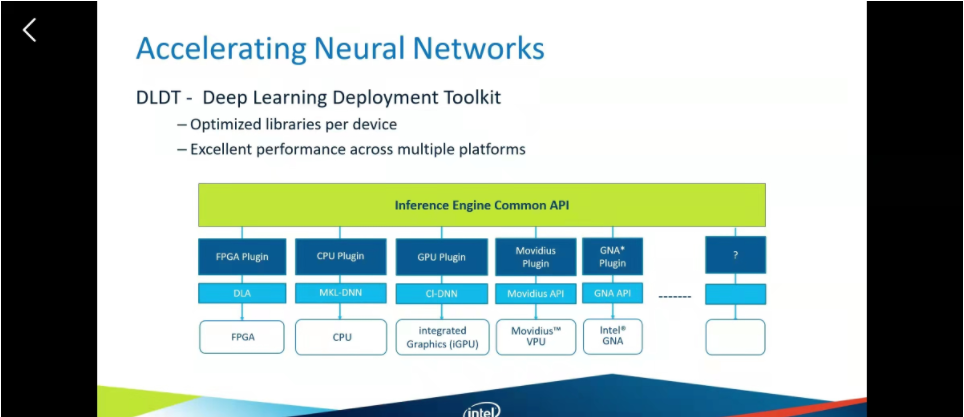
openVINO整体框架
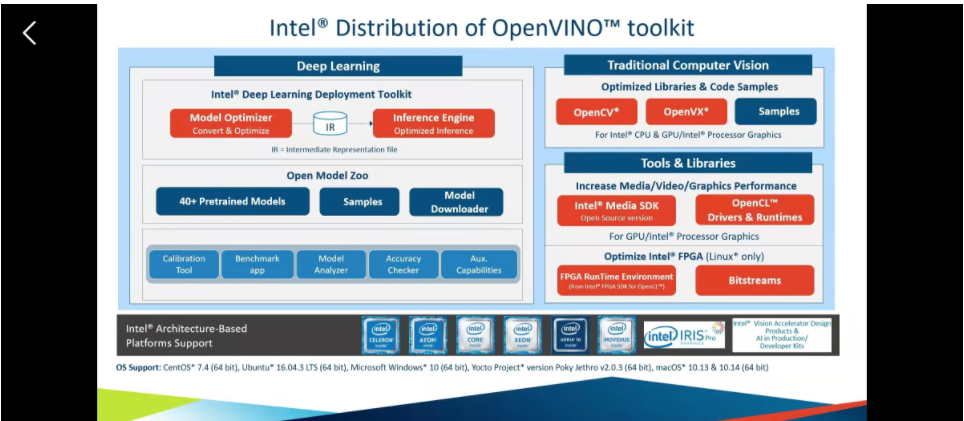
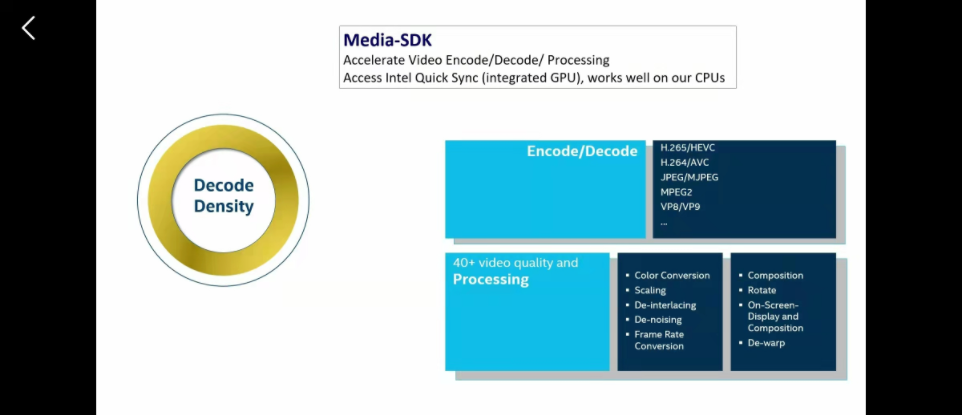
openVINO支持所有的主流系统,像win、Linux、OS都没问题。主要分成三个部分,第一个部分支持opencv 处理计算机视觉包括CPU、GPU,第二个支持media SDK进行视频解码、编码与处理。第三个是使用深度学习部署套件DLDT进行推理。
视频分析工作流程
视频流程分析主要是包括五步对视频流进行目标识别、跟踪、分割等等。
第一个是解码,实际上系统使用的格式都是压缩的,所以要先对这些视频进行解压。

一般来说,工业上或者视频监控大概率会有十几个视频流,每个视频流都有不同的分辨率和格式,来源各不相同。所以这个是我们想要做一个与处理,就是对图像进行锐化、图像变化、裁剪图像中我们感兴趣的区域等来处理。

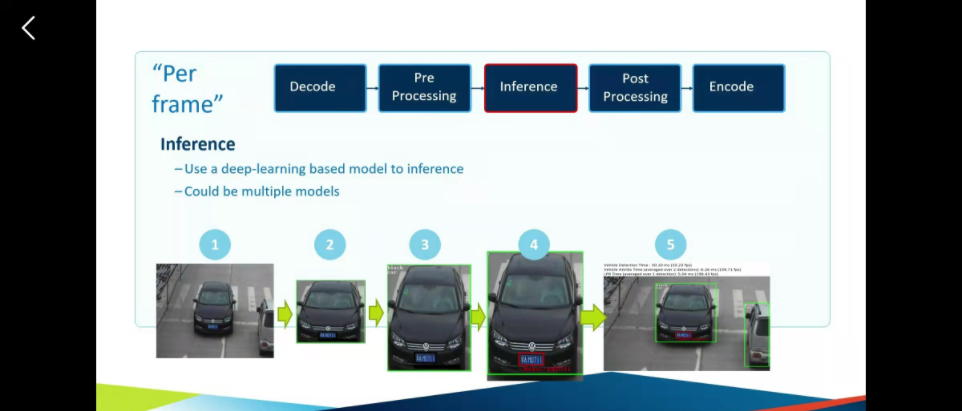
这个阶段就是最核心的推理阶段,可以进行多次模型调用组合。

比如这个,
1、从摄像头获取图像
2、对图像分类和检测,查一下有没有车
3、用另一个模型查一下车子的颜***r>4、定位车牌
5、甚至OCR去读区车牌的数字

这里提下跟踪,这里说我们要跟踪一个车子,我们就 不需要对图像进行反复检测。
我们来看下反复提到这三个工具:media-SDK、openCV、DLDT,CV最能打,几乎五个步骤都可以执行,DLDT主要负责深度推理的中间部分,SDK主要负责视频的编解码。

在有gpu辅助的条件下,可以同时对11路的视频中的人脸同时进行识别

接下来我们看个模型套用的例子。一个模型的结果作为另一个模型的输入。
首先,我们会对所有的行人的流量进行统计,就是第一个模型,对人流的检测。

然后可以看到我们现实中想要的一个特殊的对象是穿黄色衣服的那位行人,或者是做出一些危险行为的顾客,我们就可以给他标红,这是第二个模型。


第三个模型,我们可以把所有人的行动轨迹标注出来,这就是一个多模型融合叠加的一个例子。

英特尔视频分析的软件工具
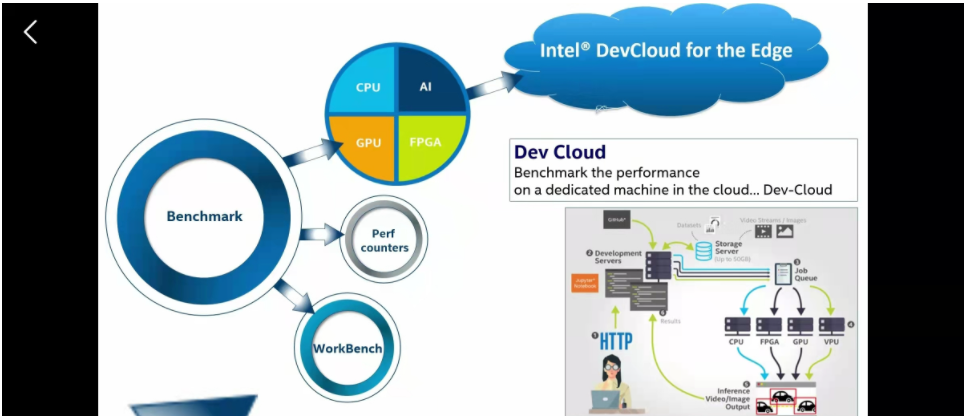
openVINO有一个完整的生态,这些小圆就是开发的全流程。从模型构建到落地。1、构建一个模型(检测、追踪、切割),一般都是在另一个模型去训练,比如说TF、caffe、这里主要推荐国产的PP(飞桨),后面我做的项目都是在PP建立的。
2、prepare inference为推理做好准确,做一些格式转换
3、benchmark-性能指标评测,看看能不能达到我们的要求平台
4、decode density有时候多路视频解码,要看自己硬件够不够用
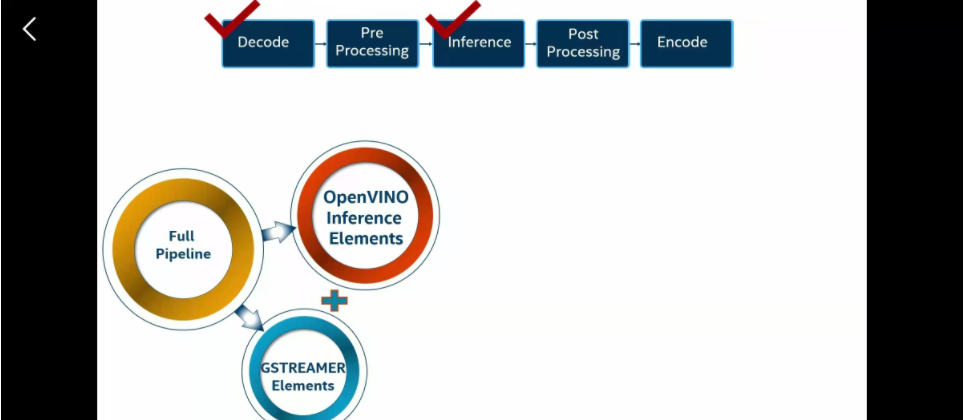
5、然后full pipeline-把整个过程链接起来运行,看看解码和推理能不能跟的上。比如说解码一秒20FPS,然后推理一秒30FPS就只有20FPS以下了。
6、最后系统成型后把模型整合到现有的模型中。
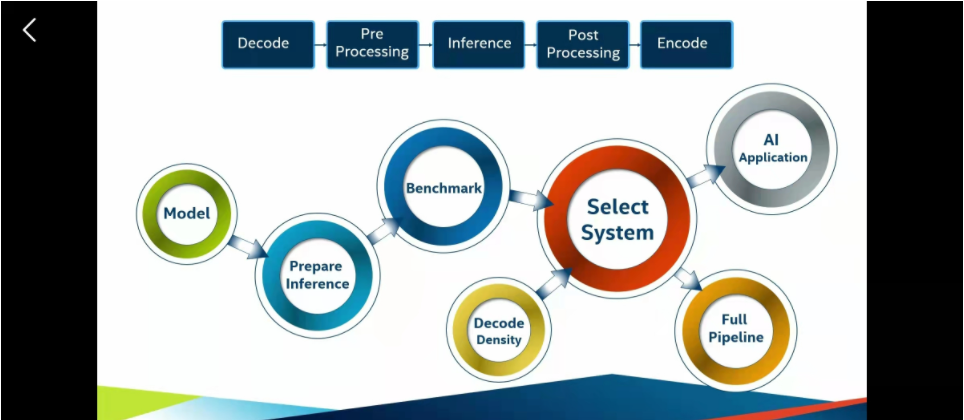
选择合适的系统(select system)
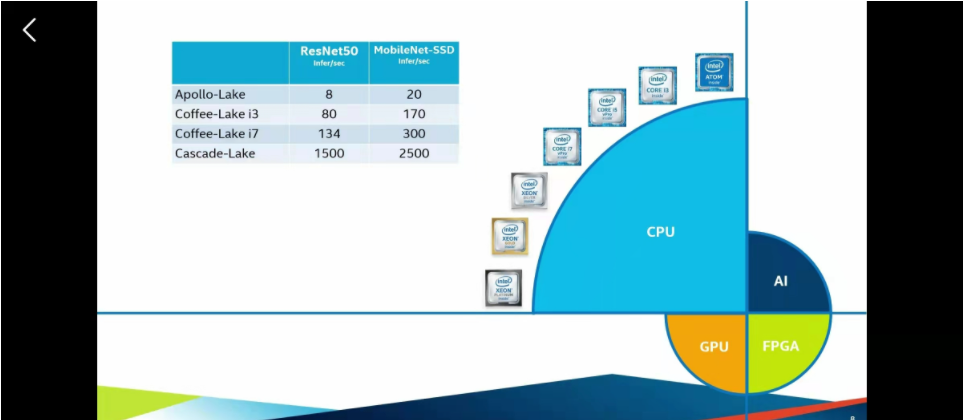
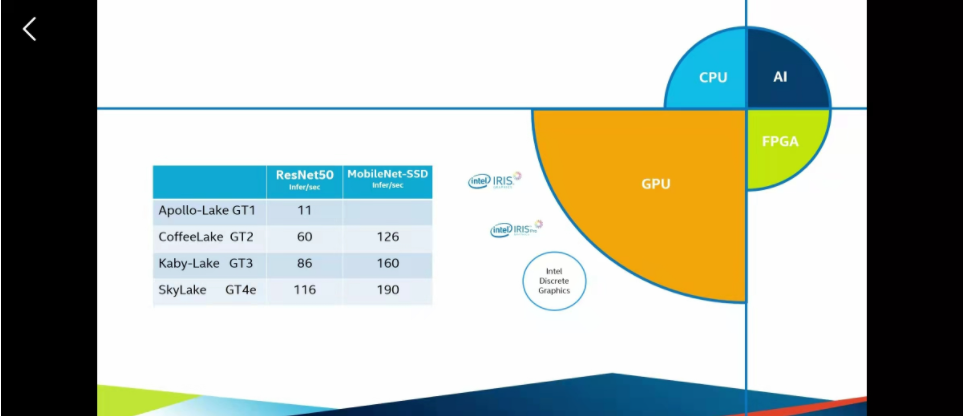
openVINO图像处理在X86架构下的硬件条件下展示出了非常强大的性能,几乎可以在所有的PC电脑上用起来,(包括苹果的电脑)。这里是英特尔自家产品的一些介绍,主要分为CPU、GPU、FPGA、AI加速(计算棒这些)这些硬件可以异构计算,也可以单独拿出来用。具体来说就看自己的经济条件和需求,去买不同的一些硬件产品,下面四张图是四类的相关参数。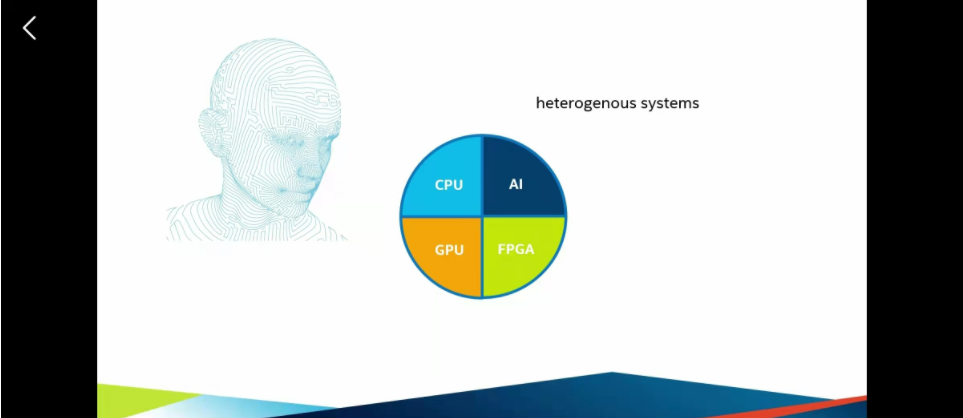
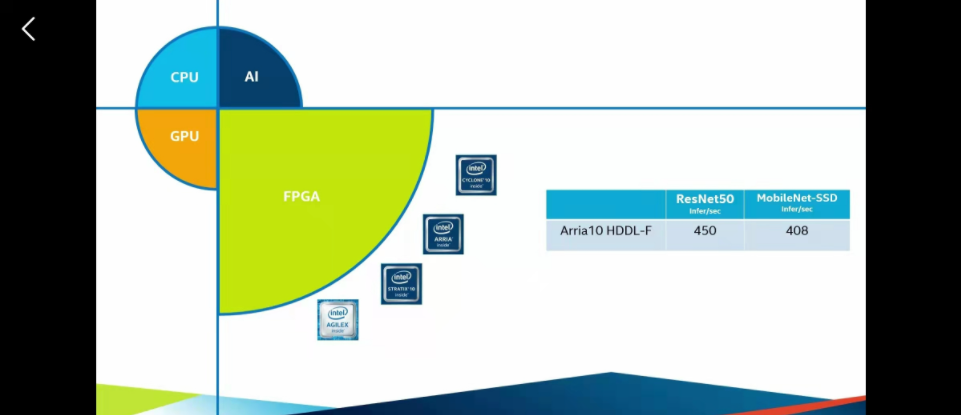
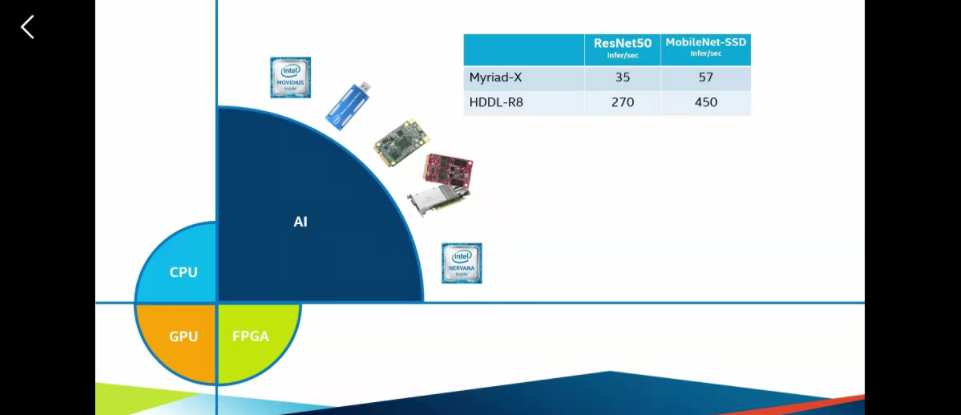
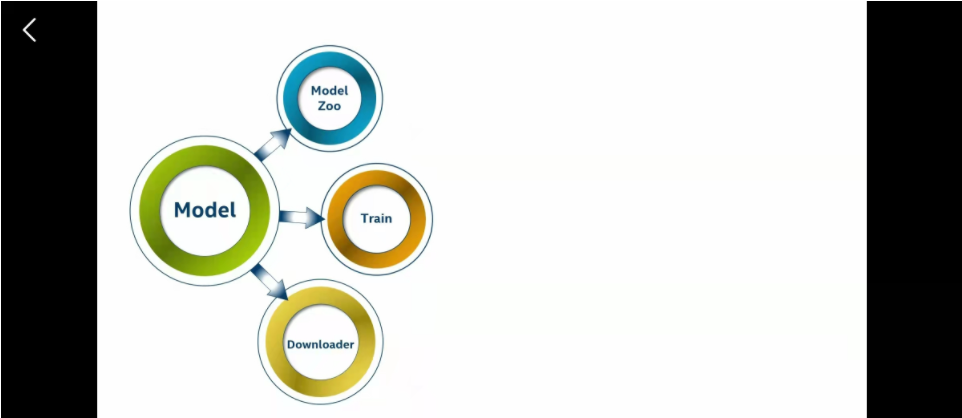
部署的模型
这里用来部署的模型来源一共有三种,官方从模型库中提取、自己去训练(这个是我们的重点)、然后还有一个官方提供的模型下载器,自动从下载一些需要用的模型。
自己训练模型
我们需要自己收集数据、处理和训练
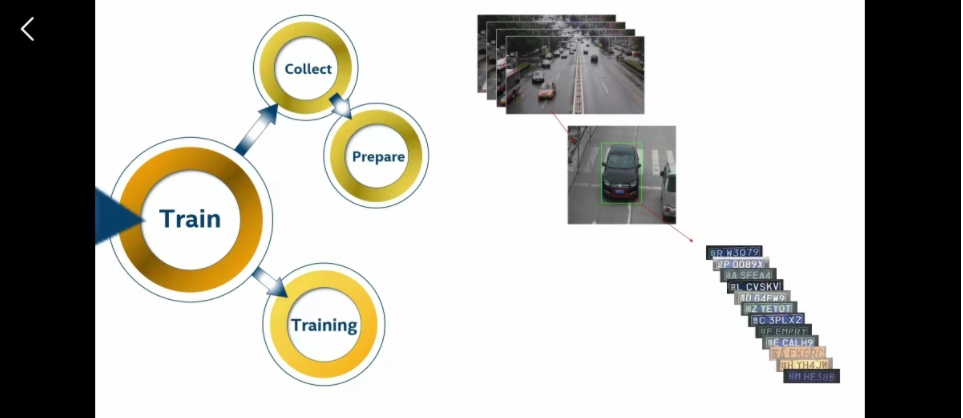
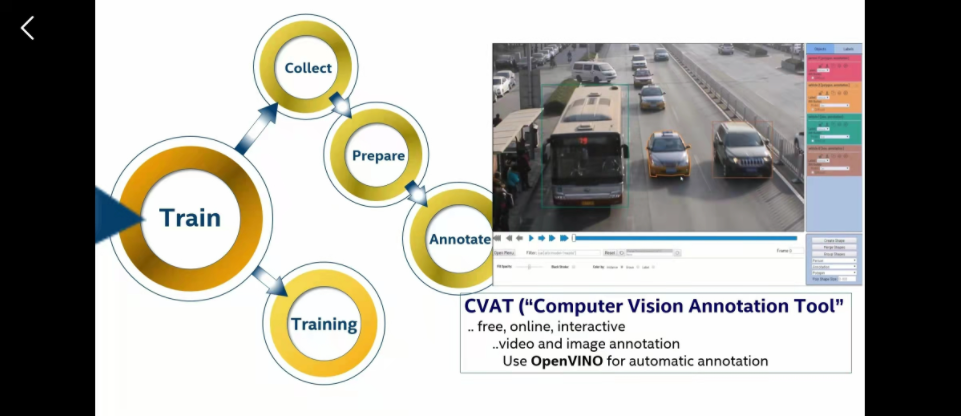
这里看你们的数据源,直接标注可就太伤了。这里你可以试下英特尔的标注软件CVAT。
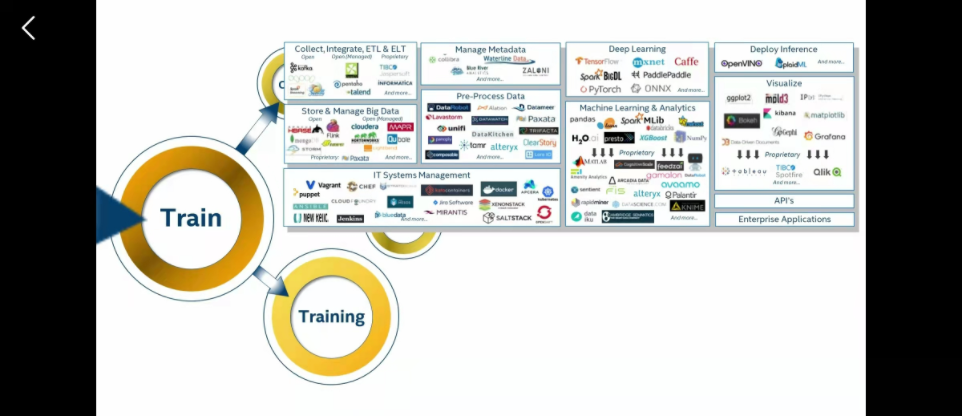
然后用我们主流的比如说TF、pytorch(好像不是很适配)、飞桨(这个为主)
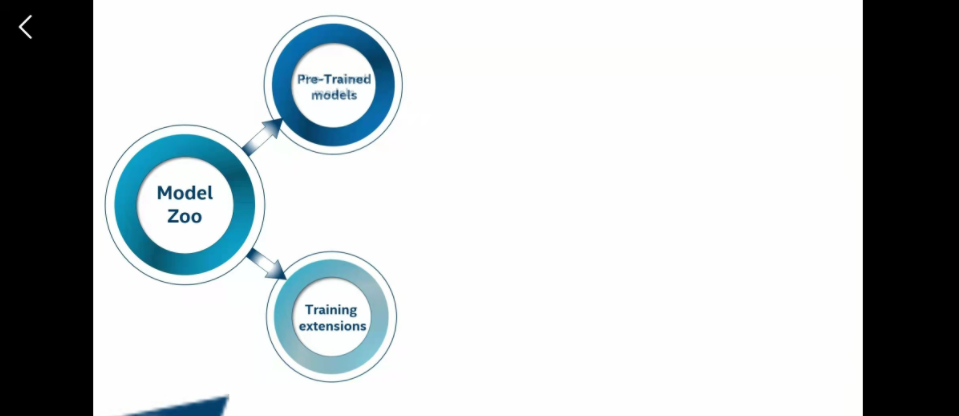
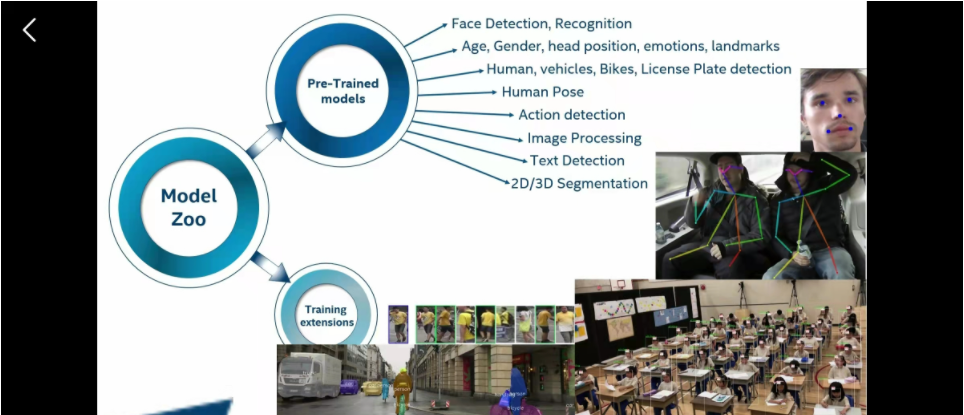
官方提供的模型
这个对新手非常好,就是直接找官方模型
分类分割检测什么都有
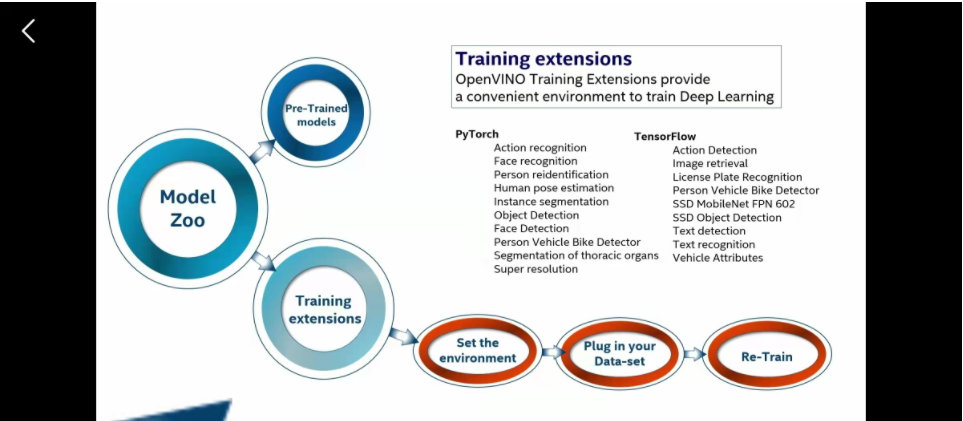
你也可以使用自己的数据集进行训练这些模型
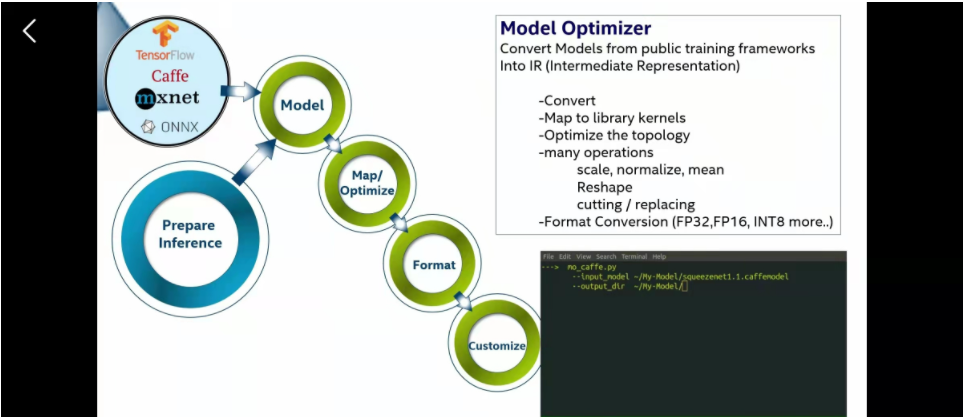
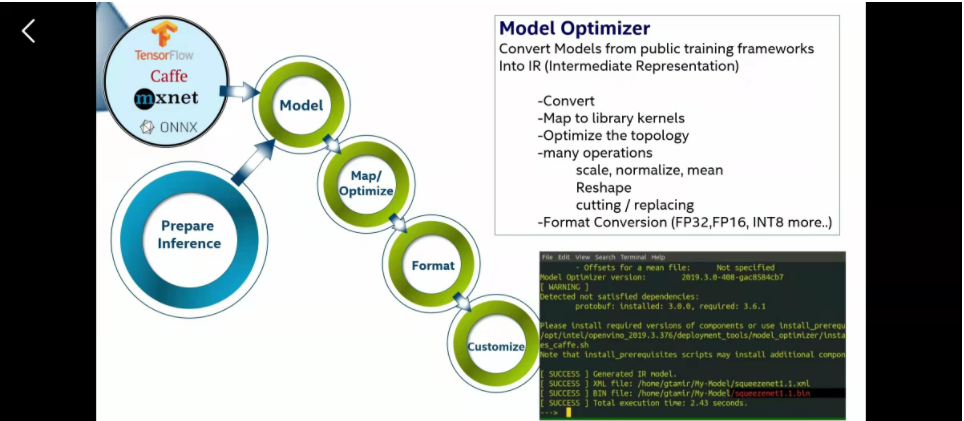
模型装化
就是上面说的把模型转化成中间格式(IR)然后给后面部署
评估模型

这里还可以上英特尔云用他们的各种的设备
视频解码、处理
模拟全流程,全流程跑一遍看看性能
这里英特尔有一个软件叫GVA可以用下他们的
然后部署到工业上的边缘设备就完成了整个流程的开发。