PyTorch + OpenVINO™ 开发实战系列教程 第一篇
 openlab_4276841a
更新于 4年前
openlab_4276841a
更新于 4年前
第1章 Pytorch介绍与基础知识
大家好,本章是主要介绍一下深度学习框架Pytorch的的历史与发展,主要模块构成与基础操作代码演示。重点介绍Pytorch的各个组件、编程方式、环境搭建、基础操作代码演示。本章对有Pytorch开发经验的读者来说可以直接跳过;对初次接触Pytorch的读者来说,通过本章学习认识Pytorch框架,搭建好Pytorch的开发环境,通过一系列的基础代码练习与演示建立起对深度学习与Pytorch框架的感性认知。
本书内容以Python完成全部代码构建与程序演示。本章的主要目标是帮助初次接触Python与Pytorch的读者搭建好开发环境,认识与理解Pytorch框架中常见的基础操作函数、学会使用它们完成一些基础的数据处理与流程处理,为后续内容学习打下良好基础。
好了,下面就让我们来一起开启这段Pytorch框架的深度学习破冰之旅。
1.1 Pytorch介绍
Pytorch是开放源代码的机器学习框架,目的是加速从研究原型到产品开发的过程。其 SDK主要基于Python语言,而Python语言作为流行的人工智能开发语言一直很受研究者与开发者的欢迎。其模型训练支持CPU与GPU、支持分布式训练、云部署、针对深度学习特定领域有不同的丰富的扩展库。
1.1.1 Pytorch历史
Pytorch在2016年由facebook发布的开源机器学习(深度学习)框架,Pytorch最初的来源历史可以追溯到另外两个机器学习框架,第一个是torch框架,第二个是Chainer,实现了Eager模式与自动微分,Pytoch集成了这两个框架的优点, 把Python语言作为框架的首选编程语言,所以它的名字是在torch的前面加上Py之后的Pytorch。由于Pytorch吸取了之前一些深度学习框架优点,开发难度大大降低、很容易构建各种深度学习模型并实现分布式的训练,因此一发布就引发学术界的追捧热潮,成为深度学习研究者与爱好者的首选开发工具。在pytorch发布之后两年的2018年facebook又把caffe2项目整合到pytorch框架中,这样pytorch就进一步整合原来caffe开发者生态社区,因为其开发效率高、特别容易构建各种复杂的深度学习模型网络,因此很快得到大量人工智能开发者的认可与追捧,也成为工业界最受欢迎的深度学习框架之一。
Pytorch发展至今,其版本跟功能几经迭代,针对不同的场景任务分裂出不同的分支扩展库,比如针对自然语言处理(NLP)的torchtext、针对计算机视觉的torchvision、针对语音处理的torchaudio,这些库支持快速模型训练与演示应用,可以帮助开发者快速搭建原型演示。此外在移动端支持、模型部署的压缩、量化、服务器端云化部署、推理端SDK支持等方面Pytorch也在不断的演化改进。
在操作系统与SDK支持方面,Pytorch从最初的单纯支持Python语言到如今支持Python/C++/Java主流编程语言,目前已经支持Linux、Windows、MacOS等主流的操作系统、同时全面支持Android与iOS移动端部署。
在版本发布管理方面,Pytorch分为三种不同的版本分别是稳定版本(Stable Release)、Beta版本、原型版本(Prototype)。其中稳定版本长期支持维护没有明显的性能问题与缺陷,理论上支持向后兼容的版本;Beta版本是基于用户反馈的改动版本,可能有API/SDK函数改动,性能有进一步需要提升的空间;原型版本是新功能还不可以,需要开发不能通过pip方式直接安****r>
1.1.2 Pytorch的模块与功能
Pytorch当前支持绝大数的深度学习常见的算子操作,基于相关的功能模块可以快速整合数据、构建与设计模型、实现模型训练、导出与部署等操作。这些功能的相关模块主要有如下:
torch.nn包,里面主要包含构建卷积神经网络的各种算子操作,主要包括卷积操作(Conv2d、Conv1d、Conv3d)激活函数、序贯模型(Sequential)、功能函数(functional)、损失功能、支持自定义的模型类(Module)等。通过它们就可以实现大多数的模型结构搭建与生成。
torch.utils包,里面主要包括训练模型的输入数据处理类、pytorch自带的模型库、模型训练时候可视化支持组件、检查点与性能相关的组件功能。重要的类有数据集类(Dataset), 数据加载类(DataLoader)、自定义编程的可视化支持组件tensorboard相关类、
torch开头的一些包与功能,主要包括支持模型导出功能的torch.onnx模块、优化器torch.optim模块、支持GPU训练torch.cuda模块,这些都是会经常用的。
此外本书当中还会重点关注的torchvison库中的一些常见模型库与功能函数,主要包括对象检测模块与模型库、图象数据增强与预处理模块等。
以上并不是pytorch框架中全部模块与功能说明,作者这里只列出了跟本书内容关联密切必须掌握的一些模块功能,希望读者可以更好的针对性学习,掌握这些知识。
1.1.3 Pytorch框架现状与趋势
Pytorch是深度学习框架的后起之秀,它参考了市场上早期框架包括torch、caffe、tensorflow的经验教训,从一开始设计就特别注重开发者体验与生产效率提升,一经发布就引发追捧热潮,可以说“出道即巅峰”。Pytorch虽然来自脸书实验室,但是它也吸引外部公司包括特斯拉、优步、亚马逊、微软、阿里等积极支持,其平缓的学习曲线,简洁方便的函数与模型构建在短时间内吸引了大量学术研究者与工业界开发者的追捧。
当前无论是在学术界还是工业界Pytorch已经是主流深度学习框架之一,而且大有后来居上之势,因此随着人工智能赋能各行各业,Pytorch框架必然会更加得到开发者的青睐,成为人工智能(AI)开发者必备技能之一。同时Pytorch也会在部署跟推理方面会更加完善与方便,加强支持移动端,嵌入式端等应用场景,相信掌握Pytorch框架的开发技术人才也会得到丰厚回报。
1.2 环境搭建
Pytorch的开发环境搭建十分的简洁,它的依赖只有Python语言SDK,只要有了Python语言包支持,无论是在windows平台、ubuntu平台还是Mac平台都靠一条命令行就可以完成安装。首先是安装Python语言包支持,当前Pytorch支持的Python语言版本与系统对应列表如下:
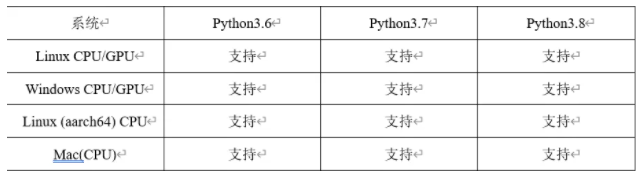
当前最新稳定版本是Pytorch 1.9.0、长期支持版本是Pytorch1.8.2(LTS),此外Python语言支持版本3.6表示支持3.6.x版本,其中x表示3.6版本下的各个小版本,依此类推3.7、3.8同样如此。本书代码演示以Python3.6.5版本作为Python支持语言包。它在Windows系统下的安装过程非常简单,只需如下几步:
1. 下载Python3.6.5安装包,地址为:https://www.python.org/ftp/python/3.6.5/python-3.6.5-amd64.exe
2. 下载之后,双击exe文件安装,显示的界面如下:
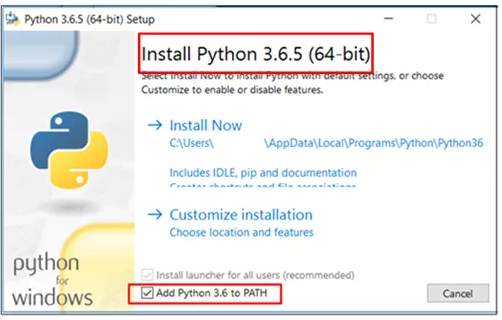
图1-1(Python3.6.5安装界面)
注意:图1-1中的矩形框,必须手动选择上“add Python3.6 to PATH”之后再点击【Install Now】默认安装完成即可。
3. 安装好Python语言包支持以后可以通过命令行来验证测试安装是否成功,首先通过cmd打开Window命令行窗口,然后输入Python,显示如下:

图1-2(验证Python命令行模式)
如果显示图1-2所示的信息表示已经安装成功Python语言包支持;如果输入Python之后显示信息为“'python' 不是内部或外部命令,也不是可运行的程序”则说明第二步中没有勾选上“add Python3.6 to PATH”,此时请手动把python.exe所在路径添加到Windows系统的环境变量中去之后再次执行即可。
4. 安装好Python语言包支持之后,只要运行下面的命令行即可完成Pytorch框架的安装,GPU支持版本的命令行如下(需要GPU显卡支持):
pip install torch==1.9.0+cu102 torchvision==0.10.0+cu102 torchaudio===0.9.0 -f
https://download.pytorch.org/whl/torch_stable.html
CPU支持版本的命令行如下(没有GPU显示支持):
pip install torch torchvision torchaudio5. 在执行第三步的基础上,在命令行中输入下面两行代码,执行结果如下:
>>> import torch
>>> torch._ _version_ _
'1.9.0+cu102'其中第一行表示导入pytorch的包支持,第二行表示版本查询,第三行是执行结果(GPU版本)。
现在很多开发者喜欢使用Ubuntu开发系统,在Ubuntu系统下如下正确安装与配置Pytorch,第一步同样是安装python语言依赖包Python3.6,主要是执行一系列的安装命令行,具体步骤如下:
1. 导入第三方软件仓库.
sudo add-apt-repository ppa:jonathonf/python-3.62. 更新与安装python3.6
sudo apt-get update
sudo apt-get install python3.63. 删除默认python版本设置
zhigang@ubuntu:/usr/bin$ sudo rm python4. 把安装好的3.6设置为默认版本
zhigang@ubuntu:/usr/bin$ sudo ln -s python3.6 /usr/bin/python5. 检查与验证
zhigang@ubuntu:~$ python -V
Python 3.6.5成功完成上述五个步骤的命令行执行就完成了Python语言包依赖安装,然后安装Pytorch框架,CPU版本执行命令行如下:
pip3 install torch==1.9.0+cpu torchvision==0.10.0+cpu torchaudio==0.9.0 -f https://download.pytorch.org/whl/torch_stable.htmlGPU版本执行命令行如下:
pip3 install torch torchvision torchaudio然后执行与Windows下相同的命令行完成pytorch安装校验测试。这样我们就完成了Pytorch的环境搭建,这里有个很特别的地方需要注意,就是Pytorch的GPU版本需要CUDA驱动支持与CUDA库的安装配置支持。关于这块的安装强烈建议参照英伟达官方网站的安装指导与开发者手册。
1.3 Pytorch基础术语与概念
很多人开始学习深度学习框架面临的第一个问题就是专业术语理解跟基本的编程概念与传统面向对象编程不一样,这个是初学者面临的第一个学习障碍。在主流的面向对象编程语言中,结构化代码最常见的关键字是if、else、while、for等关键字,而在深度学习框架中编程模式主要是基于计算图、张量数据、自动微分、优化器等组件构成。面向对象编程运行的结果是交互式可视化的,而深度学习通过训练模型生成模型文件,然后再使用模型预测,本质数据流图的方式工作。所以学习深度学习首先必须厘清深度学习编程中计算图、张量数据、自动微分、优化器这些基本术语概念,下面分别解释如下:
· 张量
张量是深度学习编程框架中需要理解最重要的一个概念,张量的本质是数据,在深度学习框架中一切的数据都可以看成张量。深度学习中的计算图是以张量数据为输入,通过算子运算,实现对整个计算图参数的评估优化。但是到底什么是张量?可以看下面这张图:
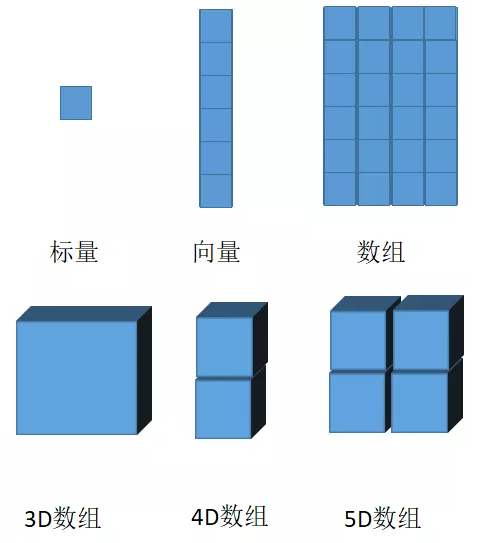
1.4 Pytorch基础操作
1.4.1 PyCharm的安装与配置
点击【Create】按钮完成项目创建,选择文件(File)->设置(Setting)选项:
图1-7(设置选项)
图1-8(设置系统Python解释器)
完成之后,在项目中创建一个空的python文件命名为main.py,然后直接输入下面两行测试代码:
import torch
print(torch.__version__)执行测试(作者笔记本):
1.9.0+cu102这样我们就完成了PyCharm IDE开发环境配置与项目创建。
1.4.2 张量定义与声明
张量在Pytorch深度学习框架中表示的数据,有几种不同的方式来创建与声明张量数据,一种是通过常量数值来直接声明为tensor数据,代码如下:
a = torch.tensor([[2., 3.], [4., 5.]])
print(a, a.dtype)运行结果
tensor([[2., 3.],
[4., 5.]]) torch.float32其中torch.Tensor是torch.FloatTensor的别名,所以默认的数据类型是flaot32,这点从a.dtype的打印结果上也得了印证。此外torch.Tensor函数还支持从Numpy数组直接转换为张量数据,这种定义声明张量数据的代码如下:
b = torch.tensor(np.array([[1,2],[3,4],[5,6],[7, 8]]))
print(b)运行结果:
tensor([[1, 2],
[3, 4],
[5, 6],
[7, 8]], dtype=torch.int32)根据数据类型的自动识别,转换为torch.int32的数据类型。除了直接声明常量数组的方式,Pytorch框架还支持类似Matlab方式的数组初始化方式,可以定义数组的维度,然后初始化为零,相关的演示代码如下:
c = torch.zeros([2, 4], dtype=torch.float32)
print(c)运行结果:
tensor([[0., 0., 0., 0.],
[0., 0., 0., 0.]])初始化了一个两行四列值全部为零的数组。torch.zeros表示初始化全部为零,torch.ones表示初始化全部为1,torch.ones的代码演示如下:
d = torch.ones([2, 4], dtype=torch.float32)
print(d)运行结果:
tensor([[1., 1., 1., 1.],
[1., 1., 1., 1.]])上面都是创建常量数组的方式。在实际的开发中,经常需要随机初始化一些张量变量,创建张量并随机初始化的方式主要通过torch.rand函数实现。用该函数创建张量的代码演示如下:
v1 = torch.rand((2, 3))
print("v1 = ", v1)
torch.initial_seed()
v2 = torch.rand((2, 3))
print("v2 = ", v2)
v3 = torch.randint(0, 255, (4, 4))
print("v3 = ", v3)运行结果:
v1 = tensor([[0.5257, 0.4236, 0.0409],
[0.3271, 0.6173, 0.8080]])
v2 = tensor([[0.9671, 0.6011, 0.3136],
[0.7428, 0.9261, 0.6602]])
v3 = tensor([[181, 170, 49, 82],
[209, 25, 0, 210],
[ 65, 220, 93, 11],
[133, 102, 64, 230]])其中v1是直接输出、v2首先随机初始化种子之后再输出、v3是函数torch.randint创建的随机数组,它的前面两个值0跟255表示整数的取值范围为0~255之间,最后一个(4,4)表示创建4x4大小的数组。
1.4.3 张量操作
通过前面一小节,我们已经学会了在Pytorch中如何创建张量,本节将介绍张量常见的算子操作,通过这些操作进一步加深对Pytorch的理解。
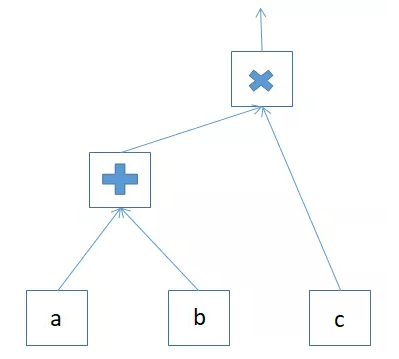
计算图操作
还记得图1-4的计算图吗?这里我们就通过代码构建这样一个计算图,完成一系列基于张量的算子操作,演示代码如下:
a = torch.tensor([[2., 3.], [4., 5.]])
b = torch.tensor([[10, 20], [30, 40]])
c = torch.tensor([[0.1], [0.2]])
x = a + b
y = torch.matmul(x, c)
print("y: ", y)运行结果如下:
y: tensor([[ 5.8000],
[12.4000]])上面得代码中x是a加b的结果,y是a加b之和与c的矩阵乘法的最终输出结果。
· 数据类型转换
在实际的开发过程中,我们经常需要在不同类型的数据张量中切换,因此数据类型转换函数也是必修的,代码演示如下:
m = torch.tensor([1.,2.,3.,4.,5.,6], dtype=torch.float32)
print(m, m.dtype)
print(m.int())
print(m.long())
print(m.double())运行结果如下:
tensor([1., 2., 3., 4., 5., 6.]) torch.float32
tensor([1, 2, 3, 4, 5, 6], dtype=torch.int32)
tensor([1, 2, 3, 4, 5, 6])
tensor([1., 2., 3., 4., 5., 6.], dtype=torch.float64)可见,在PyTorch中实现数据类型转换非常的便捷, m.int()表示转换伟32位整型、m.double()表示转换位64位浮点数类型、m.long()表示64位整型。
· 维度转换
在Pytorch开发中另外一个常见的基础操作就是图象维度转换与升降维度操作,Pytorch中实现对张量数据的维度转换与升降的代码演示如下:
a = torch.arange(12.)
a = torch.reshape(a, (3, 4))
print("a: ", a)
a = torch.reshape(a, (-1, 6))
print("a: ", a)
a = torch.reshape(a, (-1, ))
print("a: ", a)
a = torch.reshape(a, (1, 1, 3, 4))
print("a: ", a)运行结果如下:
a: tensor([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]])
a: tensor([[ 0., 1., 2., 3., 4., 5.],
[ 6., 7., 8., 9., 10., 11.]])
a: tensor([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10., 11.])
a: tensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]]]])其中a是声明的张量数据,torch.reshape(a, (3, 4))意思转换为3行4列的二维数组、torch.reshape(a, (-1, 6))表示转为每行6列的二维数组,其中-1表示从列数推理得到行数、torch.reshape(a, (-1, ))表示直接转换为一行、torch.reshape(a, (1, 1, 3, 4))表示转为1x1x3x4的四维张量。除了torch.reshape函数之外,还有另外一个基于tensor的维度转换方法tensor.view(), 它的用法代码演示如下:
x = torch.randn(4, 4)
print(x.size())
x = x.view(-1, 8)
print(x.size())
x = x.view(1, 1, 4, 4)
print(x.size())运行结果如下:
torch.Size([4, 4])
torch.Size([2, 8])
torch.Size([1, 1, 4, 4])其中torch.randn(4, 4)是创建一个4x4的随机张量;x.view(-1, 8)表示转换为每行八列的,-1表示自动计算行数;x.view(1, 1, 4, 4)表示转换为1x1x4x4的四维张量。其中torch.size表示输出数组维度大小。
· 其它属性操作
通道交换与寻找最大值是Pytorch中处理张量数据常用操作之一,这两个相关函数名称分别是torch.transpose与torch.argmax,支持张量直接操作。代码演示如下:
x = torch.randn(5, 5, 3)
print(x.size())
x = x.transpose(2, 0)
print(x.size())
x = torch.tensor([2., 3., 4.,12., 3., 5., 8., 1.])
print(torch.argmax(x))
x = x.view(-1, 4)
print(x.argmax(1))运行结果如下:
torch.Size([5, 5, 3])
torch.Size([3, 5, 5])
tensor(3)
tensor([3, 2])运行结果的第一行对应是声明的张量x的维度信息、第二行是调用transpose方法完成通道交换之后x输出的维度信息;第三行是针对x调用argmax得到最大值对应索引(12对应索引值为3)、第四行是进行维度变换之后针对二维数据(2x4)的第二个维度调用argmax得到的输出,分别是12与8对应的索引值[3,2]。
· CPU与GPU运算支持
Pytorch支持CPU与GPU计算,默认创建的tensor是CPU版本的,要想使用GPU版本,首先需要检测GPU支持,然后转换为GPU数据,或者直接创建为GPU版本数据,代码演示如下:
gpu = torch.cuda.is_available()
for i in range(torch.cuda.device_count()):
print(torch.cuda.get_device_name(i))
if gpu:
print(x.cuda())
y = torch.tensor([1, 2, 3, 4], device="cuda:0")
print("y: ", y)以上代码查询CUDA支持,如果支持打印GPU名称并把变量x变成GPU支持数据,并打印输出。运行结果如下:
GeForce GTX 1050 Ti
tensor([[ 2., 3., 4., 12.],
[ 3., 5., 8., 1.]], device='cuda:0')
y: tensor([1, 2, 3, 4], device='cuda:0')这里x默认是CPU类型数据,y是直接创建的GPU类型数据。
以上都是一些最基础跟使用频率较高的Pytorch基础操作,了解并掌握这些函数有助于进一步学习本书后续章节知识,更多关于Pytorch基础操作的函数知识与参数说明,读者可以直接参见官方的开发文档。
1.5 线性回归预测
上一小节介绍了Pytorch框架各种基础操作,本节我们学习一个堪称是深度学习版本的Hello World程序,帮助读者理解模型训练与参数优化等基本概念,开始我们学习Pytorch框架编程的愉快旅程。
1.5.1 线性回归过程
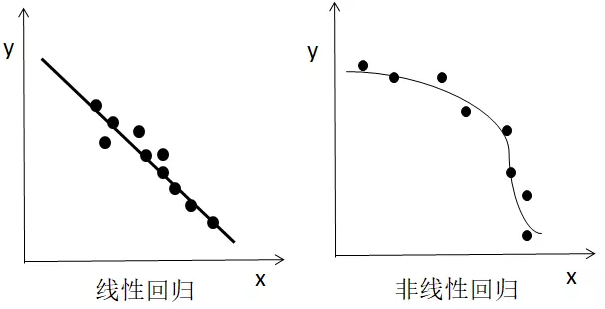
图1-9(线性回归与非线性回归)
图1-9左侧是图中得圆点表示xy二维坐标点数据集,直线是根据线性回归算法生成的。右侧则是一个根据坐标点数据集生成一个非线性回归的例子。现在我们已经可以很直观的了解什么线性回归了,脑子里面可能会有个大大的疑问(?),线性回归是怎么找到这条直线的?答案就是通过Pytorch构建一个简单的计算图来不断学习,最终得到一个足够逼近真实直线参数方程,这个过程也可以被称为线性回归的学习/训练过程。最终根据得到的参数就可以绘制回归直线。那这个计算图到底是怎么样的?答案就是很简单的数学知识,最常见的直线方程如下:
假设我们有二维的坐标点数据集:
x: 1,2,0.5,2.5,2.6,3.1
y: 3.7,4.6,1.65,5.68,5.98,6.95
我们通过随机赋值初始k、b两个参数,根据公式1-1,x会生成一个对应输出,它跟真实值y之间的差值我们称为损失,最常见的为均值平方损失(MSE),表示如下:
然后我们可以通过下面的公式来更新k、b两个参数:
其中学习率通常用表示,对应的每个参数梯度则根据深度学习框架的自动微分机制得到的,这样就实现了线性回归模型模型的构建与训练过程,最终根据输入的迭代次数运行输出就获取了回归直线的两个参数。完成了线性回归的求解。
1.5.2 线性回归代码演示
通过前面一小节的学习读者应该了什么是线性回归、线性回归是如何工作的,现在我们已经迫不及待的想在Pytorch中通过代码来验证我们上面的理论解释了。Pytorch提供了丰富的函数组件可以帮助我们快速搭建线性回归模型并完成训练预测。
第一步:构建数据集
x = np.array([1,2,0.5,2.5,2.6,3.1], dtype=np.float32).reshape((-1, 1))
y = np.array([3.7,4.6,1.65,5.68,5.98,6.95], dtype=np.float32).reshape(-1, 1)第二步:根据公式1-1构建线性回归模型
class LinearRegressionModel(torch.nn.Module):
def __init__(self, input_dim, output_dim):
super(LinearRegressionModel, self).__init__()
self.linear = torch.nn.Linear(input_dim, output_dim)
def forward(self, x):
out = self.linear(x)
return outLinearRegressionModel是一个自定义的类,继承了torch.nn.Module,其中torch.nn.Linear就表示构建了公式1-1的线性模型,重载方法forward,表示根据模型计算返回预测结果。
第三步:创建损失功能与优化器
input_dim = 1
output_dim = 1
model = LinearRegressionModel(input_dim, output_dim)
criterion = torch.nn.MSELos*****r>
learning_rate = 0.01
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)其中MSELoss跟公式1-2表述一致、优化器optimizer完成自动梯度求解并根据公式1-3的方式来更新每个参数。
第四步:开始迭代训练过程
for epoch in range(100):
epoch += 1
# Convert numpy array to torch Variable
inputs = torch.from_numpy(x).requires_grad_()
labels = torch.from_numpy(y)
# Clear gradients w.r.t. parameter***r>
optimizer.zero_grad()
# Forward to get output
output*****odel(input****r>
# Calculate Los***r>
loss = criterion(outputs, label****r>
# Getting gradients w.r.t. parameter***r>
los***ackward()
# Updating parameter***r>
optimizer.step()
print('epoch {}, loss {}'.format(epoch, loss.item()))这部分的代码注释都很清楚了,这里就不再赘述。
第五步:根据训练得到的参数,使用模型预测得到回归直线并显示,代码如下:
predicted = model(torch.from_numpy(x).requires_grad_()).data.numpy()
# Plot true data
plt.plot(x, y, 'go', label='True data', alpha=0.5)
# Plot prediction***r>
plt.plot(x, predicted_y, '--', label='Predictions', alpha=0.5)
# Legend and plot
plt.legend(loc='best')
plt.show()运行结果如下:
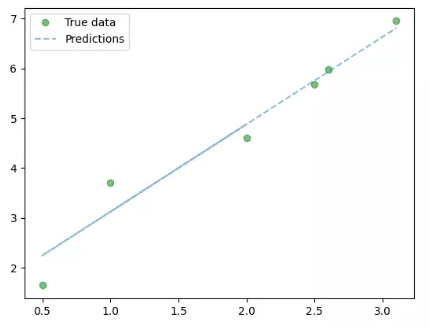
图1-10中点表示训练数据,直线表示线性回归预测。
总结线性回归这个入门级别例子演示,我们从中可以学习到一些基本组件函数,它们就是模型创建、损失函数、学习率、优化器,它们都是Pytroch开发中必须掌握的基本组件函数与方法,学会使用它们可以事半功倍,减少代码量,提升开发效率。
1.6 小结
本章是Pytorch框架与基础知识的介绍,通过本章学习了解Pytorch框架的历史与发展、理解深度学习框架常见的术语与词汇含义;安装Python SDK、掌握Pytorch安装命令行、Pycharm IDE安装与配置。学会使用Pytorch创建基本的张量、能够完成常见的张量数据操作、最后通过一个具有代表性的线性回归的例子,帮助大家真正打开Pytroch框架开发的大门。
本章的目标是帮助初学者厘清深度学习框架基本概念、基础组件与基础数据操作、同时通过案例激发起大家进一步学习的兴趣。