干货|在OpenVINO 中使用 fine-tuning 的 BERT模型
 openlab_4276841a
更新于 4年前
openlab_4276841a
更新于 4年前
大家好,我是 Tango,目前就职于 NTTDATA (中国)信息技术有限公司。看到公司名大家估计也能猜出来这是一家日企了,我也是日语专业毕业的,出于爱好进入了程序员的队伍。今天和我一起来看看我们强大的 OpenVINO 套件和 BERT 模型会擦出什么样的火花。
Part 1 关于环境
在本篇文章中,将从使用了 Tensorflow 的 BERT 的 fine-tuning 到 OpenVINO 的的转换、推理进行演示。在正式开始写代码前,和大家介绍一下我的环境。* Mac OS M1 版本
* OpenVINO 2021.4.689
* TF2
Part 2 安装OpenVINO
OpenVINO 安装教程在树莓派上体验Win11 + OpenVINO
Part 3 涉及技术
conda create -n py39_tf python=3.9
conda activate py39_tf
pip install tensorflow -i https://pypi.tuna.tsinghua.edu.cn/simple我在安装完成后,运行时出现如下错误80859 illegal hardware instruction最后,通过下载whl文件进行安装可以解决。
随便运行点项目验证一下环境十分搭建成功
import tensorflow as tf
import time
mnist = tf.keras.dataset***nist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.kera***odels.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
start = time.time()
model.fit(x_train, y_train, epochs=5)
end = time.time()
model.evaluate(x_test, y_test)
print(end - start)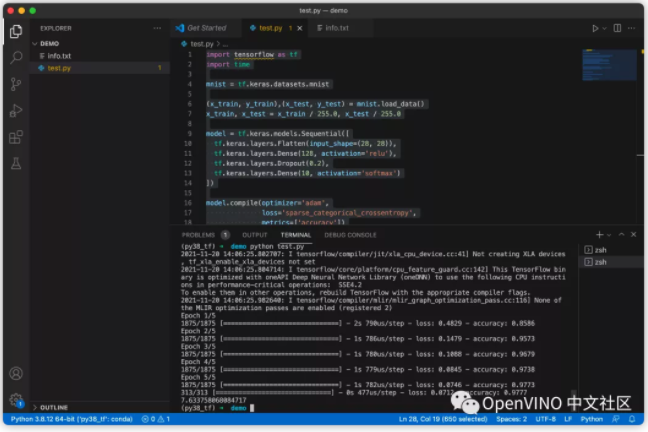
可以看到项目可以运行。
Start 开始正式内容
环境搭建建好,我们就要开始尝试利用BERT来做点什么了。我们使用的数据集是SQuAD日语部分。
SQuAD:斯坦福问答数据集(SQuAD)是一个全新的阅读理解数据集,由众包人员基于一系列****文章的提问和对应的答案构成,其中每个问题的答案是相关文章中的文本片段或区间。SQuAD 包含关于 500 多篇文章的超过 100000 个问答对,规模远远超过其他阅读理解数据集。
1. BERT的fine-tuning
* 下载数据集
git clone https://github.com/google-research/bert.git
mv bert tf1_bert && cd tf1_bert
mkdir JaSQuAD_v2.0 && cd JaSQuAD_v2.0
# 将之前准备好的数据集放到JaSQuAD_v2.0文件夹下面
unzip -j squad-japanese.zip
rm squad-japanese.zip
cd ../
wget "http://nlp.ist.i.kyoto-u.ac.jp/DLcounter/lime.cgi?down=http://lotus.kuee.kyoto-u.ac.jp/nl-resource/JapaneseBertPretrainedModel/Japanese_L-12_H-768_A-12_E-30_BPE.zip&name=Japanese_L-12_H-768_A-12_E-30_BPE.zip" -O ./Japanese_L-12_H-768_A-12_E-30_BPE.zip
unzip Japanese_L-12_H-768_A-12_E-30_BPE.zip && rm Japanese_L-12_H-768_A-12_E-30_BPE.zip
准本好数据后,我们可以通过如下的Python代码读取文件内容
* 修改内置py文件及方法
def read_ja_squad_examples(input_file, is_training):
example********r> with tf.gfile.Open(input_file, "r") as reader:
json_lines = reader.readline*****r> #print(json_line****r> for line in json_lines:
data = json.loads(line)
if is_training:
start_position=data['start']
end_position=data['end']
orig_answer_text=' '.join(data['context'].split(' ')[data['start']:data['end']+1])
else:
start_position = -1
end_position = -1
orig_answer_text = ""
example = SquadExample(
qas_id=data['id'],
question_text=data['question'],
doc_tokens=data['context'].split(' '),
orig_answer_text=orig_answer_text,
start_position=start_position,
end_position=end_position,
is_impossible=False
)
examples.append(example)
return examples我们将上面的代码添加到 run_squad.py 中:
同时顺手将该文件中的 read_squad_examples 方法修改为run_ja_squad_examples
2. 将单词 token 化
我们可以利用项目中的 tokenization.py 文件进行 token 化(将单词转换为数组)。我们将训练时需要用的单词保存在了 vocab.txt 文件中,如果不在这个里面的单词会被标记为 UNK。
3. 命名训练出来的文件
用 run_squad.py 里面的 create_model 输出的回答的开始和结束位置用 tf.variable_scope( ) 来命名。
with tf.variable_scope("cls/squad/output"):
final_hidden_matrix = tf.reshape(final_hidden,
[batch_size * seq_length, hidden_size])
logits = tf.matmul(final_hidden_matrix, output_weights, transpose_b=True)
logits = tf.nn.bias_add(logits, output_bia****r>
logits = tf.reshape(logit*****atch_size, seq_length, 2])
logits = tf.transpose(logits, [2, 0, 1])
unstacked_logits = tf.unstack(logits, axis=0)开始训练
export SQUAD_DIR=JaSQuAD_v2.0
export BERT_DIR=Japanese_L-12_H-768_A-12_E-30_BPE
export OUTPUT_DIR=SQUAD_DIR/model/Japanese_L-12_H-768_A-12_E-30_BPE
python run_squad.py \
--vocab_file=BERT_DIR/vocab.txt \
--bert_config_file=BERT_DIR/bert_config.json \
--init_checkpoint=BERT_DIR/bert_model.ckpt \
--do_train=True \
--train_file=SQUAD_DIR/train.jsonl \
--do_predict=True \
--predict_file=SQUAD_DIR/valid.jsonl \
--train_batch_size=12 \
--learning_rate=3e-5 \
--num_train_epochs=3.0 \
--max_seq_length=384 \
--doc_stride=128 \
--output_dir=$OUTPUT_DIR \
--version_2_with_negative=True > ./train_jp.log为了在 OpenVINO 中进行推理,需要将生成好的 model.ckpt 转换为 frozen graph 形式。
* run_squad.py
def model_fn_builder(...):
┆
(start_logits, end_logit************r>
### add export script
import os, sy***r> from tensorflow.python.framework import graph_io
with tf.Session(graph=tf.get_default_graph()) as sess:
(assignment_map, initialized_variable_names) = \
modeling.get_assignment_map_from_checkpoint(tf.trainable_variables(), init_checkpoint)
tf.train.init_from_checkpoint(init_checkpoint, assignment_map)
sess.run(tf.global_variables_initializer())
frozen = tf.graph_util.convert_variables_to_constants(sess, sess.graph_def, ["cls/squad/output/unstack"])
graph_io.write_graph(frozen, './', 'inference_graph.pb', as_text=False)
print('BERT frozen model path {}'.format(os.path.join(os.path.dirname(__file__), 'inference_graph.pb')))
sys.exit(0)
###
tvars = tf.trainable_variables()* modeling.py (923-924行)
#if not non_static_indexes:
# return shape在次运行 run_squad.py 生成 inference_graph.pb。
python run_squad.py \
--vocab_file=BERT_DIR/vocab.txt \
--bert_config_file=BERT_DIR/bert_config.json \
--init_checkpoint=OUTPUT_DIR/model.ckpt-XXXXX \
--do_train=False \
--do_predict=True \
--predict_file=SQUAD_DIR/valid.jsonl \
--max_seq_length=384 \
--doc_stride=128 \
--output_dir=./tmp \
--version_2_with_negative=True使用 ModelOptimizer 转换 IR
export MO_PATH=/opt/intel/openvino_2021/deployment_tool***odel_optimizer
python MO_PATH/mo_tf.py \
--input_model ./inference_graph.pb \
--input "IteratorGetNext:0{i32}[1 384],IteratorGetNext:1{i32}[1 384],IteratorGetNext:2{i32}[1 384]" \
--disable_nhwc_tonchw \
--output_dirOUTPUT_DIR/i推理
import collection***r>import logging
import json
import six
import tokenization
class SquadExample(object):⋯
class InputFeatures(object):⋯
def read_ja_squad_examples(⋯):⋯
def convert_examples_to_features(⋯):⋯
def _improce_answer_span(⋯):⋯
def check_i***ax_context(⋯):⋯
def export_feature(vocab_file, data_file, is_training, do_lower_case, max_seq_length, doc_stride, max_query_length, use_ja_squad):
tokenizer = tokenization.FullTokenizer(
vocab_file=vocab_file, do_lower_case=False)
examples = read_ja_squad_example****r> input_file=data_file, is_training=is_training)
logging.info("Load {} examples".format(len(example******r> features = convert_examples_to_features(examples, tokenizer, max_seq_length,doc_stride, max_query_length, is_training)
return featurestf.logging 修改为logging
tf.gfile.Gfile() 修改为open()
最后修改的代码为
import osimport argparseimport timeimport numpy as npimport logging as logformatter = '[%(levelname)s] %(asctime)*****essage)s'log.basicConfig(level=log.INFO, format=formatter)from openvino.inference_engine import IECoreimport tokenization_helper as TokenizationHelperparser = argparse.ArgumentParser()parser.add_argument("-d", "--device", default="CPU", type=str)parser.add_argument("-v", "--vocab", required=True, type=str)parser.add_argument("-m", "--model", required=True, type=str)parser.add_argument("-i", "--input-data", required=True, type=str)parser.add_argument("--is-training", action="store_true")parser.add_argument("--max-seq-length", type=int, default=384)parser.add_argument("--doc-stride", type=int, default=128)parser.add_argument("--max-query-length", type=int, default=64)parser.add_argument("--do-lower-case", action="store_true")parser.add_argument("--use-ja-squad", action="store_true")args = parser.parse_args()def main(): log.info("Initializing Inference Engine") ie = IECore() version = ie.get_versions(args.device)[args.device] version_str = "{}.{}.{}".format(version.major, version.minor, version.build_number) log.info("Plugin version is {}".format(version_str)) # read IR model_xml = arg***odel model_bin = os.path.splitext(model_xml)[0] + ".bin" log.info("Loading network files:\n\t{}\n\t{}".format(model_xml, model_bin)) ie_encoder = ie.read_network(model=model_xml, weight***odel_bin) # load model to the device log.info("Loading model to the {}".format(args.device)) ie_encoder_exec = ie.load_network(network=ie_encoder, device_name=args.device) # check input and output names input_names = list(ie_encoder.input_info.keys()) output_names = list(ie_encoder.outputs.keys()) input_info_text = "Inputs number: {}".format(len(ie_encoder.input_info.keys())) for input_key in ie_encoder.input_info: input_info_text += "\n\t- {} : {}".format(input_key, ie_encoder.input_info[input_key].input_data.shape) log.info(input_info_text) output_info_text = "Outputs number: {}".format(len(ie_encoder.outputs.keys())) for output_key in ie_encoder.outputs: output_info_text += "\n\t- {} : {}".format(output_key, ie_encoder.outputs[output_key].shape) log.info(output_info_text) #TokenizationHelper. log.info("Start tokenization") input_features = TokenizationHelper.tokenize( vocab_file = args.vocab, data_file = args.input_data, is_training = args.is_training, do_lower_case = args.do_lower_case, max_seq_length = arg***ax_seq_length, doc_stride = args.doc_stride, max_query_length = arg***ax_query_length, use_ja_squad = args.use_ja_squad ) log.info("Complete tokenization") log.info("Predict start") for infer_index, feature in enumerate(input_features): # create numpy inputs for IE inputs = { input_names[0]: np.array([feature.input_ids], dtype=np.int32), input_names[1]: np.array([feature.input_mask], dtype=np.int32), input_names[2]: np.array([feature.segment_ids], dtype=np.int32), } # infer by IE t_start = time.perf_counter() res = ie_encoder_exec.infer(inputs=inputs) t_end = time.perf_counter() log.info("Inference time : {:0.2} sec".format(t_end - t_start)) start_logits = res[output_names[0]].flatten() end_logits = res[output_names[1]].flatten() start_index = np.argmax(start_logits) end_index = np.argmax(end_logits) print(start_index, end_index) tok_tokens = feature.tokens[start_index:(end_index + 1)] print(" ".join(tok_tokens)) # to infer only one breakif __name__ == "__main__": main()生成结果
$ python openvino_bert_infer.py \
-v Japanese_L-12_H-768_A-12_E-30_BPE/vocab.txt \
-m JaSQuAD_v2.0/model/Japanese_L-12_H-768_A-12_E-30_BPE/ir/inference_graph.xml \
-i JaSQuAD_v2.0/valid.jsonl
[INFO] 2021-11-20 07:53:25,332 Initializing Inference Engine
[INFO] 2021-11-20 07:53:25,338 Plugin version is 2.1.2021.2.0-1877-176bdf51370-releases/2021/2
[INFO] 2021-11-20 07:53:25,338 Loading network files:
JaSQuAD_v2.0/20201223_model/Japanese_L-12_H-768_A-12_E-30_BPE/ir/inference_graph.xml
JaSQuAD_v2.0/20201223_model/Japanese_L-12_H-768_A-12_E-30_BPE/ir/inference_graph.bin
[INFO] 2021-11-20 07:53:25,571 Loading model to the CPU
[INFO] 2021-11-20 07:53:26,320 Inputs number: 3
- IteratorGetNext/placeholder_out_port_0 : [1, 384]
- IteratorGetNext/placeholder_out_port_1 : [1, 384]
- IteratorGetNext/placeholder_out_port_2 : [1, 384]
[INFO] 2021-11-20 07:53:26,320 Outputs number: 2
- cls/squad/output/unstack/Squeeze_ : [1, 384]
- cls/squad/output/unstack/Squeeze_1725 : [1, 384]
[INFO] 2021-11-20 07:53:26,320 Start tokenization
[INFO] 2021-11-20 07:53:26,365 Load 1 example***r>[INFO] 2021-11-20 07:53:26,369 Complete tokenization
[INFO] 2021-11-20 07:53:26,369 Predict start
11 53
ノルマン ( ノルマン :ノルマン ##ド [UNK] フランス 語 :ノルマン ##ド [UNK] ラテン :ノルマン ##ニ )
は 、 [UNK] 世 紀 および [UNK] 世 紀 に フランス の 地 域 ノルマンディー に 名 前 を 与 えた 人 々 でした 。从结果中可以看到,对于"ノルマンディーはどの国にありますか?"这个问题的答案是"ノルマン(ノルマン :ノルマンド;フランス語 :ノルマンド;ラテン:ノルマンニ)は、10世紀および11世紀にフランスの地域ノルマンディーに名前を与えた人々でした 。"推理时间根据环境问题可以维持0.15 sec/request 左右。
文章中还有很多需要修改的地方,该数据集来源一个日本作者,其实是英文版通过谷歌翻译机翻过来的。有时间我们那可以试试中文版的效果如何。好了,这次的内容就是这些,如果有疑问欢迎加流学习。
本文来源于公众号:OpenVINO 中文社区