超大规模云网络数据中心创新(下)
 小o
更新于 4年前
小o
更新于 4年前
作者简介:马绍文,邮箱:mashaowen@gmail.com
前文阅读:超大规模云网络数据中心创新(上)
3 云计算 Overlay 网络架构
3.1 Overlay SDN 控制器
Google云网络由四个基石组成,B4(广域网互联),Espresso(意式咖啡,BGP SDN Peering),Jupiter(木星,数据中心Underlay 网络)和Andromeda(仙女座,Overlay 网络)。前面两个技术详细介绍请参考我之前写过的两篇文章。前文详细介绍了数据中心交换机 Fabric 网络架构,接下来简单介绍一下Overlay网络。

为满足云计算客户按需使用超大规模数据中心**享的软硬件资源和信息,需要把把多个机柜(Rack)和可用区(AZ)的物理设备上提供的计算,网络和存储,池化,虚拟化并构建成为一个虚拟的私有云(VPC)。GCP采用Andromeda(仙女座)SDN控制器来管理全球数据中心的虚拟化资源。仙女座实现了云计算客户自动创建/删除VM&VPC时,虚拟网络部分能够自动配置,连通,进行策略控制。
Google的数据中心交换机采用纯IP Fabric互联,同一个数据中心的交换机上学到每个物理服器的私有Underlay IP地址。每个数据中心大概5/6千个机柜,总共 20 多万个服务器 IP 地址(可以汇聚)。但是客户的Overlay IP地址不需要在交换机上出现,主机侧把客户的报文封装成IPinIP或者VxLAN隧道,中间交换机只是根据主机的IP地址进行寻路转发,只有两侧主机有客户VPC的overlay路由表。
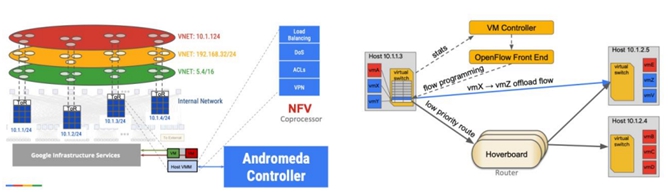
如上图所示,仙女座在同一个物理网络上构建出红黄绿等多张虚拟网络VPC,并把属于同一个VPC的VM通过主机上的隧道联通起来。仙女座采用Openflow去配置主机上的OvS流表,来实现虚机之间的流量转发。业界最大规模的Openflow SDN控制器Cluster可能就是仙女座了。
Pre-programmed 模式:业界很多Overlay SDN实现办法是把属于同一个VPC的每个主机上构建一个Full Mesh 的隧道网络,VPC overlay路由表同步到每个相应的主机上。但对于支持100K+ VM的公有云来说不太适用,控制器同时要配置几十万个OvS,每个 Host上的OVS可能有几千个FIB Entry。对于新加入的一个VM,可能需要去变更几千个host,配置变更需要非常多的时间,超过10K VM可能需要10多分钟才能变更结束。此外常见的还有On Demand 模式,首包上送控制器查表,控制器查表并下发流表,此种模式容易受到DDoS攻击,并且首包保时延更大。
Openstack常用Gateway 模式,所有报文上送Gateway,本机OvS只保留缺省路由,这种模式需要额外的服务器来处理转发,并且不太适合突发性任务。
Hoverboard 模式:Google结合了Gateway和On Demand模式开发了Hoverboard(跳板)模式。主要的理论基础是:部分虚机(83%)之间完全没有通讯!更大部分(98%)虚机之间通讯小于20Kbps。也就是主机OvS保留之前<2%的转发表项,就可以处理大部分的转发流量,但是怎么决定主机OvS保留哪些长连接的转发表项?
仙女座设计了OvS+vRouter(Hoverboard)+Controller的SDN系统:
- 仙女座控制器把数据中心主机上VM的IP转发规则,配置在 Hoverboard上。
- 主机上的OvS缺省流量指向Hoverboard,从host上监测,流量大于100Kbps的,控制器在OvS上添加卸载(直连)规则,不必经过Hoverboard,下一跳直接指向远端服务器。OvS只保留Full Mesh路由的2%左右。
- 控制器变更OvS+Hoverboard 延迟很短,在 100K VM情况下,只需要186ms。
Google还为Hoverboard申请了专利VIRTUAL ROUTER WITH DYNAMIC FLOW OFFLOAD CAPABILITY。

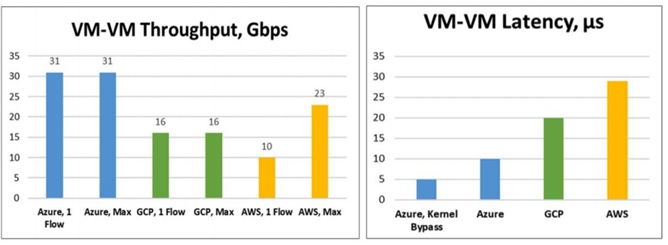
为了追求完全软件可编程,仙女座只使用了网卡芯片的一些通用offload能力(encryption,checksum***emory copies)。优化简化了流表查询,数据包转发,提供低时延转发。Host 上分布式实现了ACL, LB,NAT等NFV功能都是采用单独纯软件Coprocessor 进程转发流程实现的。因为缺少硬件卸载功能,总体来看Andromeda转发性能低下。下图是2018年微软发布的三朵云性能和时延的比较,仅供参考。
关于详细的云网VPC,GW,Peering,虚拟化,硬件卸载,智能网卡等内容会单独成文。
3.2 Routing on the Host,SRv6 Overlay和Calico 简介
现代数据中心Underlay网络,绝大部分已经使用 BGP构建全新数据中心交换机Fabric。具体可参见Facebook Petr在RFC7938 (BGP 在超大规模DC的应用)里的详细描述。采用BGP构建Underlay Fabric 之后,交换机之间简单的BGP协议之间一般不发生故障,大部分故障源于交换机和服务器之间。为了提高冗余****器一般采用MLAG双上联交换机来保证业务可靠性,但是MLAG浪费交换机之间的 ICCP 接口,同时软件bug很多,状态不同步,导致数据中心业务频繁中断。为了要把服务器IP地址分布消息传递给全网的交换机。越来越多的超大规模数据中心采用Routing On the Host(RoH,主机路由协议),下图可以看出,部署RoH主机 Hypervisor上跑BGP协议之后,新创建的VM/Container分配IP地址之后,BGP路由协议(FRR/BIRD)会把32位IP地址发送给ToR交换机。当上联的任何一个接口/ToR 故障时,BGP会切换到另一个ToR Peering链路。
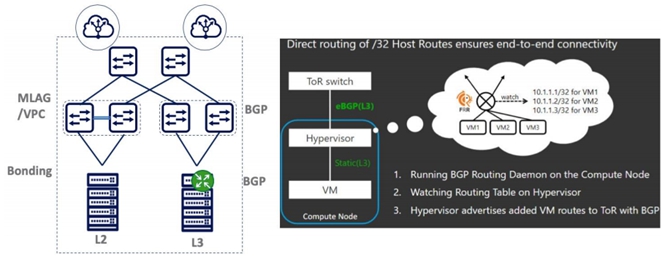
部分云公司架构师对部署Routing on the Host还心存顾虑,担心需要管理监控成千上万个服务器上的BGP协议太复杂,并且要求服务器侧工程师也要懂网络协议。其实主机侧的BGP协议配置简单,仅仅传输几个主机路由,Debug也不难,而且还有很多Ansible自动化部署检测脚本。OpenStack Neutron Plugin配置驱动Tungsten Fabric SDN 控制器来配置vRouter并取代缺省的Compute Node 里面的OvS。

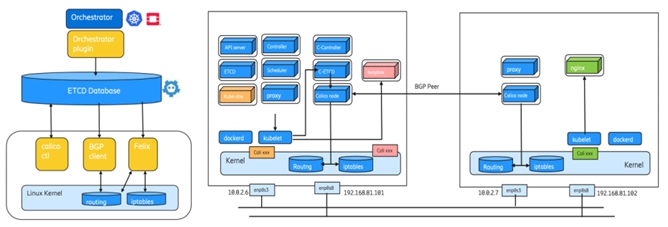
在数据中心IP Fabric之上,vRotuer提供类似EVPN PE功能,本地学习到的Host IP/MAC,通过XMPP上送到SDN控制器(模拟 BGP/EVPN RR)来分发给全数据中心相应的主机vRouter。vRouter在Hypervisor内核里面取代Linux Bridge或者OvS。不仅提供EVPN/L3VPN功能,还支持Security Policy,NAT,Multicast,Mirroring,LB等功能。关于Tungsten Fabric Overlay SDN控制器 的更多Deep Dive信息,请参考我之前写的一篇***。
从上面的简介可以看出归根结底Open Contrail/Tungsten Fabric的技术基石也是EVPN on the Host。推动Routing on the Host 的一个主要因素是,随着 Kubernetes 网络大规模部署,很多 CNI 都需要支持BGP on the Host。以最流行的Calico(Cilium 类似)为例,当主机上的Felix收到新的IP地址和访问策略,会添加到路由表和IP Tables。BGP Client(Bird)会检测到主机路由,并发送给RR或者其他POD的Calico节点。Calico支持IPinIP/VXLAN Tunnel,同时也支持Openstack和K8S。
推动Routing on the Host的另一个因素是:SRv6在IPv6 Overlay网络中的应用。
IPv4 地址分配殆尽,很多云公司纷纷转去IPv6 Underlay,同时需要支持多租户网络隔离,很多交换机芯片不能很好支持IPv6 underlay VxLAN,同时VxLAN不能很好支持云**业务链(Service Chaining)。一些云公司考虑直接采用SRv6来构建Overlay网络,顺应IPv6发展,提供VPN隔离,并且支持云**业务链。
某云公司采用Openstack云平台来管理VM/Container ,分配IP地址,进行策略控制。SDN控制器来分发针对每个Hypervisor里的 SRv6节点进行策略封装(T.Encaps),解封装(End.DX4/DX6)SRv6 报文。SRv6 包含目的IPv6 Underlay地址和至少一个IPv6 SID 作为云overlay地址,需要支持多跳业务链时,可以添加多个IPv6 SID。
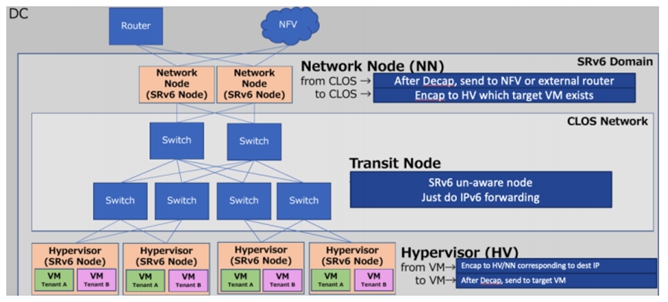
采用SRv6 Overlay技术之后,根据不同IPv6目的地址网段,可以很容易的针对每个VM/Container 控制南北向流量引流去云**(LB/FW)。可以无缝跟云**和云骨干网的SRv6整合,进行全球云骨干网流量工程调度(WAN SDN)。
综上所述,Routing/EVPN on the Host在很多场景里已经大规模应用。SRv6作为新型IPv6 Overlay技术引起很多云公司关注。很多数据中心交换机芯片无法支持 SRv6 端点功能,而且采用主机CPU 做VxLAN/SRv6 SDN转发性能很差,所以下一代SDN技术需要很强劲的智能网卡SmartNIC进行VxLAN/SRv6的转发卸载。限于篇幅,关于智能网卡DPDK/SR-IOV/VirtIO/eXpress Data Path卸载会单独成篇。
4 总结和展望
4.1 单芯片盒子,128端口扇出成为国内主流
国内和国外云公司数据中心架构不太一样,国内云数据中心一般在 ToR上要求更大的表项,更多功能, 不采用分光接口,国外公司 ToR普遍采用功能简单,表项少,一般支持分光接口的芯片。国内云公司数据中心最新架构很多都采用了 8 端口上行 ToR,Spine/SuperSpine位置用单芯片盒子(128端口扇出)取代了传统的大机箱。有些国内外云公司还采用多槽位256/512端口的 Spine/Super Spine。
对于200G fabric,在 Spine/SuperSpine 层面会采用25.6T盒子(128x200GE, 2021/2022 年成熟),ToR 层面会采用32/40 x 200GE,下行分光成 50G 或者 100GE。对于400G Fabric,大概率会等51.2T芯片成熟(128x400G,2023+)才会大规模部署。
如下图我们大概总结了国内互联网公司部署200G/400G的设备形态和大致时间,仅供参考。

国内云公司做法跟Facebook设计非常类似,但是F16的架构也不是很完美。首先Spine层,支持128个端口的盒子,仅用到了84个接口(36个接Superspine,48个接POD里的ToR)。浪费了 1/4 盒子容量。为了维持跟F4相同架构,每个POD里含有48个ToR,明明可以增加到每个POD 64~96 个ToR。
4.2 超越 Beyond 12.8T
云计算业务快速发展,需要下一代交换芯片容量成倍增长,各家芯片公司纷纷采用最新芯片制程16nm(12.8T),7nm(25.6T),甚至计划采用5nm(51.2T)技术。在此基础上,还需要采用一些创新技术:
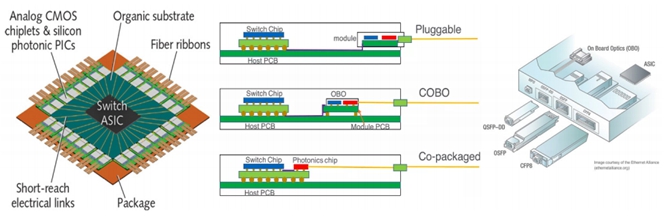
- 多芯片模块(Multiple Chip Module):一般是一个核心芯片加上8个或者16个SerDes 芯片。芯片的Die Size 每增加10%,良品率降低,成本升高一倍。采用多芯片架构,可以保证核心芯片大小是原来的一半左右,极大的提高了良品率,降低了成本。同时采用1+8 架构,产生的热量分散到多个小型芯片,更有利芯片散热。AMD的EPYC CPU最早采用 MCM技术,由四颗Ziplline核心组成,并且用 infinite fabric互联。MCM 技术帮助AMD超越了同时代的Intel CPU。
- 板上光模块协会 COBO(Consortium for On-Board Optics):400G 接口有QSFP-DD和OSFP两种光模块,800G 接口(25.6T=32x800G)可能仅支持 OSFP 光模块。为了支持1.6T以上接口只能采用板上光模块COBO 方式(图中间)采用OBO,光信号更靠近交换芯片,减少PCB损耗。
- 硅光共封装Co-Packaged 技术:为了支持 51.2T 芯片,需要利用 100G PAM4 技术。随着频率升高,PCB 板上的铜线损耗急剧增加,需要消耗更多的电力来驱动。利用前几代芯片采用的类似MCM技 术,在一颗芯片里封装一个51.2T 的核心交换芯片,把多个小型 SerDes 芯片换成多个硅光芯片(光模块功能),光纤直接从芯片引出。采用这项新技术可以极大的降低功耗,但是这颗芯片散热量巨大,需要采用单独的循环液冷来冷却。
4.3 总结
本文以 Facebook 2010 年以来自建数据中心,Four Post, F4 到 F16架构演进为例,详细介绍了超大规模数据中心的典型设计和未来200G/400G Fabric,技术和设备演进。同时介绍了SDN Overlay 网络的一些新进展,Routing/ EVPN on the Host, Kubernetes SDN控制器Calico/Cilium和SRv6云**IPv6 Overlay设计。限于篇幅对DC自动化,Telemetry和Overlay智能网卡卸载等话题会单独成 文。最后本文作者对一些数据中心趋势的个人浅见:
开源操作系统:Sonic(微软牵头)如火如荼,DENT(AWS主推)初出茅庐,Cumulus是很流行 的商业Linux网络OS,网络操作系统怎么选?
首先说说共同点,1. 都基于 Linux 内核,从管理服务器(两个网卡接口)到交换机操作系统(32/48+个接口)无缝自动化体验。2.都采用 FRR 路由协议栈。随着FRR逐渐成熟 7.2版本支持BMP, BGP-LS,BGP Nexthop Group 等等,还要支持 BGP-PIC,SR,SRv6等等,逐渐跟业界顶尖路由协议栈实现拉近距离。
其中Sonic在云公司里开始流行,支持特性较多,适配所有芯片方案,需要中小型研发团队裁剪。DENT适合极简单稳定的BGP IP Fabric的云数据中心,越来越多的芯片解决驱动方案开始支持。Cumulus最多特性,比如VxLAN,MLAG,RoCE,BGP Unnumber等,最稳定,最多商用客户。三种操作系统,在数据中心BGP Only场景下都可用,需要选择相应的关心特性,成熟度和研发支持。
如果有一个顶级好用的SDN控制器,不需要单独交换机转发智能,流表变更用P4 Runtime下发,配置变更用gNMI/OpenConfig,管理接口采用gNOI还可以考虑Stratum(Google/Tencent)。FBOSS(Facebook)仅仅开源了一小部分Agent和接口管理和命令行,缺少协议栈,管理和监控等模块,也就是说仅仅开源了整个 Facebook交换机软件中的很小一部分,很难为其他公司所用。
P4/NPL SDN 编程接口:OTT云公司期望软硬件解耦,控制和转发解耦,希望网络也可以软件可编程,灵活增加新特性,适配各种复杂应用。十几年前,斯坦福的Nick教授在SIGCOMM 2008发表了一篇文章,采用Openflow作为SDN控制器下发转发指令到交换机,开始了第一代SDN在园区网络的创新尝试。由于很多传统交换机硬件表项下发速度很慢,同时使用on-chip TCAM来实现ACL表项,导致 Openflow流表数目很小(Google B4 改用 LPM),层出不穷的 VxLAN/GRE/MPLS, SR等新型协议头引入,需要等待新型芯片来解析报文头,Openflow无法来控制交换机解析新的报文头,对转发流程控制捉襟见肘。为了适应新一代可编程交换机的进展(Barefoot/Mellanox/Innovium等很多交换芯片都可以支持 P4),Nick和业界专家提出了P4编程语言来全面控制交换机 Pipeline报文解析,匹配不同字段,定义转发流程,定义转发表项,来实现复杂功能。实现不更换硬件 ASIC 来支持新型协议报文头。P4 不仅可以用于可编程交换机,更适合FPGA(Xilinx),NPU(Juniper),SmartNic(Mellanox / Pensando )等。对于云公司,一般采用BGP IP Fabric,Leaf/Spine 交换机上不需要经常引入新的协议报文处理,一般2/3年交换机ASIC 升级换代时可以引入新协议报文。所以P4应用在Leaf/Spine上意义不大,但是在云**和Host Overlay(智能网卡)上需要不断引入新的技术创新,P4在这个市场上有很多应用场景,未来看好支持P4的智能网卡来使能SDN(Software Defined Network), SDS(Software Defined Storage),SDSec(Software Defined Security)。主流的交换芯片厂商,Broadcom最新Jericho2和TD4,没有采用P4而是主推自家 NPL (Network Program Language),并号称可以支持多次逻辑表查找,查表无关动作,并行查表决策,查找结果检测等新特性。除了自家交换芯片,NPL 暂时还没有得到其他FPGA /SmartNic厂商支持。让我们拭目以待P4和NPL在云计算Data Path的编程语言之争。
大规模云数据中心Scale Out网络向200G/400G持续演进,引入了很多Underlay/Overlay 新技术, 新思路,新设计。AI和高端存储驱动以IPU为中心的新型异构云网络设计思路,越来越多的功能从 CPU卸载到智能网卡,软件定义的智能网卡成为创新引擎。云数据中心,云骨干网WAN SDN和云广域网接入SDWAN打通,网络拥塞流控通过Telemetry闭环反馈给云SDN控制器,云和网会进一步融合。如果希望跟作者讨论『Cloud/OTT SDN 网络架构』,请扫码入群。

![[good]](http://img.t.sinajs.cn/t4/appstyle/expression/ext/normal/8a/2018new_good_org.png)
收起总结的很好![[good]](http://img.t.sinajs.cn/t4/appstyle/expression/ext/normal/8a/2018new_good_org.png)
收起