【Notebook系列第七期】OpenVINO预训练模型的的下载和使用方法
 openlab_4276841a
更新于 4年前
openlab_4276841a
更新于 4年前
转自:OpenVINO中文社区
不知不觉,Notebook系列已经陪大家走过了六期,在这六期中,Nono和小伙伴们一起学会了语义分割、分类检测部署、文字检测等课程,可谓收获良多。
转眼间,Ethan老师携着第七期课程又来了,干货路漫漫,Nono将继续上下而求索,小伙伴们快点和Nono一起学习起来吧!

关于本期课程
本期课程目标:基于OpenVINO的Open Model Zoo去下载转化并且评估一个OpenVINO的预训练模型。
开发者小伙伴们应该都知道,在OpenVINO中有一个非常重要的组件叫做Open Model Zoo。在Open Model Zoo中,英特尔为大家提供了极丰富的预训练模型,其中包括英特尔第一方的预训练模型,也包括外部公开的预训练模型,这些预训练模型涵盖了视觉领域、自然语言处理领域等不同的应用场景。我们可以通过英特尔OpenVINO中的一些模型测试和下载工具,将模型下载下来,并进行进一步的验证和应用部署。
接下来,就让我们通过一个notebook来看看如何通过Open Model Zoo进行模型的下载和应用。
模型下载及工具学习
打开notebook,可以看到这个章节的名称叫Working with Open Model Zoo Models。也就是说,我们需要通过一些工具组件来完成对整个 Open Model Zoo中工具的使用和学习。
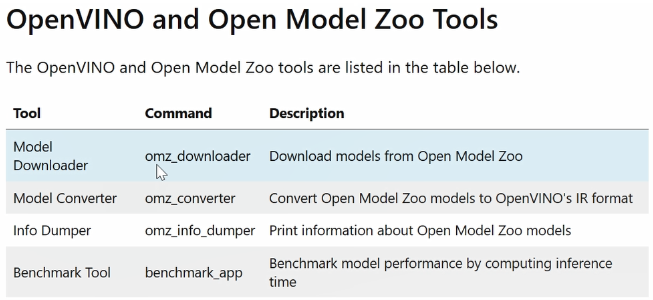
首先,可以看到第一个工具的名字叫做Model Downloader,Model Downloader顾名思义就是我们可以通过omz_downloader的命令去下载OpenVINO预训练模型。由于很多预训练模型来自于第三方,并且是以第三方支持的格式进行存储,所以我们需要通过Model Converter将这些第三方模型格式转化成OpenVINO支持的IR格式的中间表达式。
当我们将模型下载并且转化以后,可以通过Info Dumper命令,对模型的基本参数和信息进行查询。此外在Benchmark Tool中,我们预置了丰富的硬件和软件方面的配置参数,大家可以调整不同的配置参数,来找到最合适自己的应用的配置方式和配置模式。
操作示例

首先我们需要定义一个模型的名字,这边我们用到的是来自pytorch的mobilenet-v2这样一个分类任务,然后加载相应的依赖库,指定我们等一下需要保存模型的路径以及模型 cash的地址,以及最后模型的精度。
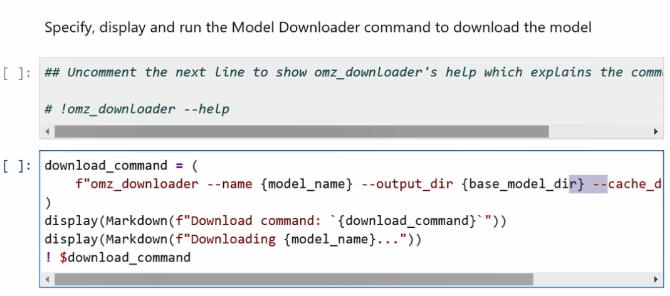
由于它是在python的环境下,所以我们会通过python这边的脚本去仿真在命令行中的命令输入,只需要输入omz_downloader这样一行命令,然后指定模型的名称、本地存储的路径,还有开始地址的路径,就可以轻松完成对模型的整个下载。

当下载完成后,我们会看到一条log信息。这个模型被存储在本地的一个叫open_model_zoo_ models这样一个路径下。由于它是来自第三方的模型库,所以我们这边会再添加一个子目录,把它显示成public。
接下来,我们需要通过model converter,将模型进行转化,使用方法也非常简单,就是指定模型名称,然后指定精度、它的本地路径,以及最后我们想输出得到IR格式的路径。
其实我们 model converter工具,就是将model optimizer工具做了一层封装,所以大家可以看到最后的输出结果其实是和model optimize的输出结果类似,最后我们也成功的将这个模型转化成了version 11的模型版本。
当我们完成模型转化以后,可以看一下模型的基本参数。通过info dumer 这行命令,我们可以了解到模型的名称、它的基本描述、它的原始的framework、它的license精度,还有它的目录(所在位置),以及它的任务属性等等。
接下来让我们运行一下 info dumper命令,可以看到我们整个模型的基本信息都被dump下来了。

首先是framework,它是来自pytorch的包括其相关的配置信息,包括我们针对accuracy_config的模型精度验证的配置文件,我们可以通过yml文件,通过我们OpenVINO中的accuracy-check,对模型的精度进行进一步的校验。此外,包括模型现在的精度情况、它的可被量化的精度的情况、它的目录、模型的基本输入信息,包括它的输入层layer的名字、它的input_shape以及它的layout等等。
接下来我们可以通过这些信息进一步的去对输入数据进行预处理,以实现对模型输入的匹配。
通过benchmark tool可以更进一步了解到模型在当前应用当前硬件平台上的性能表现,因此我们需要去跑一下 benchmark tool。
这边我们去模拟了一条命令行指令,首先就是benchmark_app的命令名称,然后是我们模型的输入路径,以及我们需要去运行的时间,这次我们会运行15秒钟,在15秒钟内,我们尽可能的去迭代多次的推理,或者迭代多次的推理请求,尽可能得到一个相对比较平均的参数值。
当benchmark_app运行完成后,我们会获取到一些精度表现,上面主要是部分log信息,比如运行的stream情况, stream是指模型是将几个CPU的core去执行的,然后模型的一些input的信息,我们是用一些随机的值去作为我们的模型的输入进行载入的,它的首次推理时间是在7.55毫秒,迭代了3000多轮,用时15毫秒,也是我们刚才预定义的。
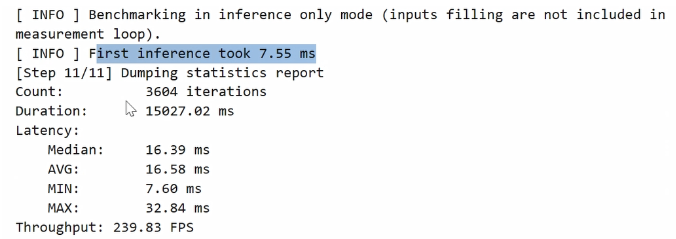
此外还有我们的latency,也就是延迟表现的平均值、中值、最小值和最大值,最后就是整个模型的吞吐量。
除了指定模型路径以及指定它的运行时长以外,我们还有很多其他的参数可以被配置。

我们举两个例子,第一个例子就是通过-d命令,我们可以去指定这个模型运行在哪个硬件平台上。此外我们也可以通过-api参数去指定它的运行模式,这边我们会去指定它可以是在异步模式或者同步模式上,异步模式可以获得更好的吞吐量表现,同步模式可以获得更佳的首次推理延迟。
此外我们还可以设置它的batch size,由于 GPU是一个并行能力比较强的设备,所以我们在配置GPU的时候最好把batch size设置大一点,以获得比较好的吞吐量性能。当然,可以被配置参数还有很多,大家可以通过benchmark_app--help去查询一下我们到底有哪些信息可以被配置。
接下来,我们可以将benchmark指令封装成一个python的函数接口,通过这个函数接口去对下面的测试进行进一步的调用。
我们来看一下这个平台上(有)哪些硬件资源,接下来再运行一下 CPU上的速度,我们将它的参数设置为CPU,由于这边的指令和我们之前运行的指令的整体性能应该是一致的,同样是运行15秒,同样是在CPU上执行,所以看到看到它的整体的表现是相近的。
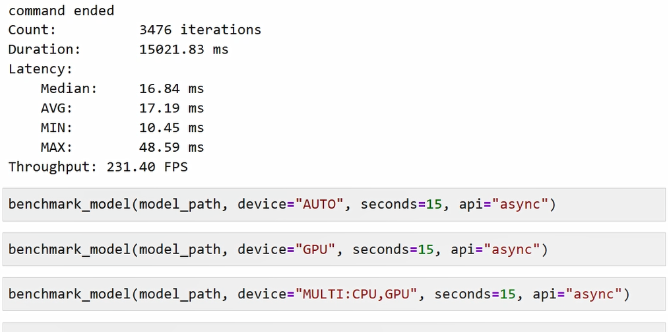
其实我们还有不同的这种运行的指令,包括通过auto接口去让我们的任务在CPU和GPU之间做来回的切换,实现负载的最大化。
此外,我们可以指定在GPU上运行,或者同时让命令来并行的运行在CPU和GPU上。由于整个测试过程会比较久,所以大家如果有兴趣的话,可以注意运行一下这些指令,看一下它们在不同的硬件部署的基础上,我们可以获得怎样的性能表现。