万物皆可分割——用OpenVINO™加速Segment Anythin
 小o
更新于 3年前
小o
更新于 3年前
作者:武卓博士
ChatGPT的火爆让大家看到了通用AI大模型的威力,也带动了近期一批自然语言处理(NLP)领域大模型的不断被推出。你方唱罢我登场,最近,计算机视觉领域也迎来了自己的物体分割大模型,由Meta开源的 “万物可分割 (Segment Anything, SAM)”物体分割模型。
物体分割是计算机视觉中的核心任务之一,旨在识别图像中属于特定对象的像素。通常实现图像分割的方法有两种,即交互式分割和自动分割。交互式分割可以对任何类别的对象进行分割,但需要人工引导,并通过反复精细化掩码来完成。而自动分割可以对预定义的特定对象类别进行分割,但需要大量手动标注的对象进行训练,同时需要大量的计算资源和具有技术专业知识的人员来训练分割模型。然而,这两种方法都没有提供一种通用的、完全自动的分割方法。
SAM是这两种方法的泛化,它是一个单一的模型,可以轻松地执行交互式分割和自动分割。SAM可以从输入提示(例如点或框)生成高质量的对象掩码,并且可以用于生成图像中所有对象的掩码。它已经在一个包含1.1亿个掩码的1100万个图像数据集上进行了训练,并且在各种分割任务上具有较强的零样本性能。它创建了一个通用的物体分割模型,可以在从分析科学图像到编辑照片各种应用程序中使用。

图1. SAM推理结果示例
这个强大的通用分割模型,我们的OpenVINO™当然也是可以对它进行优化以及推理的加速,使其可以方便快速地在英特尔®的CPU上部署运行起来。为了方便各位开发者的使用,我们同样提供了Jupyter Notebook形式的源代码,大家只需要跟随我们代码里的步骤,就可以在自己的机器上运行SAM,对图像进行任意分割了。
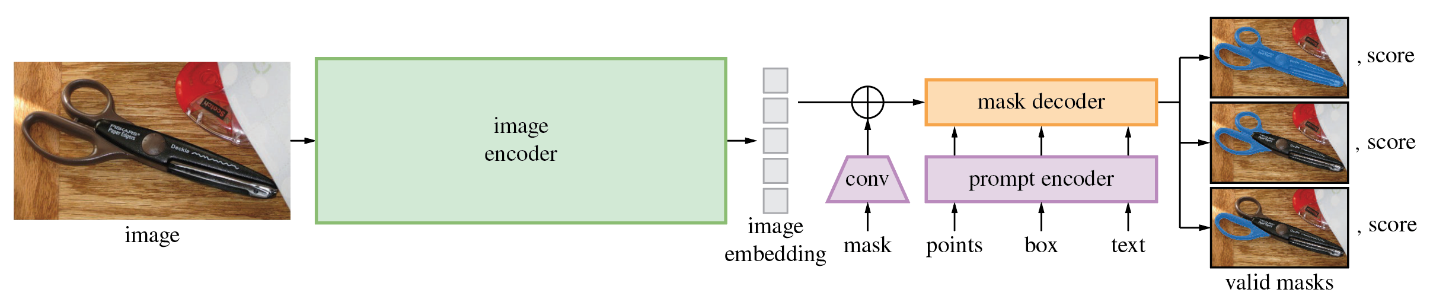
SAM模型由三个部分组成。
- 图像编码器(Image Encoder):这是一个Vision Transformer模型(VIT),使用Masked Auto Encoders方法(MAE)对图像进行编码,将图像转换为嵌入空间。图像编码器对每个图像运行一次,可以在向模型输入提示之前应用它。
- 提示编码器(Prompt Encoder ):这是一个用于分割条件的编码器。可以使用以下条件进行分割提示:
- 点(points)- 与应分割的对象相关的一组点。Prompt编码器使用位置编码将点转换为嵌入值。
- 框(boxes)- 应分割的对象所在的边界框。类似于points,边界框的坐标通过位置编码来进行编码。
- 分割掩码-由用户提供的分割掩码使用卷积进行嵌入,并与图像嵌入进行element-wise求和。
- 文本(text)- 由CLIP模型编码的文本表示。
- 掩码解码器(Mask Decoder) : 掩码解码器有效地将图像嵌入、提示嵌入和输出标记映射到掩码。
下图描述了SAM生成掩码的流程图。
接下来,我们一起来看看运行利用OpenVINO™来优化加速SAM的推理有哪些重点步骤吧。
注意:以下步骤中的所有代码来自OpenVINO Notebooks开源仓库中的237-segment-anything notebook 代码示例,您可以点击以下链接直达源代码。https://github.com/openvinotoolkit/openvino_notebooks/tree/main/notebooks/237-segment-anything
第一步: 安装相应工具包、加载模型并转换为OpenVINO IR格式
本次代码示例需要首先安装SAM相应工具包。
1. !pip install -q "segment_anything" "gradio>=3.25"
然后下载及加载相应的PyTorch模型。
有几个SAM checkpoint可供下载。在本次代码示例中,我们将使用基于vit_b的模型,但模型加载的方法是通用的,也适用于其他SAM模型。将下面的模型URL、保存checkpoint的路径和模型类型设置为对应的SAM模型checkpoint,然后使用SAM_model_registry加载模型。
1. import sys2. 3. sys.path.append("../utils")4. from notebook_utils import download_file5. 6. checkpoint = "sam_vit_b_01ec64.pth"7. model_url = "https://dl.fbaipublicfiles.com/segment_anything/sam_vit_b_01ec64.pth"8. model_type = "vit_b"9. 10. download_file(model_url)加载模型
1. from segment_anything import sam_model_registry2. 3. sam = sam_model_registry[model_type](checkpoint=checkpoint)正如我们已经讨论过的,每个图像可以使用一次图像编码器,然后可以多次运行更改提示、提示编码器和掩码解码器来从同一图像中检索不同的对象。考虑到这一事实,我们将模型分为两个独立的部分:image_encoder和mask_pr预测器(提示编码器和掩码解码器的组合)。
第二步: 定义图像编码器和掩码预测器
· 图像编码器输入是NCHW格式的形状为1x3x1024x1024的张量,包含用于分割的图像。图像编码器输出为图像嵌入,张量形状为1x256x64x64。代码如下
1. import warnings2. from pathlib import Path3. import torch4. from openvino.tools import mo5. from openvino.runtime import serialize, Core6. 7. core = Core()8. 9. ov_encoder_path = Path("sam_image_encoder.xml")10. 11. if not ov_encoder_path.exists():12. onnx_encoder_path = ov_encoder_path.with_suffix(".onnx")13. if not onnx_encoder_path.exists():14. with warnings.catch_warnings():15. warnings.filterwarnings("ignore", category=torch.jit.TracerWarning)16. warnings.filterwarnings("ignore", category=UserWarning)17. 18. torch.onnx.export(sam.image_encoder, torch.zeros(1,3,1024,1024), onnx_encoder_path)19. 20. ov_encoder_model = mo.convert_model(onnx_encoder_path, compress_to_fp16=True)21. serialize(ov_encoder_model, str(ov_encoder_path))22. else:23. ov_encoder_model = core.read_model(ov_encoder_path)24. ov_encoder = core.compile_model(ov_encoder_model)· 掩码预测器
本次代码示例需要导出的模型带有参数return_single_mask=True。这意味着模型将只返回最佳掩码,而不是返回多个掩码。对于高分辨率图像,这可以在放大掩码开销大的情况下提升运行时速度。
组合提示编码器和掩码解码器模型具有以下输入列表:
o image_embeddings:从image_encoder中嵌入的图像。具有长度为1的批索引。
o point_coords:稀疏输入提示的坐标,对应于点输入和框输入。方框使用两个点进行编码,一个用于左上角,另一个用于右下角。坐标必须已转换为长边1024。具有长度为1的批索引。
o point_labels:稀疏输入提示的标签。0是负输入点,1是正输入点,2是左上角,3是右下角,-1是填充点。*如果没有框输入,则应连接标签为-1且坐标为(0.0,0.0)的单个填充点。
模型输出:
o 掩码-预测的掩码大小调整为原始图像大小,以获得二进制掩码,应与阈值(通常等于0.0)进行比较。
o iou_predictions-并集预测上的交集。
o low_re***asks-后处理之前的预测掩码,可以用作模型的掩码输入。
第三步: 在交互式分割模式下运行OpenVINO 推理
加载分割用的测试图片。
1. import numpy as np2. import cv23. import matplotlib.pyplot as plt4. 5. download_file("https://raw.githubusercontent.com/facebookresearch/segment-anything/main/notebooks/images/truck.jpg")6. image = cv2.imread('truck.jpg')7. image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
原始图片如下,1. plt.figure(figsize=(10,10))2. plt.imshow(image)3. plt.axis('off')4. plt.show()
· 预处理及可视化函数定义:
为图像编码器准备输入,包含以下步骤:
o 将BGR图像转换为RGB
o 调整图像保存纵横比,其中最长尺寸等于图像编码器输入尺寸1024。
o 归一化图像减去平均值(123.675、116.28、103.53)并除以标准差(58.395、57.12、57.375)
o 将HWC数据布局转换为CHW并添加批次维度。
o 根据图像编码器预期的输入形状,按高度或宽度(取决于纵横比)向输入张量添加零填充。
· 视频编码
要开始处理图像,我们应该对其进行预处理,并使用ov_encoder获得图像嵌入。我们将在所有实验中使用相同的图像,因此可以运行一次视频编码、生成一次图像嵌入,然后重用它们。
1. preprocessed_image = preprocess_image(image)2. encoding_results = ov_encoder(preprocessed_image)3. 4. image_embeddings = encoding_results[ov_encoder.output(0)]现在,我们可以尝试为掩码生成提供不同的提示。
· 点输入举例
在本例中,我们选择一个点作为输入(input_point)。绿色星形符号在下图中显示了它的位置。
1. input_point = np.array([[500, 375]])2. input_label = np.array([1])3. 4. plt.figure(figsize=(10,10))5. plt.imshow(image)6. show_points(input_point, input_label, plt.gca())7. plt.axis('off')8. plt.show() 
添加一个批索引,连接一个填充点,并将其转换为输入张量坐标系。
1. coord = np.concatenate([input_point, np.array([[0.0, 0.0]])], axis=0)[None, :, :]2. label = np.concatenate([input_label, np.array([-1])], axis=0)[None, :].astype(np.float32)3. coord = resizer.apply_coords(coord, image.shape[:2]).astype(np.float32)将输入打包以在掩码预测器中运行.
1. inputs = {2. "image_embeddings": image_embeddings,3. "point_coords": coord,4. "point_labels": label,5. }预测一个掩码并设置阈值以获得二进制掩码(0-无对象,1-对象)。
1. results = ov_predictor(inputs)2. 3. masks = results[ov_predictor.output(0)]4. masks = postproces***ask***asks, image.shape[:-1])5. masks = masks > 0.0绘制结果
1. plt.figure(figsize=(10,10))2. plt.imshow(image)3. show_mask(masks, plt.gca())4. show_points(input_point, input_label, plt.gca())5. plt.axis('off')6. plt.show() 
· 多点输入举例
1. input_point = np.array([[500, 375], [1125, 625], [575, 750])2. input_label = np.array([1, 1, 1])模型输入的提示反应在测试图片上为
1. plt.figure(figsize=(10,10))2. plt.imshow(image)3. show_points(input_point, input_label, plt.gca())4. plt.axis('off')5. plt.show()
像上面单点输入的例子一样,讲输入点变换为张量坐标系,进而将输入打包成所需格式,最后获得的分割结果如下图所示

· 带负标签的框和点输入
在这个例中,我们使用边界框和边界框内的点来定义输入提示。边界框表示为其左上角和右下角的一组点。点的标签0表示该点应从掩码中排除。
1. input_box = np.array([425, 600, 700, 875])2. input_point = np.array([[575, 750]])3. input_label = np.array([0])反应在测试图片中为

添加批次索引,连接方框和点输入,为方框角添加适当的标签,然后进行变换。本次没有填充点,因为输入包括一个框输入。
1. box_coords = input_box.reshape(2, 2)2. box_labels = np.array([2,3])3. 4. coord = np.concatenate([input_point, box_coords], axis=0)[None, :, :]5. label = np.concatenate([input_label, box_labels], axis=0)[None, :].astype(np.float32)6. 7. coord = resizer.apply_coords(coord, image.shape[:2]).astype(np.float32)打包输入,并进行预测
1. inputs = {2. "image_embeddings": image_embeddings,3. "point_coords": coord,4. "point_labels": label,5. }6. 7. results = ov_predictor(inputs)8. 9. masks = results[ov_predictor.output(0)]10. masks = postproces***ask***asks, image.shape[:-1])11. masks = masks > 0.0结果如图所示

第四步: 在自动分割模式下运行OpenVINO 推理
由于SAM可以有效地处理提示,因此可以通过在图像上采样大量提示来生成整个图像的掩码。automatic_mask_generation函数实现了这一功能。它的工作原理是在图像上的网格中对单点输入提示进行采样,SAM可以从每个提示中预测多个掩码。然后,对掩码进行质量过滤,并使用非最大抑制进行去重复。额外的选项允许进一步提高掩模的质量和数量,例如对图像的多个裁剪进行预测,或对掩模进行后处理以去除小的断开区域和孔洞。。
1. from segment_anything.utils.amg import (2. MaskData, 3. generate_crop_boxes, 4. uncrop_boxes_xyxy, 5. uncrop_masks, 6. uncrop_points, 7. calculate_stability_score, 8. rle_to_mask, 9. batched_mask_to_box, 10. mask_to_rle_pytorch, 11. i***ox_near_crop_edge,12. batch_iterator,13. remove_**all_regions,14. build_all_layer_point_grids,15. box_xyxy_to_xywh,16. area_from_rle17. )18. from torchvision.op***oxes import batched_nms, box_area19. from typing import Tuple, List, Dict, Any在自动掩码生成中有几个可调参数,用于控制采样点的密度以及去除低质量或重复掩码的阈值。此外,生成可以在图像的裁剪上自动运行,以提高对较小对象的性能,后处理可以去除杂散像素和孔洞。
定义自动分割函数
1. def automatic_mask_generation(2. image: np.ndarray, min_mask_region_area: int = 0, points_per_side: int = 32, crop_n_layers: int = 0, crop_n_points_downscale_factor: int = 1, crop_overlap_ratio: float = 512 / 1500, box_nms_thresh: float = 0.7, crop_nms_thresh: float = 0.73. ) -> List[Dict[str, Any]]:4. """5. Generates masks for the given image.6. 7. Arguments:8. image (np.ndarray): The image to generate masks for, in HWC uint8 format.9. 10. Returns:11. list(dict(str, any)): A list over records for masks. Each record is12. a dict containing the following keys:13. segmentation (dict(str, any)&nbs******bsp;np.ndarray): The mask. If14. output_mode='binary_mask', is an array of shape HW. Otherwise,15. is a dictionary containing the RLE.16. bbox (list(float)): The box around the mask, in XYWH format.17. area (int): The area in pixels of the mask.18. predicted_iou (float): The model's own prediction of the mask's19. quality. This is filtered by the pred_iou_thresh parameter.20. point_coords (list(list(float))): The point coordinates input21. to the model to generate this mask.22. stability_score (float): A measure of the mask's quality. This23. is filtered on using the stability_score_thresh parameter.24. crop_box (list(float)): The crop of the image used to generate25. the mask, given in XYWH format.26. """27. point_grids = build_all_layer_point_grids(28. points_per_side,29. crop_n_layers,30. crop_n_points_downscale_factor,31. )32. mask_data = generate_masks(33. image, point_grids, crop_n_layers, crop_overlap_ratio, crop_nms_thresh)34. 35. # Filter **all disconnected regions and holes in masks36. if min_mask_region_area > 0:37. mask_data = postprocess_**all_regions(38. mask_data,39. min_mask_region_area,40. max(box_nms_thresh, crop_nms_thresh),41. )42. 43. mask_data["segmentations"] = [44. rle_to_mask(rle) for rle in mask_data["rles"]]45. 46. # Write mask records47. curr_anns = []48. for idx in range(len(mask_data["segmentations"])):49. ann = {50. "segmentation": mask_data["segmentations"][idx],51. "area": area_from_rle(mask_data["rles"][idx]),52. "bbox": box_xyxy_to_xywh(mask_data["boxes"][idx]).tolist(),53. "predicted_iou": mask_data["iou_preds"][idx].item(),54. "point_coords": [mask_data["points"][idx].tolist()],55. "stability_score": mask_data["stability_score"][idx].item(),56. "crop_box": box_xyxy_to_xywh(mask_data["crop_boxes"][idx]).tolist(),57. }58. curr_anns.append(ann)59. 60. return curr_anns运行自动分割预测
1. prediction = automatic_mask_generation(image)
以上automatic_mask_generation函数返回一个掩码列表,其中每个掩码都是一个包含有关掩码的各种数据的字典:
o 分割:掩码
o 面积:掩码的面积(以像素为单位)
o bbox:XYWH格式的掩码的边界框
o predicted_out:模型自己对掩模质量的预测
o point_coords:生成此掩码的采样输入点
o 稳定性核心:衡量掩码质量的一个附加指标
o crop_box:用于以XYWH格式生成此掩码的图像的裁剪
查看掩码的信息
1. print(f"Number of detected masks: {len(prediction)}")2. print(f"Annotation keys: {prediction[0].keys()}")获得如下结果

绘制最后的分割结果
1. from tqdm.notebook import tqdm2. 3. def draw_anns(image, anns):4. if len(anns) == 0:5. return6. segments_image = image.copy()7. sorted_anns = sorted(anns, key=(lambda x: x['area']), reverse=True)8. for ann in tqdm(sorted_anns):9. mask = ann["segmentation"]10. mask_color = np.random.randint(0, 255, size=(1, 1, 3)).astype(np.uint8)11. segments_image[mask] = mask_color12. return cv2.addWeighted(image.astype(np.float32), 0.7, segments_image.astype(np.float32), 0.3, 0.0)
1. import PIL2. 3. out = draw_anns(image, prediction)4. cv2.imwrite("result.png", out[:, :, ::-1])5. 6. PIL.Image.open("result.png")看看这些分割的效果,是不是非常的惊艳呢。其实除了以上我们介绍的代码内容,在我们的Jupyter Notebook代码里,还为大家提供了窗口式鼠标点击输入提示的交互式分割体验,甚至可以在手机端输入URL地址体验即时的互动效果,如下图所示

这么多有趣又快速的OpenVINO运行物体分割的方式,快在你本地的机器上克隆我们的代码示例,自己动手试试SAM的效果吧。
小结:
整个的步骤就是这样!现在就开始跟着我们提供的代码和步骤,动手试试用Open VINO 和SAM吧。
和SAM吧。
关于英特尔OpenVINOTM开源工具套件的详细资料,包括其中我们提供的三百多个经验证并优化的预训练模型的详细资料,请您点击https://www.intel.com/content/www/us/en/developer/tools/openvino-toolkit/overview.html
除此之外,为了方便大家了解并快速掌握OpenVINOTM的使用,我们还提供了一系列开源的Jupyter notebook demo。运行这些notebook,就能快速了解在不同场景下如何利用OpenVINOTM实现一系列、包括计算机视觉、语音及自然语言处理任务。OpenVINOTM notebooks的资源可以在GitHub这里下载安装:https://github.com/openvinotoolkit/openvino_notebooks 。
通知和免责声明
Intel技术可能需要启用硬件、软件或服务激活。
任何产品或组件都不能绝对安全。
您的成本和结果可能有所不同。
©英特尔公司。Intel、Intel徽标和其他Intel标志是Intel Corporation或其子公司的商标。其他名称和品牌可能被称为他人的财产。