[2023 Intel有奖征文] 基于Openvino Python API的FastSam模型的部署
 洋气的名字
更新于 2年前
洋气的名字
更新于 2年前
当今,深度学习技术在计算机视觉领域取得了巨大的突破,使得各种图像处理任务变得更加智能化。其中,Semantic Segmentation(语义分割)是一项重要的任务,它有助于计算机理解图像中不同对象的位置和边界。本文将介绍如何使用 OpenVINO™ Python API 部署 FastSAM 模型,以实现快速高效的语义分割。
什么是FastSAM模型?
FastSAM 模型是一种轻量级语义分割模型,旨在快速而准确地分割图像中的对象。它经过了精心设计,以在较低的计算成本下提供卓越的性能。这使得 FastSAM 模型成为许多计算机视觉应用的理想选择,包括自动驾驶、医学图像分析和工业自动化等领域。
步骤一:安装Openvino
要开始使用 OpenVINO™ 进行推理 FastSAM 模型,首先需要安装 OpenVINO™ Toolkit。OpenVINO™ 是英特尔发布的开源工具,专为深度学习模型部署而设计。
你可以按照以下步骤安装OpenVINO™ :访问OpenVINO官方网站下载OpenVINO工具包。按照官方文档的说明进行安装和配置PythonAPI版本。
步骤二:下载FastSAM官网模型
FastSAM 模型可以在官方 GitHub中找到。下载模型并将其解压缩到合适的文件夹。根据自身情况下载合适的预训练模型。
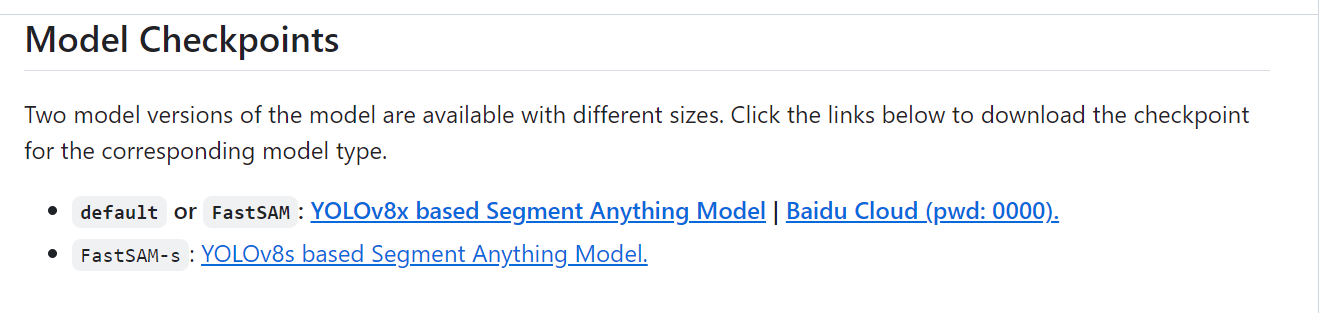
这里还需要将下载到的模型,由于这个模型是采用的pytorch 类型的格式,所以还需要将这个 pt 模型转换为 OpenVINO™ 的 IR 模型才能进行调用推理。
转换步骤如下所示:

需要先导出为 onnx 标准格式,然后经过这个压缩优化转化为 IR 模型。OpenVINO™ 官方提供一个模型转换工具 Model Optimizer,可以利用这个更加便捷的转换我们的模型。
例如:
mo --input_model FastSAM-s.onnx
就会在当前目录下生成对应的 FastSAM-***in 和 FastSAM-s.xml 文件,这就是所谓的 IR 模型了。
步骤三:使用OpenVINO Python API
接下来,我们将使用OpenVINO™ Python API来部署FastSAM 模型。由于官方提供的这个预训练模型也是基于yolov8进行优化的,所以也需要有和yolov8 相似推理的处理步骤:

1. 加载模型
加载模型需要创建一个 Core, 然后对模型进行读取编译:
core = ov.Core()
model = core.read_model(model=model_path)
compiled_model = core.compile_model(model = model, device_name=self.device) 2. 读取图像
我们使用 opencv 读取任意一张彩色图像:
Image = cv2.imread(“image_path”) 3. 预处理
预处理主要包括 3 部分,其一是将图像重新排列为模型所需要的类型(一般来说是 batch Size, channels, height, width), 其二是归一化图像大小为模型输入需求的大小, 其三是将 opencv 的图像原始数据放置到 numpy 类型的数据中方便处理。
以下是一个简单的 Python 预处理,展示了如何对输入的图像进行预处理:
def Preprocess(image: cv2.Mat, targetShape: list):
th, tw = targetShape
h, w = image.shape[:2]
if h>w:
scale = min(th / h, tw / w)
inp = np.zeros((th, tw, 3), dtype = np.uint8)
nw = int(w * scale)
nh = int(h * scale)
a = int((nh-nw)/2)
inp[: nh, a:a+nw, :] = cv2.resize(cv2.cvtColor(image, cv2.COLOR_BGR2RGB), (nw, nh))
else:
scale = min(th / h, tw / w)
inp = np.zeros((th, tw, 3), dtype = np.uint8)
nw = int(w * scale)
nh = int(h * scale)
a = int((nw-nh)/2)
inp[a: a+nh, :nw, :] = cv2.resize(cv2.cvtColor(image, cv2.COLOR_BGR2RGB), (nw, nh))
rgb = np.array([inp], dtype = np.float32) / 255.0
return np.transpose(rgb, (0, 3, 1, 2)) # 重新排列为batch_size, channels, height, width
4. 推理
推理部分只需要调用通过Core生成的compiled_model, 将预处理好的数据放入即可得到输出结果:
result = compiled_model([input]) 这只是一个同步的推理过程,有感兴趣深入研究的的同学可以参考官网的异步推理。
5. 后处理
后处理主要有两件事,第一是对输出的结果进行非极大抑制,第二是将抑制后的结果进行遍历处理掩膜。以下是一个简短的例子:
def Postprocess(preds, img, orig_imgs, retina_masks, conf, iou, agnostic_nms=False):
p = ops.non_max_suppression(preds[0],
conf,
iou,
agnostic_nms,
max_det=100,
nc=1)
results = []
proto = preds[1][-1] if len(preds[1]) == 3 else preds[1] # second output is len 3 if pt, but only 1 if exported
for i, pred in enumerate(p):
orig_img = orig_imgs[i] if isinstance(orig_imgs, list) else orig_imgs
# path = self.batch[0]
img_path = "ok"
if not len(pred): # save empty boxes
results.append(Results(orig_img=orig_img, path=img_path, names="segment", boxes=pred[:, :6]))
continue
if retina_masks:
if not isinstance(orig_imgs, torch.Tensor):
pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], orig_img.shape)
masks = ops.proces***ask_native(proto[i], pred[:, 6:], pred[:, :4], orig_img.shape[:2]) # HWC
else:
masks = ops.proces***ask(proto[i], pred[:, 6:], pred[:, :4], img.shape[2:], upsample=True) # HWC
if not isinstance(orig_imgs, torch.Tensor):
pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], orig_img.shape)
results.append(
Results(orig_img=orig_img, path=img_path, names="1213", boxes=pred[:, :6], mask***asks))
return results 这样就可以拿到这个掩码矩阵数据。
6. 绘制掩码
根据上面拿到的掩码矩阵,我们就可以绘制这个最终图像:
def overlay(image: np.ndarray, mask: np.ndarray, color: tuple, alpha: float, resize=None):
color = color[::-1]
colored_mask = np.expand_dim***ask, 0).repeat(3, axis=0)
colored_mask = np.moveaxis(colored_mask, 0, -1)
masked = np.ma.MaskedArray(image, mask=colored_mask, fill_value=color)
image_overlay = masked.filled()
if resize is not None:
image = cv2.resize(image.transpose(1, 2, 0), resize)
image_overlay = cv2.resize(image_overlay.transpose(1, 2, 0), resize)
return cv2.addWeighted(image, 1 - alpha, image_overlay, alpha, 0) 

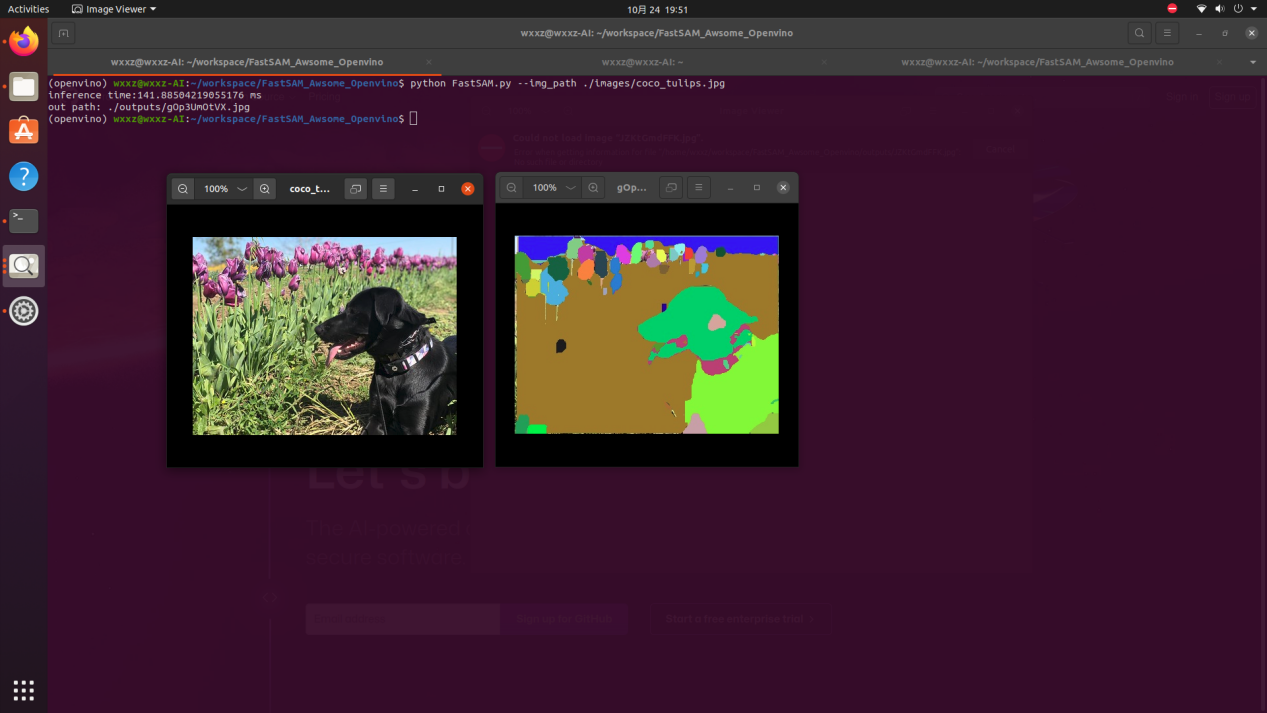
结语
本文介绍了如何使用 OpenVINO™ Python API 部署 FastSAM 模型在AIxBoard开发板上,以实现快速高效的语义分割。以在较低的计算成本下提供卓越的性能。这使得 FastSAM 模型成为许多计算机视觉应用的理想选择,包括自动驾驶、医学图像分析和工业自动化等领域。