基于OpenVINO和LangChain构建RAG问答系统
 openlab_4276841a
更新于 2年前
openlab_4276841a
更新于 2年前
作者:杨亦诚
背景
随着生成式AI的兴起,和大语言模型对话聊天的应用变得非常热门,但这类应用往往只能简单地和你“聊聊家常”,并不能针对某些特定的行业,给出非常专业和精准的答案。这也是由于大语言模型(以下简称LLM)在时效性和专业性上的局限所导致,现在市面上大部分开源的LLM几乎都只是使用某一个时间点前的公开数据进行训练,因此它无法学习到这个时间点之后的知识,并且也无法保证在专业领域上知识的准确性。那有没有办法让你的模型学习到新的知识呢?
当然有,这里一般有2种方案:
1. Fine-tuning微调:微调通过对特定领域数据库进行广泛的训练来调整整个模型。这样可以内化专业技能和知识。然后,微调也需要大量的数据、大量的计算资源和定期的重新训练以保持时效性。
2. RAG检索增强生成:RAG的全称是Retrieval-Augmented Generation,它的原理是通过检索外部知识来给出上下文响应,在无需对模型进行重新训练的情况,保持模型对于特定领域的专业性,同时通过更新数据查询库,可以实现快速地知识更新。但RAG在构建以及检索知识库时,会占用更多额外的内存资源,其回答响应延时也取决于知识库的大小。
从以上比较可以看出,在没有足够GPU计算资源对模型进行重新训练的情况下,RAG方式对普通用户来说更为友好。因此本文也将探讨如何利用OpenVINO™以及LangChain工具来构建属于你的RAG问答系统。
RAG流程
虽然RAG可以帮助LLM“学习”到新的知识,并给出更可靠的答案,但它的实现流程并不复杂,主要可以分为以下两个部分:
1. 构建知识库检索
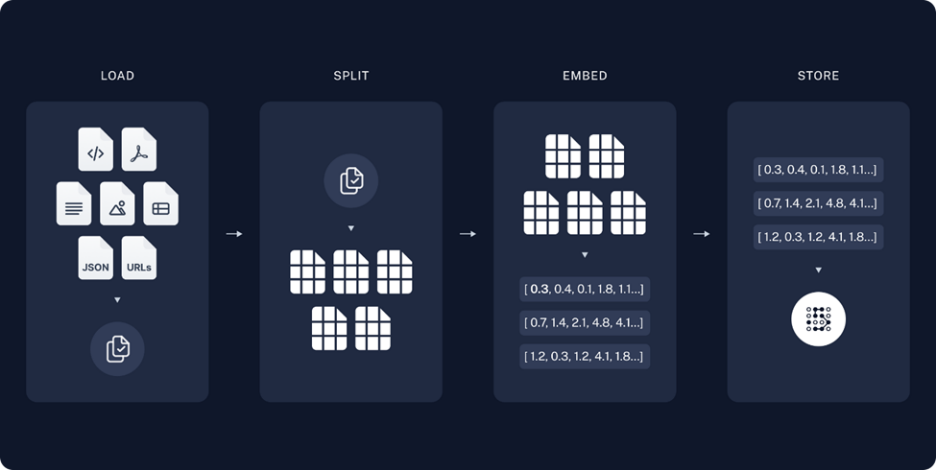
图:构建知识库流程
· Load载入:读取并解析用户提供的非结构化信息,这里的非结构化信息可以是例如PDF或者Markdown这样的文档形式。
· Split分割:将文档中段落按标点符号或是特殊格式进行拆分,输出若干词组或句子,如果拆分后的单句太长,将不便于后期LLM理解以及抽取答案,如果太短又无法保证语义的连贯性,因此我们需要限制拆分长度(chunk size),此外,为了保证chunk之间文本语义的连贯性, 相邻chunk会有一定的重叠,在LangChain中我可以通过定义Chunk overlap来控制这个重叠区域的大小。
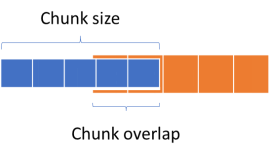
图:Chunk size和Chunk overlap示例
· Embedding向量化:使用深度学习模型将拆分后的句子向量化,把一段文本根据语义在一个多维空间的坐标系里面表示出来,以便知识库存储以及检索,语义将近的两句话,他们所对应的向量相似度会相对较大,反之则较小,以此方式我们可以在检索时,判断知识库里句子是否可能为问题的答案。
· Store存储:构建知识库,将文本以向量的形式存储,用于后期检索。
2. 检索和答案生成
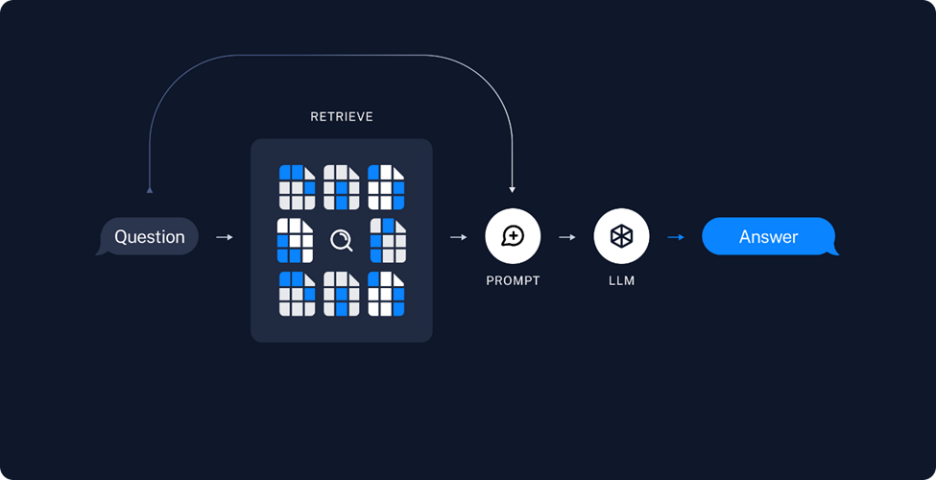
图:答案生成流程
· Retrieve检索:当用户问题输入后,首先会利用embedding模型将其向量化,然后在知识库中检索与之相似度较高的若干段落,并对这些段落的相关性进行排序。
· Generate生成:将这个可能包含答案,且相关性最高的Top K个检索结果,包装为Prompt输入,喂入LLM中,据此来生成问题所对应的的答案。
关键步骤
在利用OpenVINO™构建RAG系统过程中有以下一些关键步骤:
1. 封****>Embedding模型类
由于在LangChain的chain pipeline会调用embedding模型类中的embed_documents和embed_query来分别对知识库文档和问题进行向量化,而他们最终都会调用encode函数来实现每个chunk具体的向量化实现,因此在自定义的embedding模型类中也需要实现这样几个关键方法,并通过OpenVINO™进行推理任务的加速。
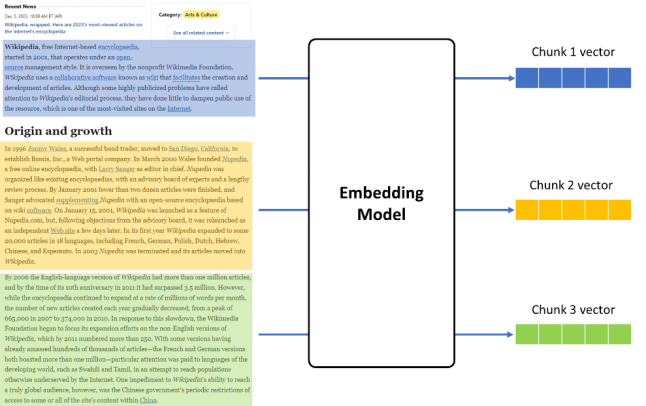
图:embedding模型推理示意
由于在RAG系统中的各个chunk之间的向量化任务往往没有依赖关系,因此我们可以通过OpenVINO™的AsyncInferQueue接口,将这部分任务并行化,以提升整个embedding任务的吞吐量。
for i, sentence in enumerate(sentences_sorted):
inputs = {}
features = self.tokenizer(
sentence, padding=True, truncation=True, return_tensors='np')
for key in features:
inputs[key] = features[key]
infer_queue.start_async(inputs, i)
infer_queue.wait_all()
all_embeddings = np.asarray(all_embeddings) 此外,从HuggingFace Transfomers库中(https://hf-mirror.com/sentence-transformers/all-mpnet-base-v2#usage-huggingface-transformers)导出的embedding模型是不包含mean_pooling和归一化操作的,因此我们需要在获取模型推理结果后,再实现这部分后处理任务。并将其作为callback function与AsyncInferQueue进行绑定。
def postprocess(request, userdata):
embeddings = request.get_output_tensor(0).data
embeddings = np.mean(embeddings, axis=1)
if self.do_norm:
embeddings = normalize(embeddings, 'l2')
all_embeddings.extend(embeddings)
infer_queue.set_callback(postprocess) 2. 封****>LLM模型类
由于LangChain已经可以支持HuggingFace的pipeline作为其LLM对象,因此这里我们只要将OpenVINO™的LLM推理任务封装成一个HF的text generation pipeline即可(详细方法可以参考我的上一篇文章)。此外为了流式输出答案(逐字打印),需要通过TextIteratorStreamer对象定义一个流式生成器。
streamer = TextIteratorStreamer(
tok, timeout=30.0, skip_prompt=True, skip_special_tokens=True
)
generate_kwargs = dict(
model=ov_model,
tokenizer=tok,
max_new_tokens=256,
streamer=streamer,
# temperature=1,
# do_sample=True,
# top_p=0.8,
# top_k=20,
# repetition_penalty=1.1,
)
if stop_tokens is not None:
generate_kwargs["stopping_criteria"] = StoppingCriteriaList(stop_tokens)
pipe = pipeline("text-generation", **generate_kwargs)
llm = HuggingFacePipeline(pipeline=pipe) 3. 设计RAG prompt template
当完成检索后,RAG会将相似度最高的检索结果包装为Prompt,让LLM进行筛选与重构,因此我们需要为每个LLM设计一个RAG prompt template,用于在Prompt中区分这些检索结果,而这部分的提示信息我们又可以称之为context上下文,以供LLM在生成答案时进行参考。以ChatGLM3为例,它的RAG prompt template可以是这样的:
"prompt_template": f"""<|system|>
{DEFAULT_RAG_PROMPT_CHINESE }"""
+ """
<|user|>
问题: {question}
已知内容: {context}
回答:
<|assistant|>""", 其中:
· {DEFAULT_RAG_PROMPT_CHINESE}为我们事先根据任务要求定义的系统提示词。
· {question}为用户问题。
· {context}为Retriever检索到的,可能包含问题答案的段落。
例如,假设我们的问题是“飞桨的四大优势是什么?”,对应从飞桨文档中获取的Prompt输入就是:
“<|system|>
基于以下已知信息,请简洁并专业地回答用户的问题。如果无法从中得到答案,请说 "根据已知信息无法回答该问题" 或 "没有提供足够的相关信息"。不允许在答案中添加编造成分。另外,答案请使用中文。
<|user|>
问题: 飞桨的四大领先技术是什么?
已知内容: ## 安装
PaddlePaddle最新版本: v2.5
跟进PaddlePaddle最新特性请参考我们的版本说明
四大领先技术
开发便捷的产业级深度学习框架
飞桨深度学习框架采用基于编程逻辑的组网范式,对于普通开发者而言更容易上手,符合他们的开发习惯。同时支持声明式和命令式编程,兼具开发的灵活性和高性能。网络结构自动设计,模型效果超越人类专家。
支持超大规模深度学习模型的训练
飞桨突破了超大规模深度学习模型训练技术,实现了支持千亿特征、万亿参数、数百节点的开源大规模训练平台,攻克了超大规模深度学习模型的在线学习难题,实现了万亿规模参数模型的实时更新。
查看详情
支持多端多平台的高性能推理部署工具
…
<|assistant|>“
4. 创建RetrievalQA检索
在文本分割这个任务中,LangChain支持了多种分割方式,例如按字符数的CharacterTextSplitter,针对Markdown文档的MarkdownTextSplitter,以及利用递归方法的RecursiveCharacterTextSplitter,当然你也可以通过继成TextSplitter父类来实现自定义的split_text方法,例如在中文文档中,我们可以采用按每句话中的标点符号进行分割。
class ChineseTextSplitter(CharacterTextSplitter):
def __init__(self, pdf: bool = False, **kwargs):
super().__init__(**kwargs)
self.pdf = pdf
def split_text(self, text: str) -> List[str]:
if self.pdf:
text = re.sub(r"\n{3,}", "\n", text)
text = text.replace("\n\n", "")
sent_sep_pattern = re.compile(
'([﹒﹔﹖﹗.。!?]["’”」』]{0,2}|(?=["‘“「『]{1,2}|$))') # del :;
sent_list = []
for ele in sent_sep_pattern.split(text):
if sent_sep_pattern.match(ele) and sent_list:
sent_list[-1] += ele
elif ele:
sent_list.append(ele)
return sent_list 接下来我们需要载入预先设定的好的prompt template,创建rag_chain。
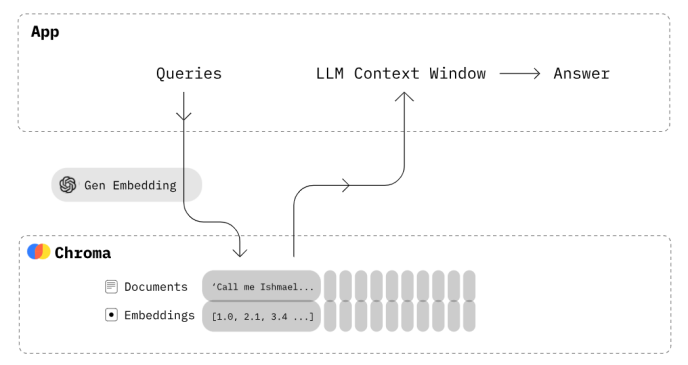
图:Chroma引擎检索流程
这里我们使用Chroma作为检索引擎,在LangChain中,Chroma默认使用cosine distance作为向量相似度的评估方法, 同时可以通过调整db.as_retriever(search_type= "similarity_score_threshold"),或是db.as_retriever(search_type= "mmr")来更改默认搜索策略,前者为带阈值的相似度搜索,后者为max_marginal_relevance算法。当然Chroma也可以被替换为FAISS检索引擎,使用方式也是相似的。
此外通过定义as_retriever 函数中的{"k": vector_search_top_k},我们还可以改变检索结果的返回数量,有助于帮助LLM获取更多有效信息,但也为增加Prompt的长度,提高推理延时,因此不建议将该数值设定太高。创建rag_chain的完整代码如下:
documents = load_single_document(doc.name)
text_splitter = TEXT_SPLITERS[spliter_name](
chunk_size=chunk_size, chunk_overlap=chunk_overlap
)
texts = text_splitter.split_documents(documents)
db = Chroma.from_documents(texts, embedding)
retriever = db.as_retriever(search_kwargs={"k": vector_search_top_k})
global rag_chain
prompt = PromptTemplate.from_template(
llm_model_configuration["prompt_template"])
chain_type_kwargs = {"prompt": prompt}
rag_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
chain_type_kwargs=chain_type_kwargs,
) 5. 答案生成
创建以后的rag_chain对象可以通过rag_chain.run(question)来响应用户的问题。将它和线程函数绑定后,就可以从LLM对象的streamer中获取流式的文本输出。
def infer(question):
rag_chain.run(question)
stream_complete.set()
t1 = Thread(target=infer, args=(history[-1][0],))
t1.start()
partial_text = ""
for new_text in streamer:
partial_text = text_processor(partial_text, new_text)
history[-1][1] = partial_text
yield history 最终效果
最终效果如下图所示,当用户上传了自己的文档文件后,点击Build Retriever便可以创建知识检索库,同时也可以根据自己文档的特性,通过调整检索库的配置参数来实现更高效的搜索。当完成检索库创建后就可以在对话框中与LLM进行问答交互了。
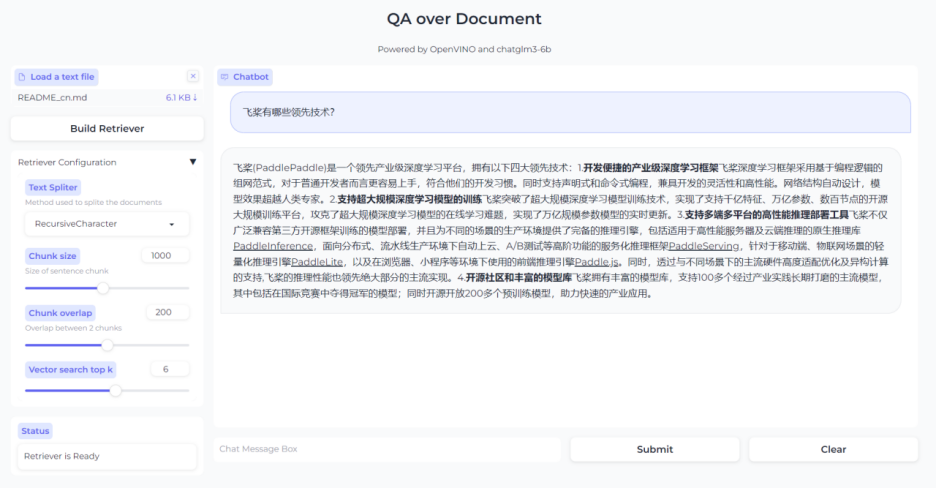
图:基于RAG的问答系统效果
总结
在医疗、工业等领域,行业知识库的构建已经成为了一个普遍需求,通过LLM与OpenVINO™的加持,我们可以让用户对于知识库的查询变得更加精准与高效,带来更加友好的交互体验。
参考资料
· LangChian RAG:https://python.langchain.com/docs/use_cases/question_answering/
· OpenVINO异步API:https://docs.openvino.ai/2023.2/openvino_docs_OV_UG_Python_API_exclusives.html#asyncinferqueue