隆重介绍OpenVINO 2024.0: 为开发者提供更强性能和扩展支持
 openlab_96bf3613
更新于 2年前
openlab_96bf3613
更新于 2年前
作者:武卓 英特尔 AI 软件布道师
欢迎来到OpenVINO 2024.0,我们很高兴在这里推出一系列增强功能,旨在在快速发展的人工智能领域为开发者赋能!此版本通过动态量化、改进的GPU优化以及对混合专家架构的支持,增强了大语言模型(LLM)的性能。OpenVINO 2024.0使开发者能够有效利用人工智能加速,并对来自社区的持续贡献表示感谢。
大语言模型推理的提升
大语言模型(LLM)没有消失的迹象,模型和使用用例不断涌现。我们将继续我们的使命,以便加速模型,并使这些模型的推理更加经济实惠。
性能和准确性的提升
在本版本中,我们一直致力于提高LLM的开箱即用性能,并对运行时和工具进行了一些重要更改。
首先,我们介绍了CPU平台的动态量化和缓存压缩机制。KV缓存压缩功能使我们更高效地生成大序列。动态量化通常会提高模型其它部分(嵌入映射和前馈网络)的计算和内存消耗。
对于GPU平台,我们还通过在内核和整个堆栈中引入优化来改进生成特性。我们还实现了更高效的缓存处理,这有助于使用波束搜索生成。
其次,虽然性能一直是一个讨论的话题,但准确性也至关重要。我们提高了NNCF中权重压缩算法的准确性。我们介绍了使用数据集的统计数据压缩权重的能力,并介绍了AWQ算法的实现,以进一步提高准确性。此外,通过我们与Hugging Face Optimum Intel的集成,您现在可以直接通过Transformers API压缩模型,如下所示:
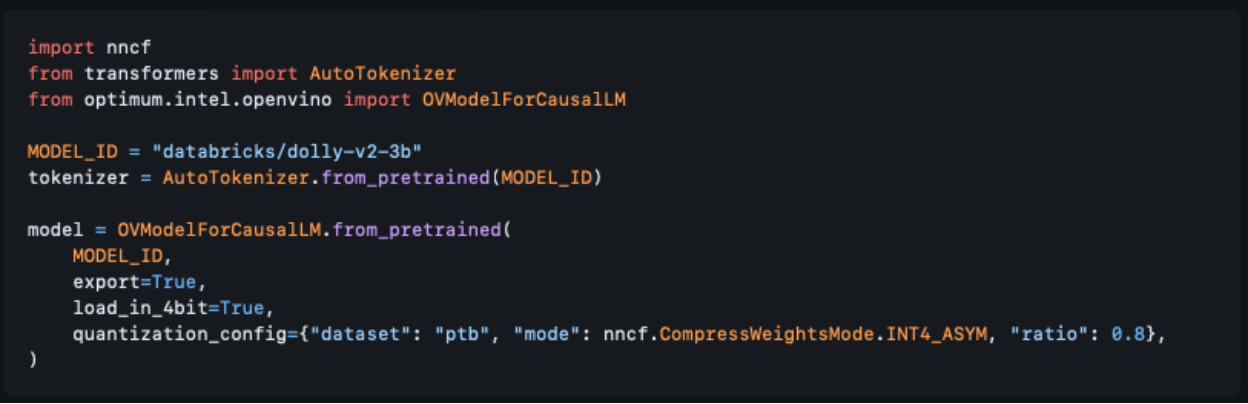
(此处的代码来源:https://github.com/huggingface/optimum-intel/pull/538)
注意:使用设置为True的load_in_4bit选项,并在对from_pretrained方法的调用中传递quantiation_config权限,这将为您完成所有压缩工作。更重要的是,我们已经为大多数热门的模型添加了量化配置,其中包括Llama2、StableLM、ChatGLM和QWEN等模型;因此,对于这些模型,您根本不需要传递config来获得4位压缩。
想了解关于我们的算法质量的更多信息,您可以查询OpenVINO文档 或者 GitHub上的NNCF 文档。
支持混合专家(MoE)架构
混合专家(MoE)代表了下一个主要的体系架构演变,它为LLM带来了更好的准确性和性能。它从Mixtral开始,并迅速发展到更多的模型和框架,允许从现有模型创建基于MoE的模型。在整个2024.0版本中,我们一直致力于启用这些体系结构并提高性能。我们不仅对这些模型进行了有效的转换,而且还更改了一些内部结构,以更好地处理运行时内专家的动态选择。
我们正在对Hugging Face Optimum-Intel进行升级,以使这些模型的转换是透明的。
对新平台的变化以及现有平台的增强
Intel NPU更广泛的接入
随着Intel®Core™Ultra的发布,我们的NPU加速器终于跟广大的开发者见面了。从软件和硬件的角度来看,这是一款不断发展的产品,我们对它所能实现的功能感到兴奋。您可能已经看到了一些在NPU上运行的OpenVINO™ Notebooks的演示(OpenVINO™ notebooks running on NPU)。
在本版本中,当您通过我们最热门的分发渠道PyPI安装OpenVINO™时,我们将提供NPU支持。有几点需要注意:
· NPU要求在系统中安装驱动程序,因此如果您打算使用它,请确保遵循此简短指南
· NPU目前不包括在自动设备选择逻辑中,因此,如果您计划在NPU上运行您的模型,请确保您明确指定设备名称(例如NPU),如下所示:
compiled_model = core.compile_model(model=model, device_name="NPU") 改进对ARM CPU的支持
线程是我们在ARM平台上没有有效实现的事情之一,这拖慢了我们的性能。我们与oneTBB团队(我们默认的线程引擎提供商)合作,改变了对ARM的支持,并显著提高了我们的性能。同时,在对某些操作的精度进行了一些研究后,我们在ARM CPU上默认启用了fp16作为推理精度。
总的来说,这意味着ARM CPU的性能更高,也意味着OpenVINO Streams功能的实现,该功能允许在多核平台上获得更高的吞吐量。
删除一些遗留项
2024.0是我们的下一个主要版本,传统上这是我们从工具套件中删除过时组件的时候。
2年前,我们大幅度改变了API以跟上深度学习领域的发展。但为了最大限度地减少对使用OpenVINO™的现有开发者和产品的影响,我们也支持API 1.0。从那以后发生了很多变化,我们现在正在完全删除旧的API。更重要的是,我们还删除了标记为弃用的工具。这包括:
· 训练后量化工具,也称为POT。
· 准确性检查框架
· 部署管理器
这些工具是openvino-dev包的一部分,这个包已经有一段时间没有强制使用了。我们将为那些继续使用我们的离线模型转换工具model Optimizer的用户保留它。
如果您无法迁移到新的API,那么您很有可能继续使用我们的一个长期支持版本,例如2023.3。
新的及修改过的Notebook****>
我们将继续展示人工智能领域最重要的更新,以及如何利用OpenVINO™来加速这些场景。以下是我们一直在做的工作:
· Mobile language assistant with MobileVLM
· Depth estimation with DepthAnything
· Multimodal Large Language Models (MLLM) Ko**os-2
· Zero-shot Image Classification with SigLIP
· Personalized image generation with PhotMaker
· Voice tone cloning with OpenVoice
· Line-level text detection with Surya
· Zero-shot Identity-Preserving Generation with InstantID
· LLM chatbot 和 LLM RAG pipeline已通过新模型的集成进行了更新:minicpm-2b-dpo、gemma-7b-it、qwen1.5-7b-chat、baichuan2-7b-chat
感谢您,我们的开发者和贡献者!
在OpenVINO的历史上,我们看到了许多激动人心的项目!我们决定列出一份使用OpenVINO™的绝妙项目列表,它还在继续快速增长着!为您的项目创建一个拉取请求,使用您的项目的“mentioned in Awesome”徽章,并与我们分享您的经验!
我们的开发人员基数正在增长,我们感谢社区正在做出的所有改变和改进。令人惊讶的是,你们中的一些人已经明确表示“正忙于帮助改进OpenVINO™”,谢谢!
我们的贡献者所做工作的一个例子是openSUSE平台中的OpenVINO支持。
然而,在过去的几周里,我们面临着一个重大问题——我们无法足够快地填充Good First Issues并审查拉取请求!我们认识到这个问题,并将更加努力地解决它,希望大家持续关注。
此外,我们正在为谷歌代码之夏(Google Summer of Code)做准备,并从您那里获得非常有趣的项目提案!在我们把你的想法发送出去审批之前,还有时间提交您的想法。
在这个版本中,我们挚爱的贡献者列表发布在 GitHub 上。
通知和免责声明
性能因使用情况、配置和其他因素而异。如需了解详情,请访问性能检索网站。
性能结果基于截止配置中显示日期的测试,可能无法反映所有公开可用的更新。 有关配置详细信息,请参阅备份。 没有任何产品或组件是绝对安全的。
您的成本和结果可能会有所不同。 英特尔技术可能需要支持的硬件、软件或服务激活。
© 英特尔公司。 英特尔、英特尔徽标和其他英特尔标志是英特尔公司或其子公司的商标。 其他名称和品牌可能是其他公司的财产。