借助OpenVINO™ 在NPU上运行BGE embedding模型,提升RAG整体性能
 openlab_96bf3613
更新于 1年前
openlab_96bf3613
更新于 1年前
作者:杨亦诚
BGE全称是BAAI General Embedding,即北京智源人工智能研究院通用Embedding模型,它可以将任意文本映射到低维的稠密向量,在文本向量化任务中得到了广泛的应用。可以看到在C-MTEB中文排行榜中,BGE系列模型的综合能力名列前茅,而在MTEB排行榜所有小于500MB的模型列表中,基于相同模型结构的BGE英文版本bge-large-en-v1.5的综合能力也能位列前五。
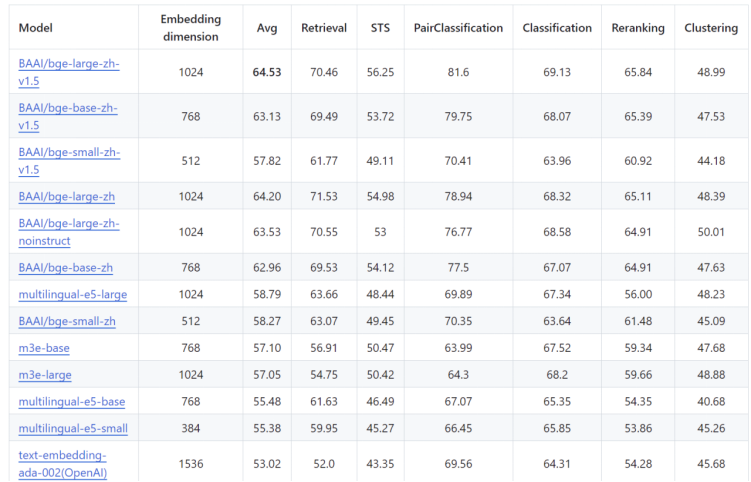
图:BGE模型性能指标
而作为英特尔AIPC架构中专用的AI处理器,NPU相较于CPU拥有更高的算力,并能以更低的能耗来运行深度学习模型。在类似RAG等的复杂任务中,我们往往需要利用Embedding, LLM, Ranker等多个模型 协同处理数据,通过将Embedding模型部署在NPU上,可以进一步优化其性能和能耗。OpenVINOTM作为目前唯一可以同时在Intel CPU, GPU以及NPU平台上部署AI模型的工具套件,提供了一套通用API接口函数,方便开发者灵活地调度AIPC上的异构资源。本文将分享如何利用 OpenVINOTM 工具套件在NPU上部署BGE Embedding模型。
示例完整代码:https://github.com/openvinotoolkit/openvino_notebooks/tree/latest/notebooks/llm-rag-langchain
模型转换
利用Optimum-intel命令行工具,我们便可以非常快速将BGE embedding模型导出为OpenVINOTM的IR格式文件。这里只需要指定模型的Hugging Face ID或是本地路径,以及任务类别为feature-extraction。
optimum-cli export openvino --model bge-large-zh-v1.5 --task feature-extraction bge-**all-zh-v1.5 当以上命令执行完毕后,IR格式模型以及对应的tokenizer文件将被保存在bge-large-zh-v1.5目录下:
├── config.json
├── openvino_model.bin
├── openvino_model.xml
├── special_token***ap.json
├── tokenizer_config.json
├── tokenizer.json
└── vocab.txt
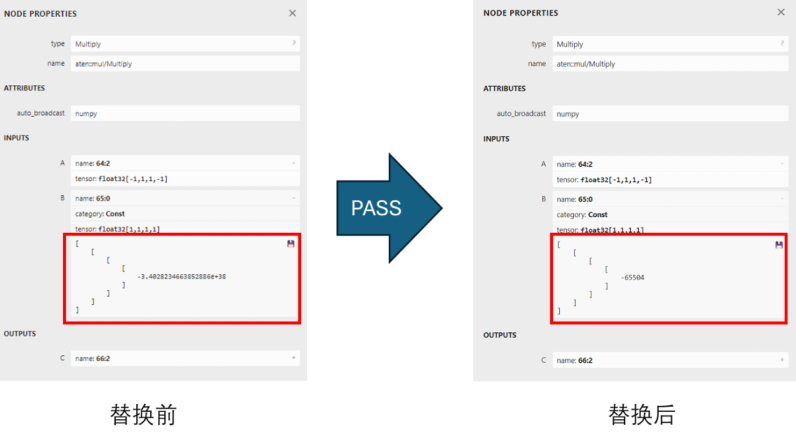
由于 NPU 中的所有数据都将被转到到 fp16 精度进行计算,而 BGE Embedding 模型的原始精度是FP32,因此在FP32转FP16的过程中部分超过FP16表达范围的值会溢出,例如一个极小的负数,BGE Embedding也同样存在这个问题,所以这里我们会将这种类型的 Tensor 利用 OpenVINOTM 的 Transformation pass 机制进行替换。
模型部署
接下来就是推理任务部署了,由于截至发文前NPU尚未完全支持动态输入的模型,因此我们在读取BGE模型后,需要将其每一个input shape进行固定,此外在处理原始文本输入的时候,也需要通过加Padding的方式,统一文本长度以匹配模型的input shape。这里我们以LangChain中集成的OpenVINOTM Embedding模型为例:
· 通过Tokenizer处理输入字符串
首先判断模型的input shape是否为静态的,如果是静态的,则基于其支持的向量长度,通过BGE模型自带的的Tokenizer进行padding,也就是对原始input token外的内容用特殊字符进行补足,直到满足模型input shape长度。
length = self.ov_model.request.inputs[0].get_partial_shape()[1]
if length.is_dynamic:
features = self.tokenizer(
sentence***atch, padding=True, truncation=True, return_tensors="pt"
)
else:
features = self.tokenizer(
sentence***atch,
padding="max_length",
max_length=length.get_length(),
truncation=True,
return_tensors="pt",
) · 对模型进行reshape
在调用LangChain中的OpenVINOTM embedding对象时,我们需要指定"compile": False,然后将模型对象的input tensor进行reshape,固定其batch size和token长度,最后重新compile编译。
embedding.ov_model.reshape(1, 512)
embedding.ov_model.compile() 测试对比
接下来我们以CPU执行FP32的动态输入模型的结果为基准,比较NPU运行静态输入模型的结果,以此验证模型在NPU上执行的准确性。
在开始测试前,我们需要确保当前NPU的驱动版本为最新,大家可以通过以下链接下载最新的NPU驱动,https://www.intel.cn/content/www/cn/zh/download/794734/intel-npu-driver-windows.html ,本次测试中使用的驱动版本为:32.0.100.2408。
这里我们也可以直接使用LangChain中的OpenVINOBgeEmbeddings模块进行测试。具体代码如下
from langchain_community.embeddings import OpenVINOBgeEmbeddings
embedding_model_name = npu_embedding_dir if USING_NPU else embedding_model_id.value
batch_size = 1 if USING_NPU else 4
embedding_model_kwargs = {"device": embedding_device.value, "compile": False}
encode_kwargs = {
"mean_pooling": embedding_model_configuration["mean_pooling"],
"normalize_embeddings": embedding_model_configuration["normalize_embeddings"],
"batch_size": batch_size,
}
embedding = OpenVINOBgeEmbeddings(
model_name_or_path=embedding_model_name,
model_kwargs=embedding_model_kwargs,
encode_kwargs=encode_kwargs,
)
if USING_NPU:
embedding.ov_model.reshape(1, 512)
embedding.ov_model.compile()
text = "This is a test document."
embedding_result = embedding.embed_query(text)
embedding_result[:3] 该示例中我们需要将NPU上模型输入batch size限定为1,并比较BGE embedding模型在执行相同输入文本时的结果与误差。
· NPU输出embedding向量的前三位:
[-0.031266361474990845, 0.014588160440325737, 0.015173986554145813]
· CPU输出embedding向量的前三位:
[-0.031454551964998245, 0.014539799652993679, 0.015147135592997074]
· NPU与CPU输出的embedding向量误差总和:
0.04240982816008909
· NPU与CPU输出的embedding向量误差均值:
8.2831695625174e-05
可以看到虽然NPU上的BGE模型使用了Padding方式来匹配静态输入,但相较CPU上的运行结果,误差还是在一个比较小的范围内,可以直接代替CPU来提升性能,并优化能耗。
总结:
本文为NPU设备部署BGE Embedding模型提供了一种参考路径。通过将Embedding模型部署在NPU上,可以在不影响模型输出准确性的前提下,极大优化模型的性能和能耗表现,进一步提升RAG等相关应用的综合能力。
参考资料:
1. C_MTEB Benchmark: https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB
2. OpenVINOTM Transformation pas****>:https://blog.openvino.ai/blog-posts/large-language-model-graph-customization-with-openvino-tm-transformations-api
3. OpenVINO embedding in LangChain: https://python.langchain.com/v0.2/docs/integrations/text_embedding/openvino/