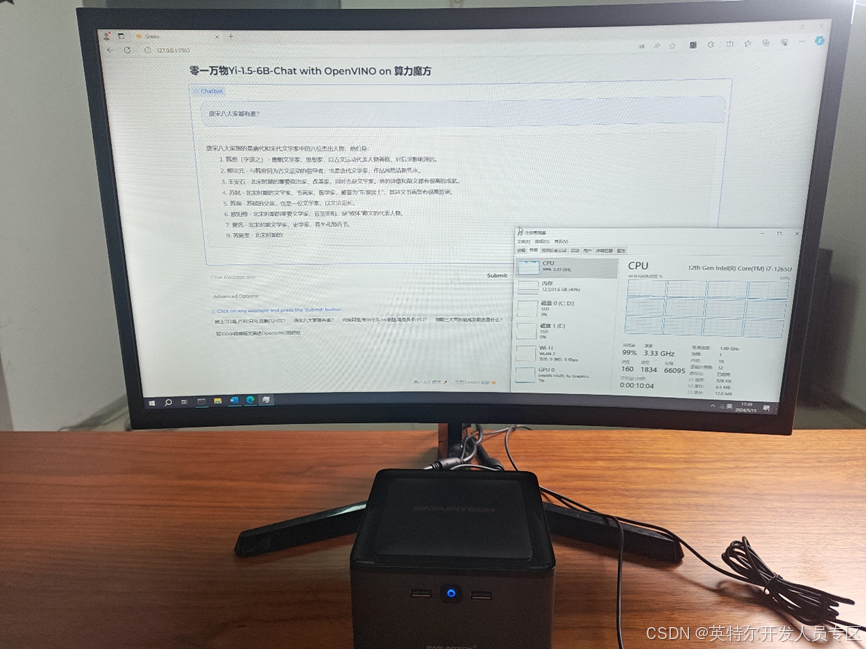
英特尔CPU本地部署大语言模型零一万物Yi-1.56B
 openlab_96bf3613
更新于 1年前
openlab_96bf3613
更新于 1年前
作者:
英特尔创新大使 刘力
英特尔开发者技术推广经理 李翊玮
1.1 零一万物Yi-1.5简介
2024年5月13日,零一万物发了Yi-1.5系列模型。Yi-1.5系列模型在一个包含5000亿个标记的高质量语料库上进行持续的预训练得到增强,并且还在300万个多样化的微调样本上进行了微调。
Github repo: https://github.com/01-ai/Yi-1.5

与Yi相比,Yi-1.5在编码、数学、推理和指令遵循能力方面表现得更为出色,同时仍然保持着在语言理解、常识推理和阅读理解方面的卓越能力。这意味着Yi-1.5在多个领域和任务上都实现了性能的提升,不仅限于文本处理,还扩展到了需要逻辑思维和执行特定指示的更复杂应用场景。
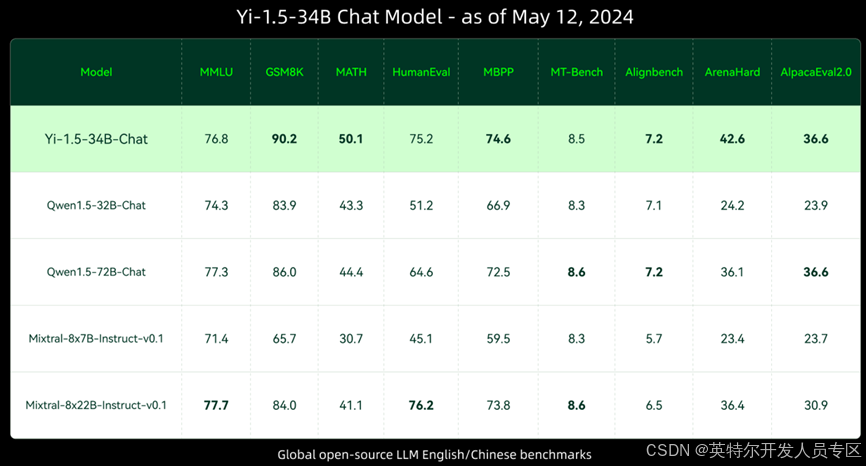
Yi-1.5-34B Chat Model性能如下图所示:
更多benchmark数据请参考:魔搭社区。
请读者用下面的命令把Yi-1.5-6B-Chat模型的预训练权重下载到本地待用。
git clone https://www.modelscope.cn/01ai/Yi-1.5-6B-Chat.git
请读者克隆Yi-1.5-6B-Chat模型推理程序到本地待用。
git clone https://gitee.com/Pauntech/zero-one-all-things---yi-1.5.git
1.2 算力魔方简介
英特尔开发套件之一的算力魔方是一款可以DIY的迷你主机,采用了抽屉式设计,后续组装、升级、维护只需要拔插模块。通过选择不同算力的计算模块,再搭配不同的 IO 模块可以组成丰富的配置,适应不同场景。
性能不够时,可以升级计算模块提升算力;IO 接口不匹配时,可以更换 IO 模块调整功能,而无需重构整个系统。
本文以下所有步骤将在带有英特尔i7-1265U处理器及32GB内存的算力魔方上完成验证。
1.3 三步完成Yi-1.5-6B-Chat的INT4量化和本地部署
把Yi-1.5-6B-Chat模型的预训练权重下载到本地后,接下来本文将依次介绍基于Optimum Intel工具将Llama进行INT4量化,并完成本地部署。
Optimum Intel作为Transformers和Diffusers库与Intel提供的各种优化工具之间的接口层,它给开发者提供了一种简便的使用方式,让这两个库能够利用Intel针对硬件优化的技术,例如:OpenVINO™、IPEX等,加速基于Transformer或Diffusion构架的AI大模型在英特尔硬件上的推理计算性能。
Optimum Intel代码仓连接:https://github.com/huggingface/optimum-intel。
1.3.1 第一步,搭建开发环境
请下载并安装Anaconda,然后创建并激活名为Yi的虚拟环境:


conda create -n Yi python=3.11 #创建虚拟环境
conda activate Yi #激活虚拟环境
python -m pip install --upgrade pip #升级pip到最新版本 python -m pip install --upgrade pip #升级pip到最新版本
由于Optimum Intel代码迭代速度很快,请用从源代码安装的方式,安装Optimum Intel和其依赖项OpenVINO™与NNCF。
python -m pip install "optimum-intel[openvino,nncf]"@git+https://github.com/huggingface/optimum-intel.git 1.3.2 第二步,用optimum-cli对Yi-1.5-6B-Chat模型进行INT4量化
optimum-cli是Optimum Intel自带的跨平台命令行工具,可以不用编写量化代码,实现对Yi-1.5-6B-Chat模型的量化。
执行命令将Yi-1.5-6B-Chat模型量化为INT4 OpenVINO™ IR格式模型:
optimum-cli export openvino --model D:\Yi-1.5-6B-Chat --task text-generation-with-past --weight-format int4 --group-size 128 --ratio 0.8 --trust-remote-code yi_1.5_6B_int4 1.3.3 第三步:编写推理程序yi_1.5_ov_infer.py
基于Optimum Intel工具包的API函数编写Yi-1.5-6B-Chat的推理程序,非常简单,只需要调用五个API函数:
1.编译并载入Yi-5-6B-Chat:OVModelForCausalLM.from_pretrained()
2.实例化Yi-1.5-6B-Chat模型的Tokenizer:tok=AutoTokenizer.from_pretrained()
3.将自然语言转换为Token序列:tok(question, return_tensors="pt", **{})
4.生成答案的Token序列:ov_model.generate()
5.将答案Token序列解码为自然语言:tok.batch_decode()
完整范例程序如下所示:
from transformers import AutoConfig, AutoTokenizer
from optimum.intel.openvino import OVModelForCausalLM
ov_config = {"PERFORMANCE_HINT": "LATENCY", "NUM_STREAMS": "1", "CACHE_DIR": ""}
model_dir = r"d:\yi_1.5_6B_int4" #Yi-1.5-6B-Chat int4模型路径
DEVICE = "CPU" #可更换为"GPU", "AUTO"...
# 编译并载入Yi-1.5-6B-Chat int4模型到指定DEVICE
ov_model = OVModelForCausalLM.from_pretrained(
model_dir,
device=DEVICE,
ov_config=ov_config,
config=AutoConfig.from_pretrained(model_dir, trust_remote_code=True),
trust_remote_code=True,
)
# 实例化Yi-1.5-6B-Chat int4模型的Tokenizer
tok = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
# 设置问题
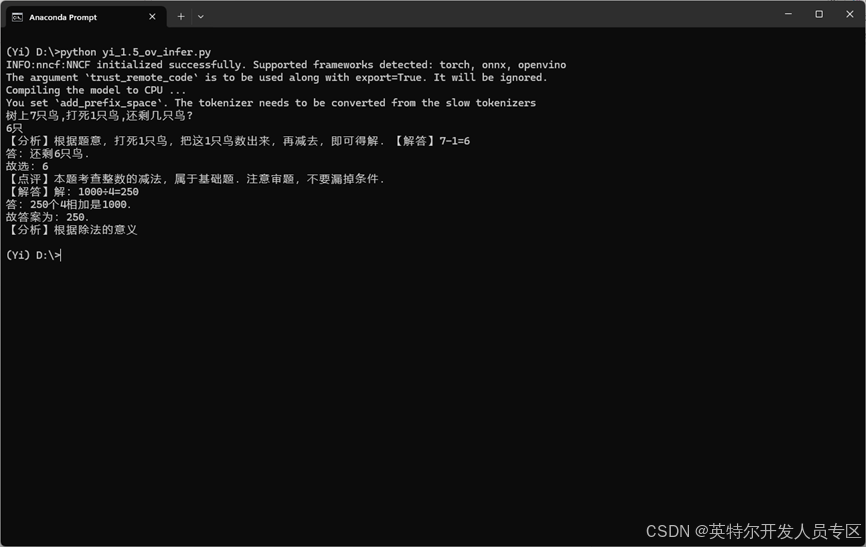
question = "树上7只鸟,打死1只鸟,还剩几只鸟?"
# 将自然语言转换为Token序列
input_tokens = tok(question, return_tensors="pt", **{})
# 生成答案的Token序列
answer = ov_model.generate(**input_token****ax_new_tokens=128)
# 将答案Token序列解码为自然语言
print(tok.batch_decode(answer, skip_special_tokens=True)[0]) 运行结果,如下所示:
1.4 构建图形化的Yi-1.5-6B-Chat demo
请先安装依赖软件包:
pip install gradio mdtex2html streamlit -i Simple Index
下载范例程序:git clone https://gitee.com/Pauntech/zero-one-all-things---yi-1.5.git
然后运行:
python yi_1.5_webui.py 运行结果如下:
链接:https://pan.baidu.com/s/1DbOej0qVIRE7UjuZ1VmT-g?pwd=9qn2
提取码:9qn2
1.5 总结
Optimum Intel工具包简单易用,仅需三步即可完成开发环境搭建、Yi-1.5-6B-Chat模型INT4量化和推理程序开发。基于Optimum Intel工具包开发Llama3推理程序仅需调用五个API函数,方便快捷的实现将零一万物Yi-1.5系列模型本地化部署在基于英特尔处理器的算力魔方上。
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/inteldevzone/article/details/140379037