【哪吒开发板试用】基于OneAPI的个人电脑本地智能助手
 openlab_96bf3613
更新于 1年前
openlab_96bf3613
更新于 1年前
有奖征文详情:https://inteldevkit.csdn.net/66a33139e4c56a4bc835a65b.html
原文链接:【哪吒开发板试用】基于OneAPI的个人电脑本地智能助手_imaginist-英特尔开发套件专区
1、背景
近年来,边缘计算技术在物联网(IoT)、人工智能(AI)等领域得到了广泛应用,尤其在工业、医疗和智能零售等场景中,边缘计算能够提高数据处理的实时性,减少云端计算的延迟,降低带宽成本,并增强数据隐私和安全性。在这些应用中,硬件平台的选择至关重要,既要求高性能处理能力,又需要支持丰富的扩展接口,以便连接不同传感器和执行器,满足多样化的需求。
本地大语言模型(Local Large Language Models,LLMs)是指在用户的本地计算设备(如个人电脑、工作站或移动设备)上运行的大规模语言模型。这种模型通过下载到用户设备上,可以在不依赖外部服务器或云计算平台的情况下进行推理和处理。这类模型的引入不仅使得用户可以在本地进行自然语言处理任务,还为数据隐私、安全性和离线使用等场景带来极大优势。
参考最近pc平台都在大力推行NPU的发展,以及各种cpu开始支持AVX256甚至512指令加速,这些无不预示着未来各大硬件厂商或者是桌面电脑生产商都会盯着本地llm这个香饽饽。但是本地运行大模型依然存在很多问题亟待解决,例如大模型低比特量化过后,虽然提升了性能但是大模型的推理速度会不会比小模型更差呢。在加速极致性能经过量化,剪枝,微调过后,大模型追求的泛化性是否还能得到保证呢?
英特尔推出的“哪吒派”(NezhaPi)是一款面向边缘计算应用的开发平台,它基于英特尔® N97处理器,能够为零售、工业、医疗等场景提供高效解决方案,尤其在搭配 Intel OpenVINO 和 oneAPI 技术时,能够加速 AI 模型的推理和开发。
chatgpt生成
2、设备
本项目采用intel官方边缘计算平台哪吒派(看淘宝上貌似说已经停产了,现已有alexboard代替),性能比n100小主机要强一点。引出了类似树莓派40pin的GPIO接口,可用于扩展开发。可以用于边缘深度学习的应用开发,搭配openvino可以很快地将各个应用进行落地。
在采用英特尔®处理器 N97 的开发人员套件上,为零售、工业、医疗保健和其他边缘应用构建高效的解决方案。这些开发人员工具包附带预先验证的软件堆栈。结合高效的多任务处理性能、图形功能和扩展的 I/O 功能,您拥有一个完整的套件,有助于加速解决方案的开发和部署。
通过多达 8 个内核和更高的内存带宽,通过 DDR5 和 LPDDR5 SDRAM 支持,提供改进的单线程和多线程性能。
加速 AI 性能。在 Intel® UHD Graphics 上最多可同时显示三个,该显卡基于 X 架构,具有多达 32 个执行单元。这些执行单元是针对同步多线程进行了优化的图形计算处理器。
提供内置支持,以组合来自经过验证的传感器(例如加速度计、陀螺仪和磁力计)的数据,为您的解决方案创建更复杂的虚拟传感器。
优势: 哪吒派的边缘计算能力适合在处理大规模实时数据时快速部署 AI 应用,尤其在计算资源有限、网络带宽有限或对隐私要求较高的情况下。得益于英特尔 N97 处理器的多核性能以及 UHD 图形处理单元,它可以在本地完成复杂的 AI 推理任务而无需依赖云端,减少延迟和传输成本。
由于英特尔“哪吒派”边缘计算平台本身不提供音频输入和输出功能,在需要语音输入(如麦克风)和音频输出(如扬声器)时,可以选择额外购买外部的 USB 免驱麦克风和喇叭二合一设备(好好好,我的树莓派也可以用)。这类设备无需额外安装驱动程序,便于在各种嵌入式平台上快速集成音频功能。
另外哪吒派也不提供无线网卡蓝牙功能,只能连接网线或者购买u**无线网卡
3、介绍whisper
Whisper 是 OpenAI 发布的开源语音识别模型,能够进行高精度的语音转文本(ASR, Automatic Speech Recognition)任务。它适用于多种语言,并能够处理复杂的音频输入,如嘈杂环境、带有口音的语音等。Whisper 在许多实时应用中表现出色,例如智能音箱、智能客服、会议纪要生成等。
Whisper 的优势:
多语言支持: Whisper 模型能够处理多种语言的语音输入,包含中文、英文等常见语言。
抗噪能力: 模型能够在嘈杂环境下进行精确的语音识别,适用于工业、交通等场景。
性能优化: Whisper 采用 Transformer 架构,能够进行大规模数据训练,并通过精细调优提升识别准确率。
为什么选择whisper?
和intel的生态支持的比较好,openvino以及oneapi均得到支持
性能高,whisper.cpp的性能经过优化,相对于其他有点优势,虽然在边缘小板子上碍于性能上限速度也被大打折扣
在命令行使用git将whisper项目拉取到本地
git clone https://github.com/ggerganov/whisper.cpp
或者在网站下载压缩包后解压是一样的,只是有的时候命令行不会走系统代理,可能连不上github
llama模型下载
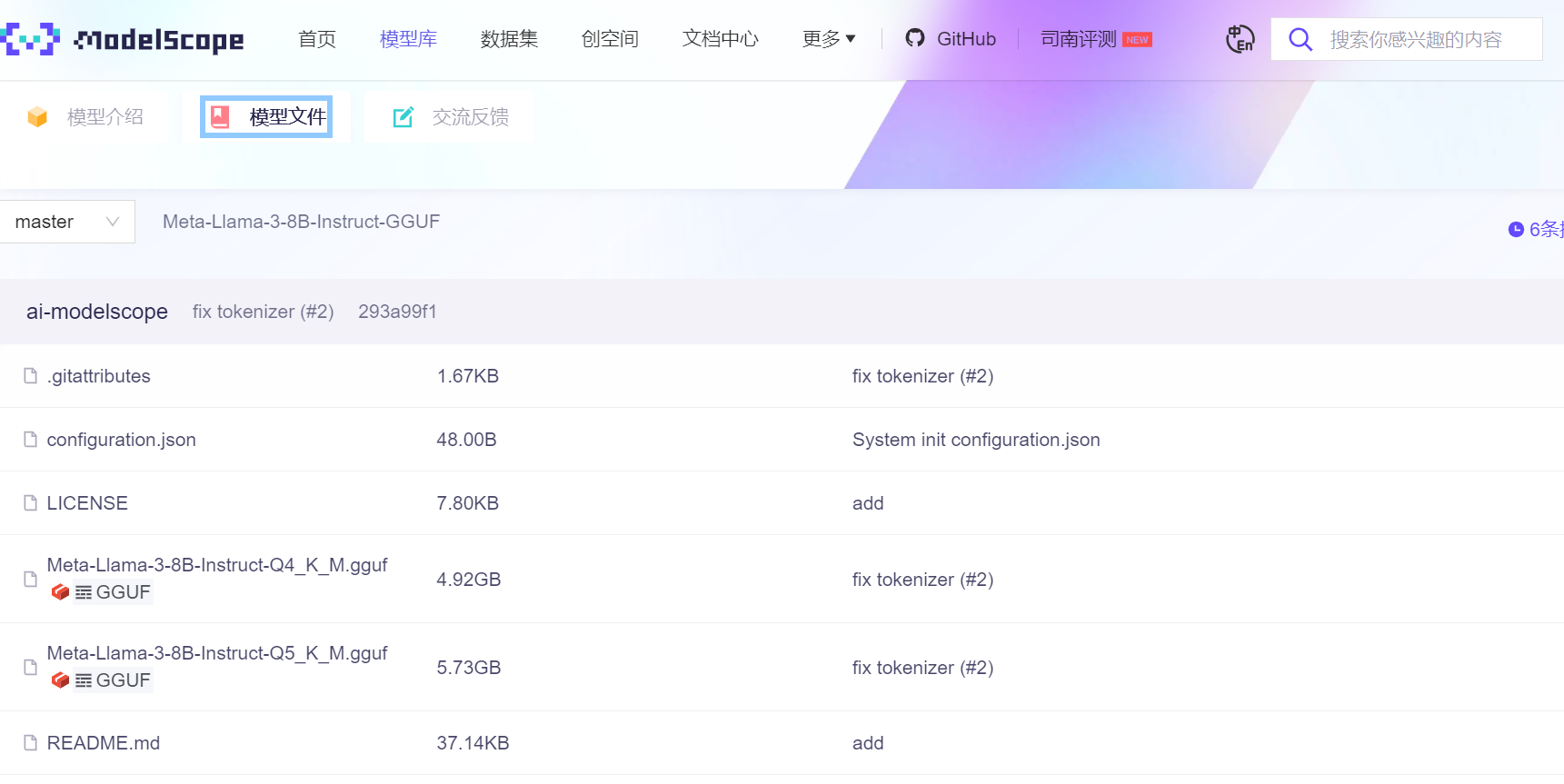
llm模型可以到这个网站下载,有点像国内版的抱脸虫网站
https://www.modelscope.cn/model***r/>
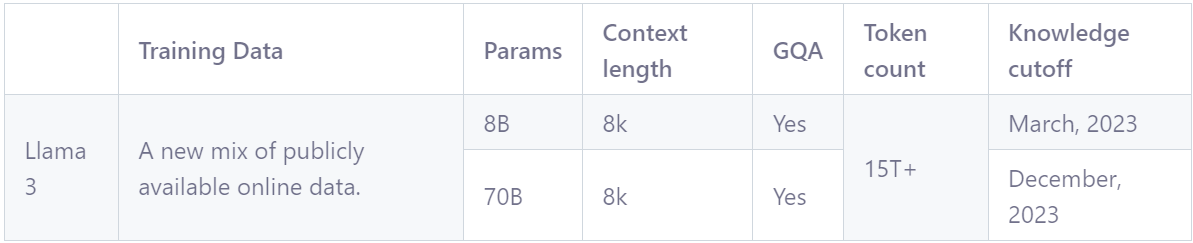
找到llama3 8B的模型
鉴于边缘板子的性能,选择8B的模型,gguf格式
whisper模型下载
通过脚本download-ggml-model.cmd或者sh
.en结尾的为仅支持英文的模型,在这里我只需要英文的模型,因为我需要提高英语水平。。
bash ./models/download-ggml-model.sh base.en
支持tiny、base、**all、medium 以及 large 模型
对源代码进行编译
# build the main example
make
# transcribe an audio file
./main -f samples/jfk.wav 使用talk-llama调用模型
talk-llama.exe -mw [whisper模型] -ml [llama3语言模型] -s [指定speaker程序] -l en
4、介绍oneapi MKL加速
oneAPI 数学核心库(oneMKL)是英特尔 oneAPI 工具包中的高性能数学函数库,旨在为科学计算、工程模拟、金融分析、机器学习和人工智能等领域提供高度优化的数学运算功能。oneMKL 集成了对英特尔 CPU、GPU 和 FPGA 等多种硬件架构的优化支持,允许开发者在不同的硬件平台上实现高效的计算。
翻看了下oneapi的官方文档,感觉确实功能非常全面,而且提供了一些易于上手的api操作,后续再仔细研究一下。
MKL是oneapi的一个部分,个人理解是一个高性能的数学库,如矩阵运算之类的,神经网络的高效推理离不开矩阵计算的高性能实现,另外还提供了一些优化代码的工具,用于提升代码执行效率
可以在whisper官方找到适配MKL
whisper的教程
通过英特尔数学内核库的 BLAS 兼容接口,可以在 CPU 上加速编码器处理。首先,确保您已经安装了 Intel 的 MKL 运行时和开发包: https://www.intel.com/content/www/us/en/developer/tools/oneapi/onemkl-download.html
现在使用 Intel MKL BLAS 支持构建whisper.cpp :
source /opt/intel/oneapi/setvars.sh
mkdir build
cd build
cmake -DWHISPER_MKL=ON ..
WHISPER_MKL=1 make -j
这个库感觉装了很多次都有问题,后续整理一下bug
windows上一般是在vs的环境中使用,msvc编译器
后续测试一下openvino加速与MKL加速的区别
5、调用windows的TTS生成语音
TTS(文本转语音,Text-to-Speech)技术是一种将书面文本转换为自然语言语音的技术。它通过分析输入的文本,生成与之对应的语音输出,使计算机能够以人类可听的方式“说话”。TTS技术在很多应用场景中都非常重要,包括虚拟助手、导航系统、语音合成应用和无障碍技术等。
使用whisper推理,是可以识别到USB-MIC设备的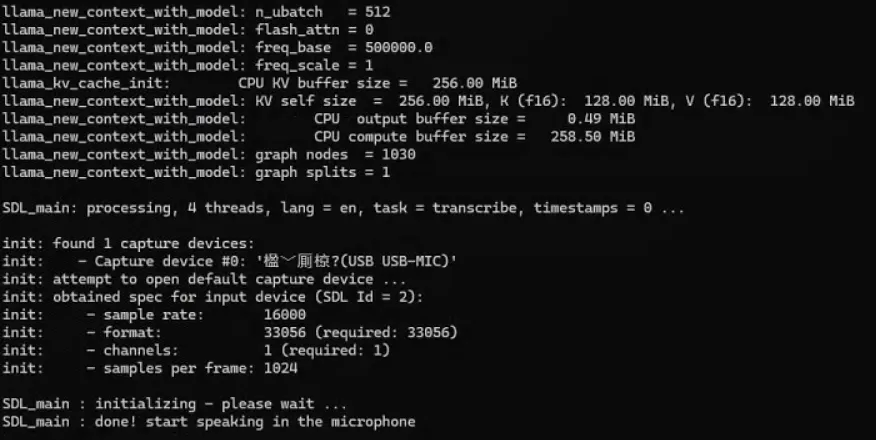
参考LanceLinHongbo用户的调用windows tts代码,以及whisper自带的example例程代码
#include <clocale>
#include <cstdio>
#include <cstring>
#include <fstream>
#include <iostream>
#include <string>
#include <windows.h>
#include <sapi.h>
class VoiceSynthesizer
{
public:
VoiceSynthesizer(int argc, char *argv[])
{
// Initialize COM library
HRESULT hr = CoInitialize(nullptr);
if (FAILED(hr))
{
std::cerr << "Failed to initialize COM library." << std::endl;
exit(1);
}
// Create SAPI voice instance
hr = CoCreateInstance(CLSID_SpVoice, nullptr, CLSCTX_ALL, IID_ISpVoice, reinterpret_cast<void **>(&pVoice));
if (FAILED(hr))
{
std::cerr << "Failed to create SAPI voice instance." << std::endl;
CoUninitialize();
exit(1);
}
// Set locale for multibyte to wide-char conversion
setlocale(LC_ALL, "en_US.UTF-8");
// Par******mand-line arguments
if (argc >= 2)
{
// Read the input text file
std::ifstream speak_file(argv[1]);
if (speak_file.fail())
{
std::cerr << "Failed to open the specified file: " << argv[1] << std::endl;
exit(1);
}
else
{
// Read the entire file into a string
content.assign(std::istreambuf_iterator<char>(speak_file), std::istreambuf_iterator<char>());
speak_file.close();
}
}
// Set default voice attributes
volume = 100; // Max volume
rate = 0; // Default rate
voice_name = L"Microsoft Zira Desktop"; // Default female voice
// Parse optional arguments (volume, rate, voice)
for (int i = 2; i < argc; i++)
{
if (strcmp(argv[i], "-rate") == 0 && i + 1 < argc)
{
rate = atoi(argv[++i]);
}
else if (strcmp(argv[i], "-volume") == 0 && i + 1 < argc)
{
volume = atoi(argv[++i]);
}
else if (strcmp(argv[i], "-voice") == 0 && i + 1 < argc)
{
voice_name = std::wstring(argv[++i], argv[++i] + strlen(argv[i]));
}
}
// Set the voice rate and volume
pVoice->SetRate(rate);
pVoice->SetVolume(volume);
}
~VoiceSynthesizer()
{
if (pVoice)
{
pVoice->Release();
pVoice = nullptr;
}
CoUninitialize();
}
void speak()
{
if (!content.empty())
{
// If content exceed***uffer size, split it and speak in chunks
size_t pos = 0;
while (pos < content.size())
{
std::wstring wtext = convertToWideString(content.substr(pos, 4000));
pVoice->Speak(wtext.c_str(), SPF_DEFAULT, nullptr);
pos += 4000;
}
}
else
{
std::cerr << "No content to speak." << std::endl;
}
}
private:
ISpVoice *pVoice = nullptr;
std::string content;
int volume;
int rate;
std::wstring voice_name;
// Convert multibyte string to wide string
std::wstring convertToWideString(const std::string &str)
{
std::wstring wstr(str.length(), L' ');
mbstowcs(&wstr[0], str.c_str(), str.length());
return wstr;
}
void setVoice()
{
ISpObjectTokenCategory *pCategory = nullptr;
IEnumSpObjectTokens *pEnum = nullptr;
ISpObjectToken *pToken = nullptr;
HRESULT hr = SpGetCategoryFromId(SPCAT_VOICES, &pCategory);
if (SUCCEEDED(hr))
{
hr = pCategory->EnumTokens(nullptr, nullptr, &pEnum);
if (SUCCEEDED(hr))
{
ULONG ulCount;
pEnum->GetCount(&ulCount);
for (ULONG i = 0; i < ulCount; i++)
{
hr = pEnum->Next(1, &pToken, nullptr);
if (SUCCEEDED(hr))
{
// Check the token name and set the voice if it matches
LPWSTR voiceDescription;
pToken->GetStringValue(nullptr, &voiceDescription);
if (voice_name == voiceDescription)
{
pVoice->SetVoice(pToken);
CoTaskMemFree(voiceDescription);
break;
}
CoTaskMemFree(voiceDescription);
}
pToken->Release();
}
pEnum->Release();
}
pCategory->Release();
}
}
};
int main(int argc, char *argv[])
{
if (argc < 2)
{
std::cout << "Usage: VoiceSynthesizer <input_file/> [-rate <rate>] [-volume <volume>] [-voice <voice_name>]" << std::endl;
return 1;
}
VoiceSynthesizer synthesizer(argc, argv);
synthesizer.speak();
return 0;
}
6、总结
通过这次项目,我了解了边缘计算的应用,学到了如何选择适合的硬件平台以提高数据处理效率。同时,我接触到了英特尔的关键技术,包括英特尔® N97处理器、Intel OpenVINO、oneAPI MKL、Whisper语音识别和TTS技术。这些技术让我掌握了如何加速AI模型推理、优化计算性能和实现自然语音输出,为未来的相关项目提供了宝贵的经验。