【哪吒开发板试用】基于YOLO的量产整车四轮规格AI视觉检查系统(二)
 openlab_96bf3613
更新于 1年前
openlab_96bf3613
更新于 1年前
有奖征文详情
一、数据集准备与标注
(一)准备自定义数据集
自定义数据集顾名思义就是通过自己收集的图像,进行标注得到图像文件+标注文件。
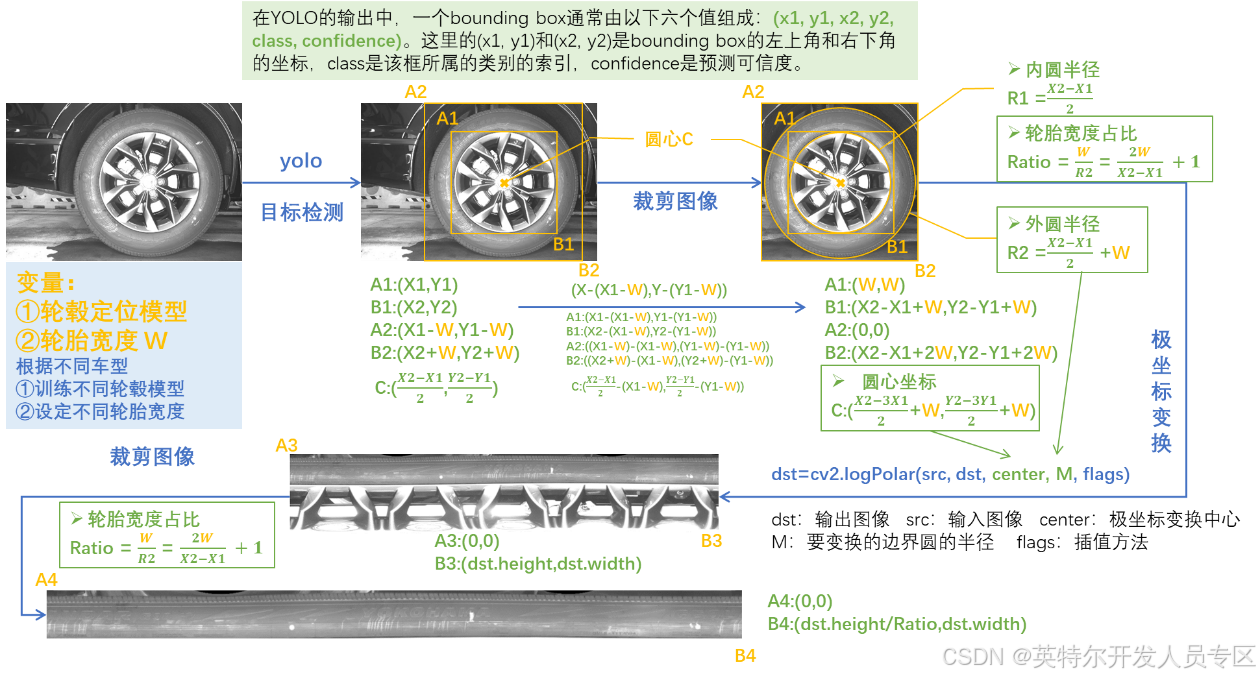
1.轮毂图像
我们利用工业相机采集了A、B风格两种轮毂各100张共200张图像。新建一个文件夹命名为datasets,新建子文件夹data,再在data下新建子文件夹images,将所有图像放置于images中。以便后续标注及数据拆分。
即:datasets\data\image***r/>
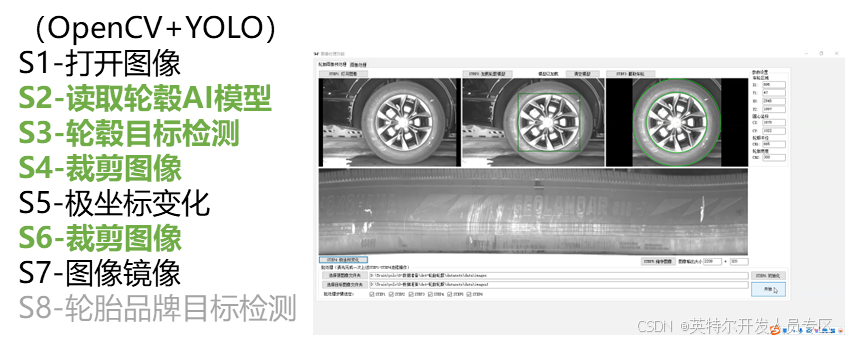
2.轮胎图像
通过对轮胎进行补光,利用OpenCVSharp以及YOLO,得到水平展开的轮胎图像。

(二)图像标注
标注工具:X-AnyLabeling
教程:https://blog.csdn.net/CVHub/article/details/135707749
官网:https://github.com/CVHub520/X-AnyLabeling/tree/main
1.人工标注
①打开“X-AnyLabeling-GPU.exe”或“X-AnyLabeling-CPU.exe”;
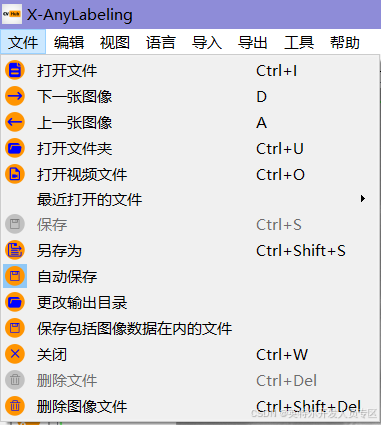
②左上角“文件”-“打开文件夹”,选择上述轮毂图像所在文件夹datasets\data\image****r/>
③左上角“文件”-“自动保存”,记得进行选择;
④左上角“文件”-“更改输出目录”,在datasets\data路径下新建一个json文件夹,并选定datasets\data\json,后续标注文件将以.json格式保存至此;
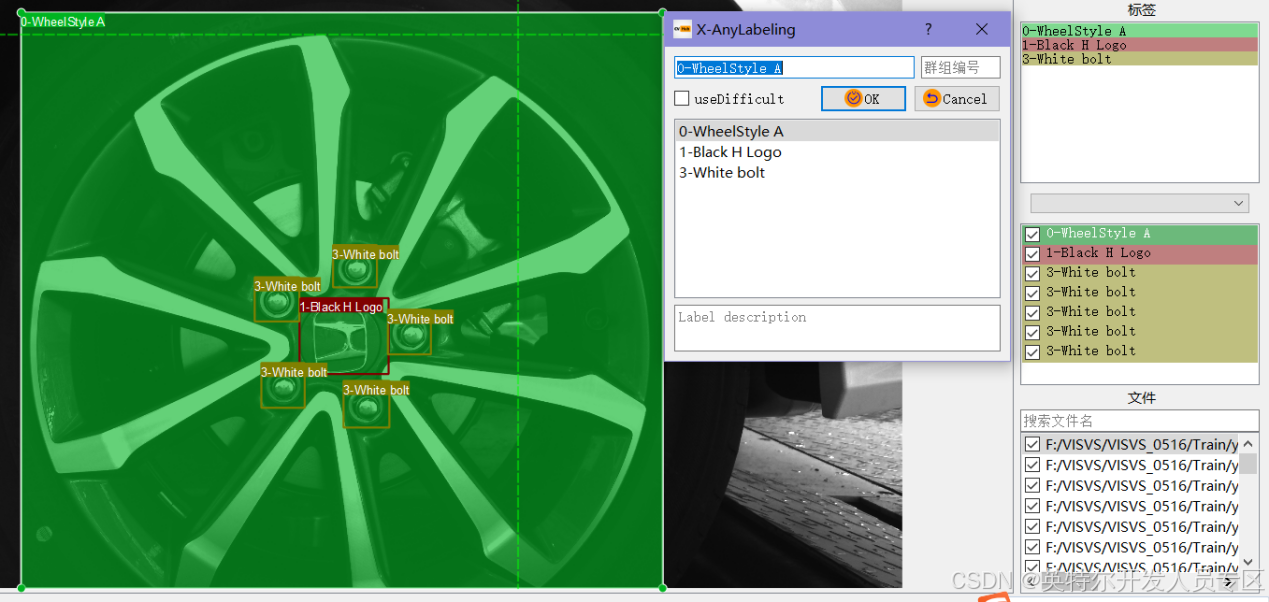
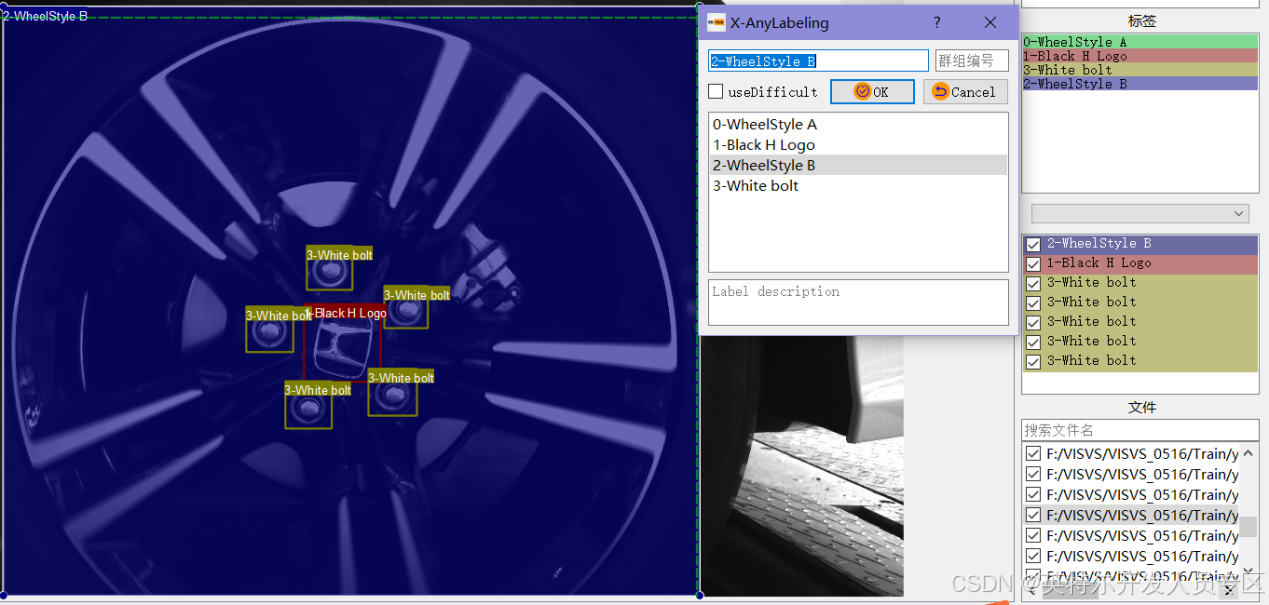
⑤开始标注,框选目标(目标检测任务采用矩形框,实例分割任务采用多边形,目标检测含方向检测OBB采用旋转框)。在框选目标后填写标签名称(暂不支持中文);
⑥如图所示,对A/B风格轮毂*1、黑色轮毂盖H标牌*1、白色螺栓*5进行标注;

⑦以此类推,完成剩余图像的标注,标注后的数据文件将自动储存在datasets\data\json;
⑧由于yolo支持的标注文件格式为.txt,因此需“导出”-“导出YOLO标签”,会弹出对话框提示选择class.txt文件,在datasets\data路径下新建一个“class.txt”文件,内容填写为标注时的标签名称0-WheelStyle A、1-Black H Logo、2-WheelStyle B、3-White bolt,并选择此class.txt文件;
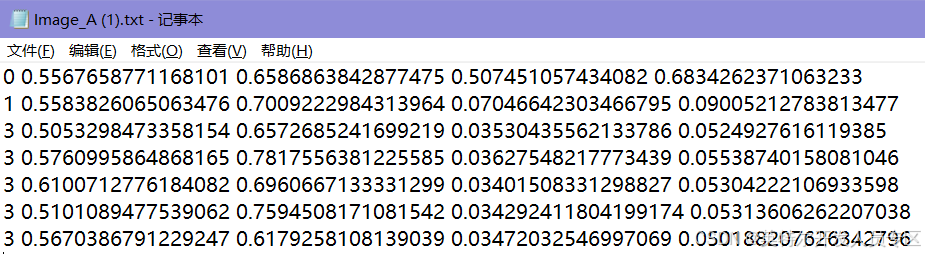
⑨提示成功导出YOLO标签文件,路径为datasets\data\label****r/>
⑩至此,我们得到图像文件夹images以及标签文件夹label****r/>

2.AI自动标注
教程:https://zhuanlan.zhihu.com/p/636164570
使用AI自动标注功能需要有初步训练好模型并转换为onnx模型(后续模型导出环节会提及)以及.yaml配置文件(可参考教程)。
①打开“X-AnyLabeling-GPU.exe”或“X-AnyLabeling-CPU.exe”;
②左上角“文件”-“打开文件夹”,选择上述轮毂图像所在文件夹datasets\data\image****r/>
③假设已完成一次轮毂模型的训练,获得best.pt模型文件并转换为best.onnx模型;
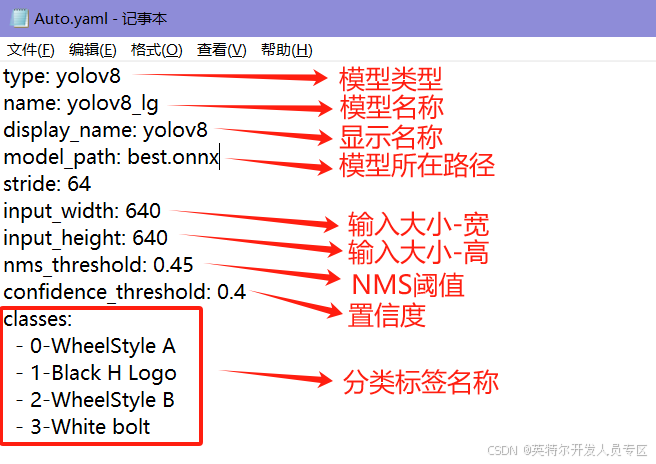
④新建一个Auto.txt文件,并更改后缀为.yaml,使用记事本打开,填写模型配置信息;
⑤将配置文件Auto.yaml以及模型best.onnx放在同一目录下;
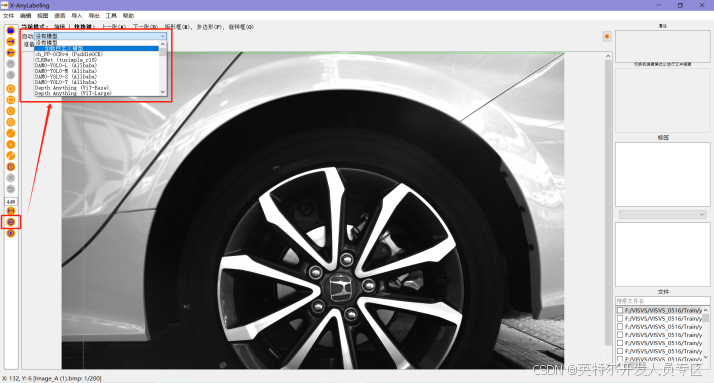
⑥左侧工具栏-AI“自动标注”,加载自定义模型,选择Auto.yaml;
⑦加载模型后,点击左侧工具栏-一次运行所有图片,自动进行标注。
⑧由于模型的不确定性,需进行人工的二次检查及必要的修正。
⑨标签的导出同上述人工标注一致,至此我们得到图像文件夹images以及标签文件夹label****r/>
二、数据集拆分

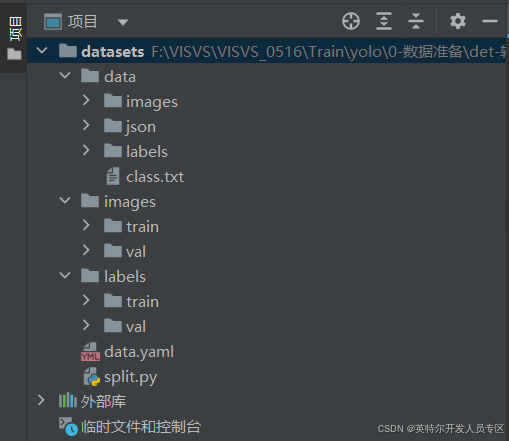
(一)图像及标签拆分
1.创建拆分文件
①在datasets路径下新建一个split.py的python文件,填写以下代码,并运行;
②处理完成后将在datasets路径下自动生成用于训练的图像路径datasets/images/train、用于评估的图像路径datasets/images/val、用于训练的标签路径datasets/labels/train、用于评估的标签路径datasets/labels/val;
③注意比例train_ratio,以及图像格式.bmp可根据需要修改;
import os
import random
import shutil
# 输入文件夹路径和划分比例
folder_path_jpg = "data/images"
folder_path_txt = "data/labels"
train_ratio = 0.8
# 检查文件夹是否存在
if not os.path.exists(folder_path_txt):
print("文件夹不存在!")
exit()
# 获取所有bmp和txt文件
jpg_files = [file for file in os.listdir(folder_path_jpg) if file.endswith(".bmp")]
txt_files = [file for file in os.listdir(folder_path_txt) if file.endswith(".txt")]
# 检查文件数量是否相等
if len(jpg_files) != len(txt_files):
print("图片和标签数量不匹配!")
exit()
# 打乱文件顺序
random.shuffle(jpg_files)
# 划分训练集和验证集
train_size = int(len(jpg_files) * train_ratio)
train_jpg = jpg_files[:train_size]
train_txt = [file.replace(".bmp", ".txt") for file in train_jpg]
val_jpg = jpg_files[train_size:]
val_txt = [file.replace(".bmp", ".txt") for file in val_jpg]
# 创建文件夹和子文件夹
if not os.path.exists("images/train"):
o***akedirs("images/train")
if not os.path.exists("images/val"):
o***akedirs("images/val")
if not os.path.exists("labels/train"):
o***akedirs("labels/train")
if not os.path.exists("labels/val"):
o***akedirs("labels/val")
# **文件到目标文件夹
for file in train_jpg:
shutil.copy(os.path.join(folder_path_jpg, file), "images/train")
for file in train_txt:
shutil.copy(os.path.join(folder_path_txt, file), "labels/train")
for file in val_jpg:
shutil.copy(os.path.join(folder_path_jpg, file), "images/val")
for file in val_txt:
shutil.copy(os.path.join(folder_path_txt, file), "labels/val")
print("处理完成!")
(二)配置文件
在datasets路径下新建一个data.txt文件,并更改文件后缀为.yaml,填写以下内容,后续模型训练时,需要填写此文件的路径:
至此,数据集已完成准备,可进行下一步模型训练。
三、模型训练

(一)预训练模型下载
1.官方下载地址:https://docs.ultralytics.com/task***r/>
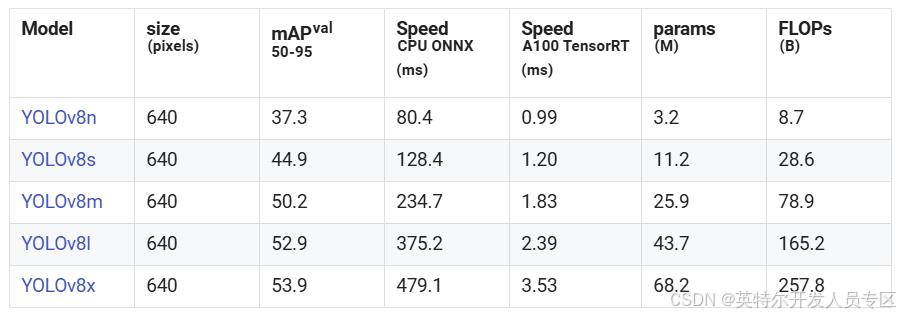
2.可根据电脑性能选用不同大小的模型,所需资源由低至高是n、***、l、x,一般采用n或****r/>
3.解压从GitHub获取YOLOv8项目源码“ultralytic***ain.zip”;
4.在ultralytic***ain路径下新建一个weights文件夹,将下载的预训练模型放置其中;
(二)训练参数设定
1.yolov8的训练参数路径为:ultralytic***ain/ultralytics/cfg/default.yaml;
2.官方文档:https://docs.ultralytics.com/modes/train/#argument***r/>
3.此default.yaml参数注释为英文,中文注释可参考:https://blog.csdn.net/X_Co**ic/article/details/136072743
(三)开始模型训练
1.选择上文环境配置成功后的Python 3.8 (yolov8)作为本项目Python解析器;
2.如果遇到报错缺少某个库,则安装对应的库;
3.在终端进行模型训练;
在PyCharm底部导航栏有“终端”,进入后如果解析器配置正确则会在前面显示(yolov8),输入命令:yolo cfg=ultralytics/cfg/default.yaml,即采用修改设定好的参数文件进行训练。
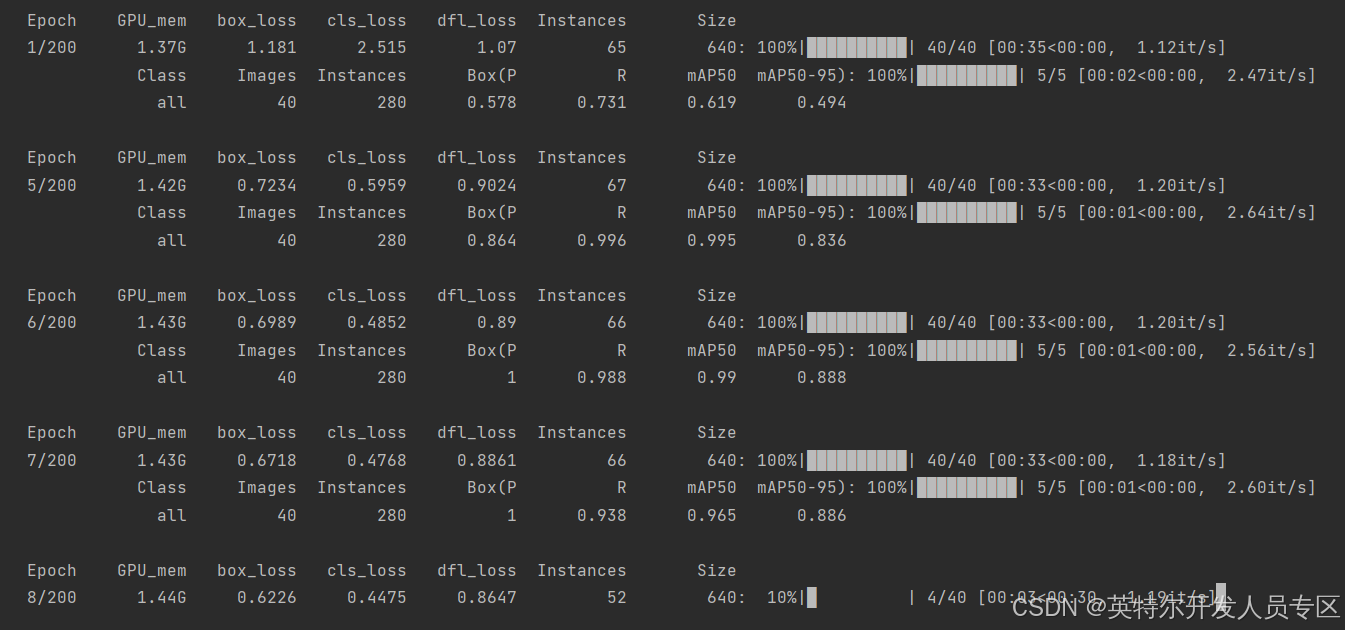
训练过程中主要留意每个批次的mAP50以及mAP50-95的值,是否逐渐增大且接近于1;
mAP(mean Average Precision)在机器学习中的目标检测领域,是十分重要的衡量指标,用于衡量目标检测算法的性能。一般而言,全类平均正确率(mAP,又称全类平均精度)是将所有类别检测的平均正确率(AP)进行综合加权平均而得到的。
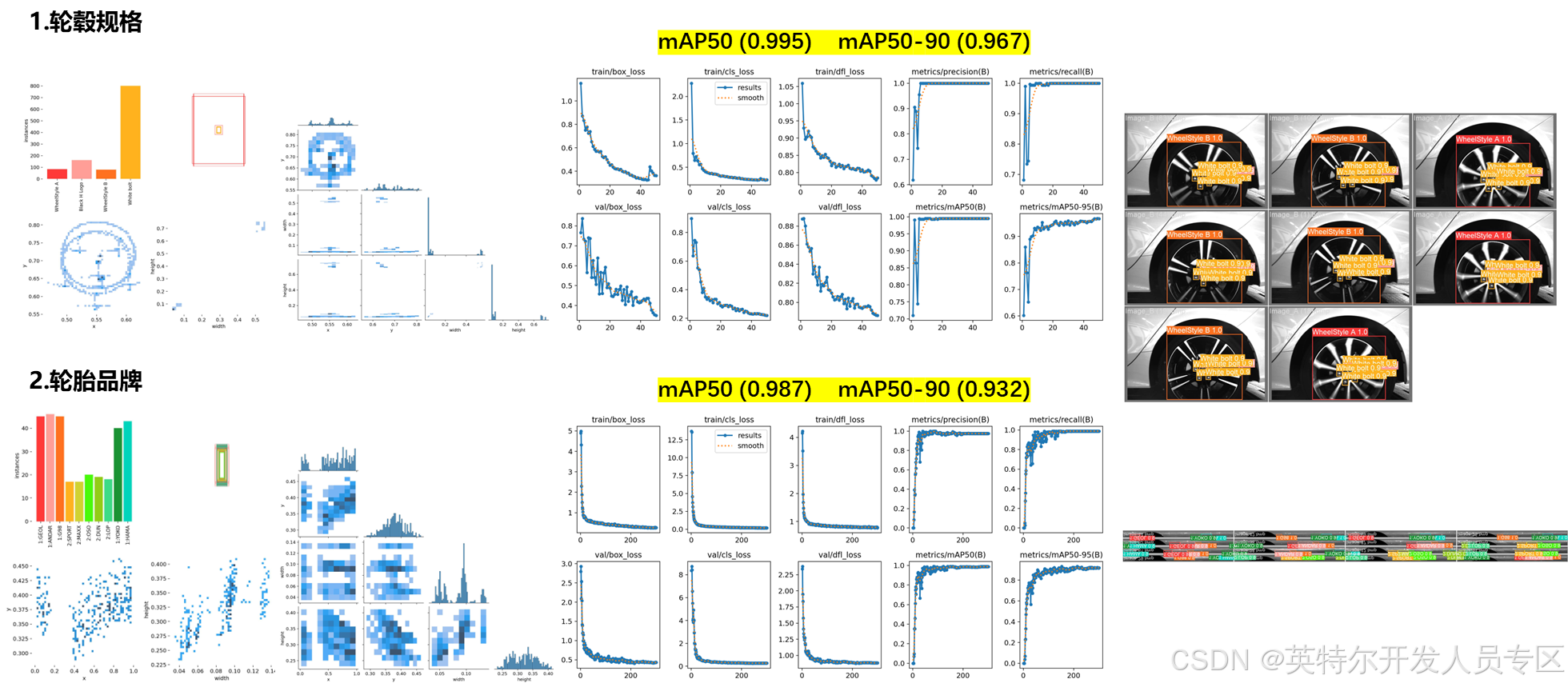
4.模型训练结果
结果解析说明:https://blog.csdn.net/matt45m/article/details/135620472
在完成模型训练后,一般在ultralytic***ain路径下自动生成runs-detect-train文件夹,储存训练结果以及weights目录下训练完成后的模型文件best.pt(最优模型)和last.pt(最后模型)。
(四)进行模型推理
1.利用模型训练后得到最佳模型best.pt进行图像推理,在终端进行推理;
在终端处填入:
yolo task=detect mode=predict model=runs/detect/train/weight***est.pt source=testimgs/'Image (1).bmp' show=True
代码说明:yolo-任务-模式-模型路径-图像路径-展示



四、模型导出
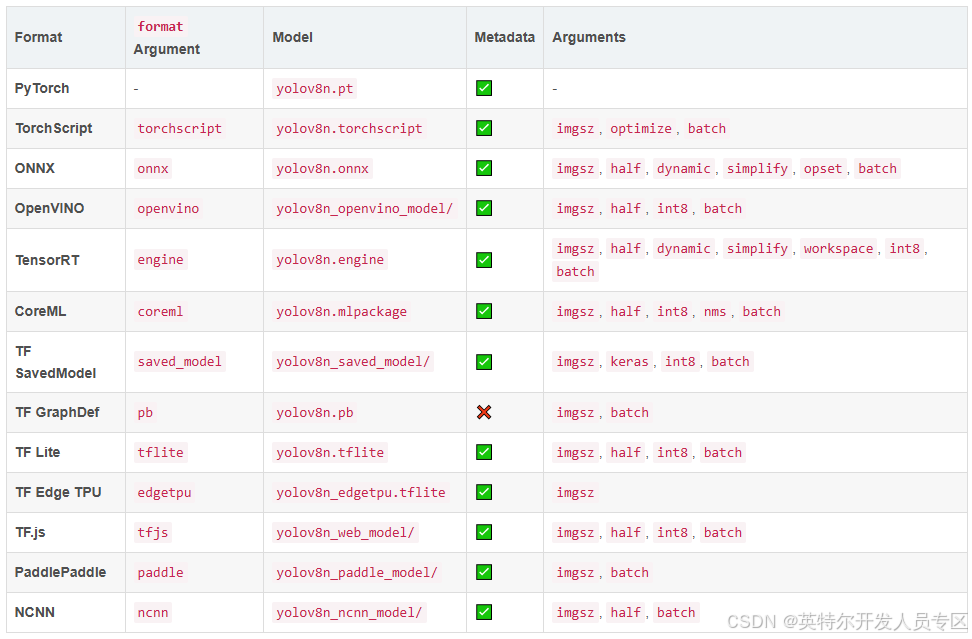
YOLOv8可导出的模型:
(一)导出为ONNX模型
1.ONNX模型说明:
介绍链接:https://blog.csdn.net/qq_44231797/article/details/140504803
ONNX(Open Neural Network Exchange,开放式神经网络交换格式)是一种模型文件格式,它在模型训练和模型推理中间提供了中间桥梁,使得上游不同的训练框架都能导出ONNX格式的模型,给到下游不同的推理框架都可以读取ONNX进行部署。
2.YOLOv8导出ONNX模型
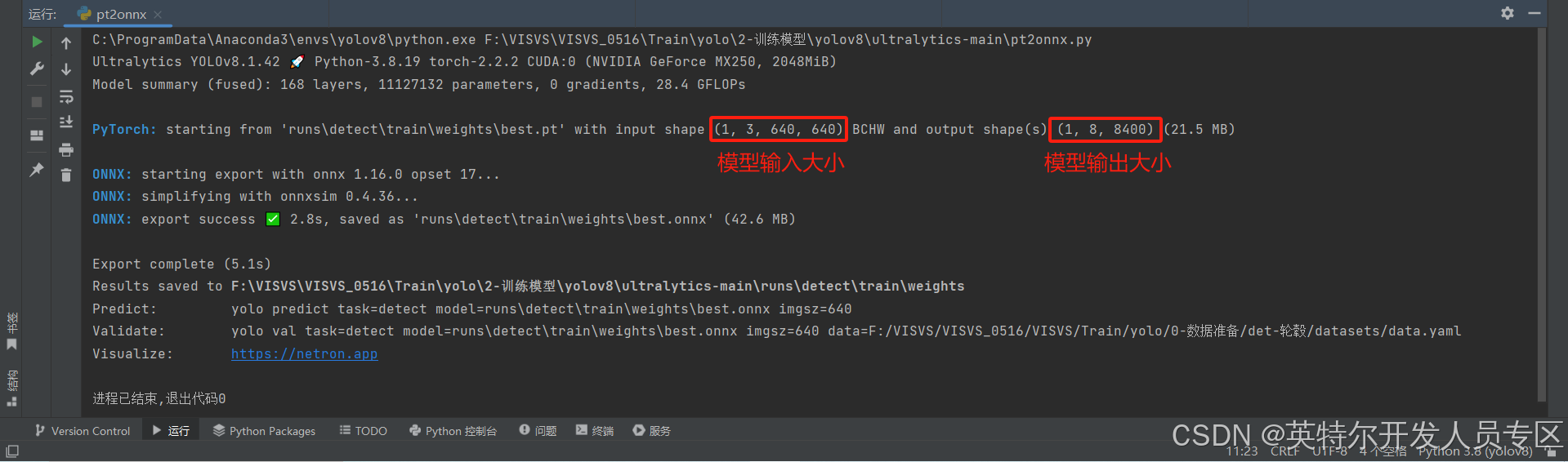
在ultralytic***ain目录下创建一个pt2onnx.py的Python文件,填入以下代码并运行:
from ultralytics import YOLO
# load model 需转换的pt模型
model = YOLO('runs/detect/train/weight***est.pt')
# Export model
succes*****odel.export(format="onnx")
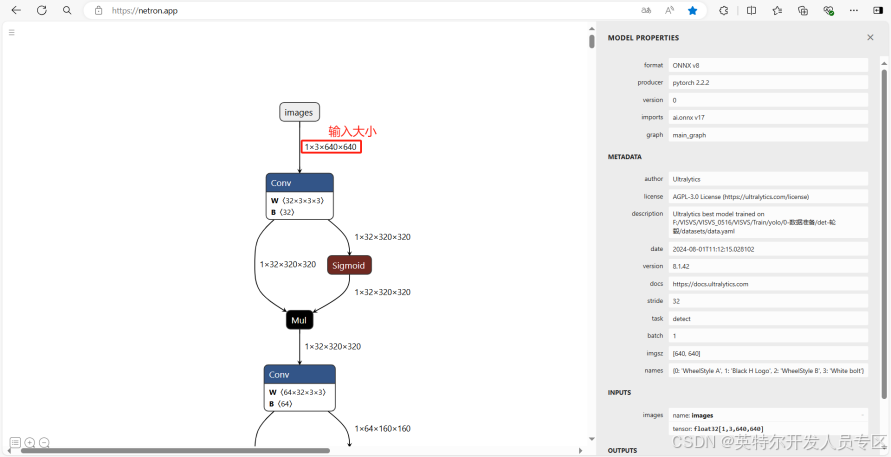
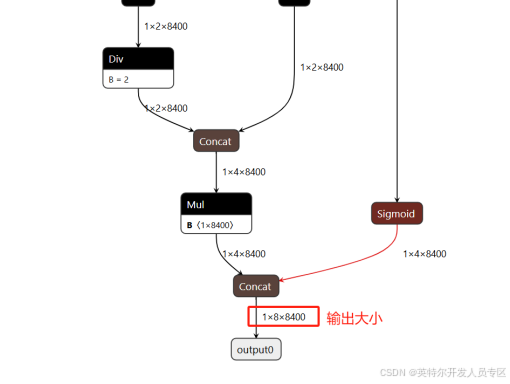
如上图,在运行信息中,需要记录模型的输入大小(1,3,640,640)以及模型输出大小(1,8,8400)。
输出成功后,将在runs/detect/train/weight***est.pt同目录下生成best.onnx模型文件。
3.查看ONNX模型结构
网址:https://netron.app/