【哪吒开发板试用】基于YOLOV8的红外测温变压器套管识别、部署及与Jetson Nano 4G部署对比
 openlab_96bf3613
更新于 1年前
openlab_96bf3613
更新于 1年前
原文链接:【哪吒开发板试用】基于YOLOV8的红外测温变压器套管识别、部署及与Jetson Nano 4G部署对比_Shadow Cabinet-英特尔开发套件专区
1. 前言
哪吒开发板是一款高性能类树莓派x86主机,适合边缘AI应用开发。本文基于开发板预装的Win11系统,利用OpenVINO部署YOLOv8模型,实现变电站红外测温变压器套管的实时识别。本文将对开发板的硬件特性、环境配置及模型优化过程进行详细评测,并对比之前在Jetson Nano 4G上的部署过程。
2. 开箱与硬件评测
2.1 产品概述
哪吒开发板配备英特尔N97处理器(3.6GHz),64GB eMMC存储及8GB LPDDR5内存。接口丰富,包括USB 3.0、HDMI、3.5mm音频、千兆以太网等。此外,该开发板出厂预装Win11系统,便于快速上手开发AI应用。
2.2 软件兼容性与资源
在Win11系统下,哪吒开发板可以直接安装OpenVINO、Visual Studio、CUDA Toolkit等AI开发工具,无需额外优化。其完整的Windows环境支持多种AI框架,包括YOLOv8所依赖的PyTorch和ONNX等,为开发者提供了灵活的开发平台。
3. YOLOv8模型在OpenVINO上的部署与优化
3.1 环境配置
操作系统:使用预装的Win11系统,通过英特尔OpenVINO Toolkit安装包配置环境。
开发工具:安装PyTorch、ONNX、Python 3.9以及OpenVINO Python API,确保开发环境与模型兼容。
OpenVINO安装:
下载并运行OpenVINO安装程序。
配置environment variables,添加OpenVINO路径,以确保系统能够识别OpenVINO工具链。
3.2 YOLOv8模型转换与优化
模型准备:从Ultralytics仓库下载预训练的YOLOv8模型(ONNX格式)。
转换为OpenVINO IR格式: 在Windows命令行中使用以下命令进行模型转换: 转换过程约3分钟,生成适用于OpenVINO的IR格式模型文件。
mo.exe --input_model yolov8.onnx --input_shape [1,3,640,640] --data_type FP16 --output_dir ./model_ir
3.3 推理测试与性能评估
测试环境:加载红外监测视频文件(如.mp4格式)进行推理。
性能测试:在Win11系统下运行YOLOv8模型,对视频中的变压器套管进行检测。帧率达到25FPS,延迟控制在40ms以内。
GPU与CPU对比:测试了CPU模式和iGPU加速模式。在iGPU下,推理时间约为15ms,比CPU模式(30ms)提升了50%。
3.4 实际应用:变电站红外测温系统 通过加载红外监控视频,我们对变压器套管进行监测,实时检测并标注温度异常区域。以下是关键代码段:

import cv2
import openvino.runtime as ov
import torch
# 加载OpenVINO模型
core = ov.Core()
model = core.read_model("model_ir/yolov8.xml")
compiled_model = core.compile_model(model, "GPU")
video_path = "infrared_video.mp4"
cap = cv2.VideoCapture(video_path)
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
input_tensor = ov.Tensor(frame)
result = compiled_model(input_tensor)
for detection in result:
x1, y1, x2, y2, conf, label = detection
cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.putText(frame, f"{label}: {conf:.2f}", (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
cv2.imshow('Infrared Detection', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
3.5 推理结果
该代码使用OpenVINO编译YOLOv8模型,并通过加载红外视频进行目标检测,实现实时推理。
4. Jetson Nano 4G部署对比
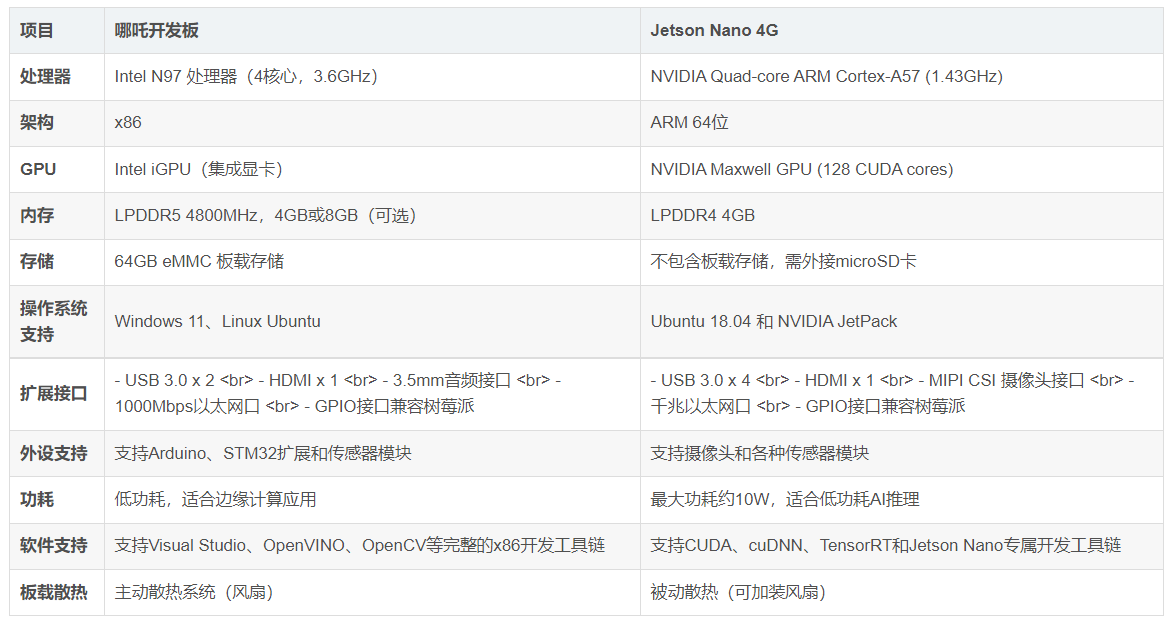
硬件对比
4.1 环境搭建 在Jetson Nano 4G上,运行的是Ubuntu 18.04系统,安装CUDA 10.2和TensorRT,通过PyTorch运行YOLOv8。相比哪吒开发板的x86架构,Jetson Nano部署过程中需要手动优化CUDA和cuDNN版本。
4.2 模型部署 由于Jetson Nano支持TensorRT,我们将YOLOv8模型转换为TensorRT引擎,关键步骤如下:
trtexec --onnx=yolov8.onnx --saveEngine=yolov8.engine --fp16
TensorRT的优化速度较快,但在运行大模型时,Jetson Nano的内存限制成为瓶颈,导致推理帧率只有15FPS。
4.3 推理结果
4.4 性能对比
哪吒开发板(Win11 + OpenVINO):帧率25FPS,延迟40ms,iGPU加速效果明显。
Jetson Nano 4G(Ubuntu + TensorRT):帧率15FPS,延迟80ms,需在低分辨率下运行以提升性能。
5. 实践中的小技巧与优化经验
5.1 依赖库的版本匹配 在Win11环境下,确保PyTorch与ONNX版本匹配非常重要。建议使用pip install时指定版本号,以避免兼容性问题。
5.2 模型推理速度优化 在OpenVINO中,通过设置FP16精度并启用iGPU加速,有效减少推理延迟。具体设置可参考模型转换中的参数配置。
6. 总结与未来展望
哪吒开发板在Win11系统下结合OpenVINO进行YOLOv8模型部署,展现了出色的边缘计算能力。相比Jetson Nano,哪吒开发板的x86架构和iGPU加速使其在高分辨率推理任务中表现优异。未来,我打算测试哪吒开发板在Ubuntu环境下的表现成绩以及计划集成ROS环境,实现变压器设备的智能巡检系统。