【有奖征文】树莓派跑LLM难上手?也许你可以试试Intel哪吒开发板
 openlab_96bf3613
更新于 1年前
openlab_96bf3613
更新于 1年前
前言
大型语言模型(LLM)通过其卓越的文本理解与生成能力,为机器智能带来了革命性的进步。然而,这些模型的运行通常需要消耗大量的计算资源,因此它们主要部署在性能强大的服务器上。
随着技术的发展和边缘计算的兴起,现在有潜力在更小巧、便携的设备上部署这些模型。例如,Raspberry Pi 树莓派和 Intel 哪吒开发套件等单片机。尽管体积小巧,但它们具备足够的能力运行某些精简版本的模型。本文就两款单片机上运行LLM做一个对比,先尝试在Raspberry Pi 4B运行大模型,然后将该方案在Intel哪吒开发板重建。
一、Raspberry Pi4 上运行大模型Qwen2 0.5B
一般情况下,模型需要两倍内存大小才能正常运行。因此,本方案使用的8GB的Raspberry Pi4 4B来做推理。
1、环境部署
#部署虚拟环境
sudo apt update && sudo apt install git
mkdir my_project
cd my_project
python -m venv env source env/bin/activate
#下载依赖库
python3 -m pip install torch numpy sentencepiece
sudo apt install g++ build-essential
#下载llama.cpp代码库
git clone https://github.com/ggerganov/llama.cpp
#编译环境
cd llama.cpp
make 2、模型下载
树莓派4b的8GB RAM,即使树莓派5,都不太适合做模型的量化。只能在PC机上做好量化后,再把量化后的模型文件拷贝到树莓派上部署。具体方式是使用LLaMA.cpp中的convert-hf-to-gguf.py将原模型转化成GGUF格式。
鉴于Raspberry Pi只有CPU,我们需要优先考虑可以在CPU上运行的模型。本次选择的大模型是Qwen2 0.5B。
Qwen2 0.5B是阿里云开源的新一代大语言模型,模型规模为0.49B参数,支持最长达32K tokens的上下文长度,在多个评测基准上表现优异,超越了Meta的Llama-3-70B。
这里我们直接从魔搭社区魔搭社区下载已经量化过的GGUF模型文件。
#模型下载
wget https://www.modelscope.cn/models/qwen/Qwen2-0.5B-Instruct-GGUF/resolve/master/qwen2-0_5b-instruct-q5_k_m.gguf 3、模型运行
大模型推理引擎使用的是llama.cpp,实现模型推理对话。
./llama-cli -m /home/pi/qwen2-0_5b-instruct-q5_k_m.gguf -n 512 -co -i -if -f ../../prompts/chat-with-qwen.txt --in-prefix "<|im_start|>user\n" --in-suffix "<|im_end|>\n<|im_start|>assistant\n" -ngl 24 -fa
4、总结
经过一番折腾,配置环境和编译,耗去了几天时间,树莓派终于成功运行大模型了。虽然可以,但比较吃力。看了网上其他人的尝试,即使换用具有更强大处理能力的树莓派5,运行作为资源有限设备设计的Phi-2-Q4(27亿参数),由于没有GPU支撑,所以速度也只有5.13 tokens/****r/>
所以说,树莓派5在处理速度上相较于4B有了显著提升,但在处理大型LLM时仍受到诸多限制。总结树莓派跑大模型的痛点:一是它无法做模型量化,要么在本地PC机上做好量化再拷贝过来,要么直接下载使用GGUF模型文件。二是它只有CPU,计算能力的提升空间基本被锁死了。如果要在树莓派上跑模型,只能选用内存占用较小且仅在 CPU 上运行的模型。
看网上有高人设想了一些解决方案,比如:
1. 将树莓派上的小GPU用起来。树莓派5有个VideoCore GPU,支持Vulkan编程,而llama.cpp也有Vulkan后端,理论上是有可能的。但运行上有些问题,包括死锁、输出乱码等,推测可能和shader有关,还需要进一步研究。
2. 用类似T-MAC的方法,加速树莓派CPU的推理。T-MAC提出用look-up table (LUT) 代替计算,对于低比特量化的模型会很有帮助。例如4-bit相乘,只需要一个16x16的表就能预存所有可能的结果,把乘法变成了查表。
3. 采用新的更高效的模型架构,例如RWKV?
但这些方法都还只是停留在理论设想阶段,没有落地实践,那为什么不直接试下Intel 哪吒呢?
二、Intel 哪吒开发套件上运行大模型Qwen 2.5
Intel 哪吒开发套件搭载了英特尔N97处理器(3.6GHz),配备64GB eMMC存储和8GB LPDDR5内存。英特尔N97处理器属于 Intel Alder Lake-N 系列,采用仅 E-Core 的设计,专为轻量级办公、教育设备和超低功耗笔记本电脑设计,成本和功耗更低,更适合嵌入式设备。

关键点来了!Intel 哪吒最大的优势就是自带集成显卡,Intel UHD Graphics,我们可以在iGPU上使用OpenVINO来运行大模型。
说干就干!
(一)安装OpenVINO配置环境
1、安装OpenVINO
从OpenVINO官网下载linux版本的压缩包,再解压,安装依赖,配置环境变量。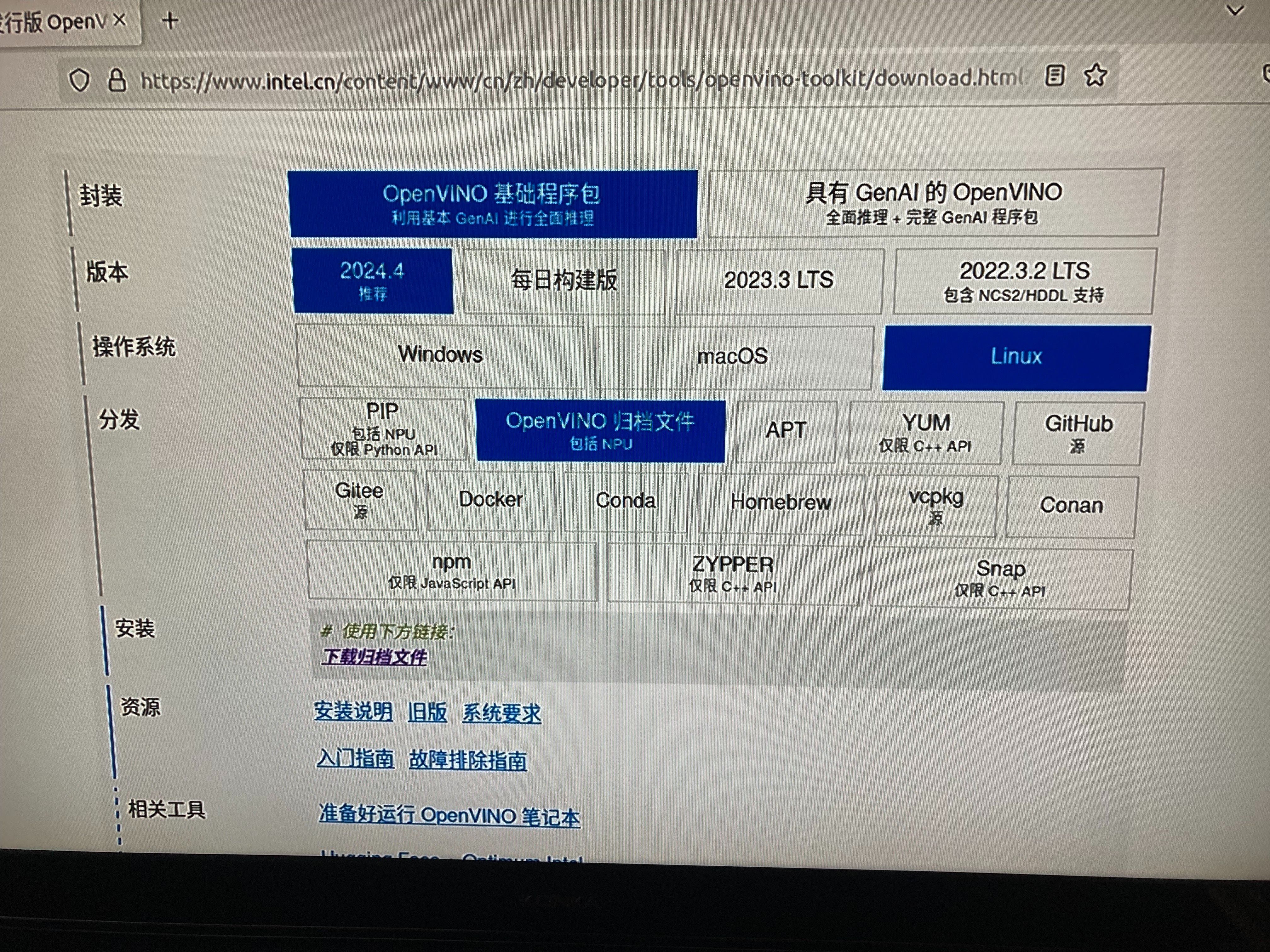
#解压
tar -zxvf l_openvino_toolkit_ubuntu22_2024.3.0.16041.1e3b88e4e3f_x86_64.tgz
#安装依赖包
cd l_openvino_toolkit_ubuntu22_2024.3.0.16041.1e3b88e4e3f_x86_64/
sudo -E ./install_dependencies/install_openvino_dependencies.sh
#配置环境变量
source ./setupvars.sh
2、安装OpenCL runtime package****r/>既然我们要充分发挥Intel 哪吒的集成显卡优势,就还要另外安装OpenCL runtime packages来把模型部署到iGPU上。具体参考官方文档,Configurations for Intel® Processor Graphics (GPU) with OpenVINO™ — OpenVINO™ documentation参考网上经验,我使用deb包的方式进行安装,从https://github.com/intel/compute-runtime/releases/tag/24.35.30872.22先下载11个deb包到开发板上,然后再dpkg安****r/>
#Create temporary directory
mkdir neo
#Download all *.deb packages
cd neo
wget https://github.com/intel/intel-graphics-compiler/releases/download/igc-1.0.17537.20/intel-igc-core_1.0.17537.20_amd64.deb
wget https://github.com/intel/intel-graphics-compiler/releases/download/igc-1.0.17537.20/intel-igc-opencl_1.0.17537.20_amd64.deb
wget https://github.com/intel/compute-runtime/releases/download/24.35.30872.22/intel-level-zero-gpu-dbgsym_1.3.30872.22_amd64.ddeb
wget https://github.com/intel/compute-runtime/releases/download/24.35.30872.22/intel-level-zero-gpu-legacy1-dbgsym_1.3.30872.22_amd64.ddeb
wget https://github.com/intel/compute-runtime/releases/download/24.35.30872.22/intel-level-zero-gpu-legacy1_1.3.30872.22_amd64.deb
wget https://github.com/intel/compute-runtime/releases/download/24.35.30872.22/intel-level-zero-gpu_1.3.30872.22_amd64.deb
wget https://github.com/intel/compute-runtime/releases/download/24.35.30872.22/intel-opencl-icd-dbgsym_24.35.30872.22_amd64.ddeb
wget https://github.com/intel/compute-runtime/releases/download/24.35.30872.22/intel-opencl-icd-legacy1-dbgsym_24.35.30872.22_amd64.ddeb
wget https://github.com/intel/compute-runtime/releases/download/24.35.30872.22/intel-opencl-icd-legacy1_24.35.30872.22_amd64.deb
wget https://github.com/intel/compute-runtime/releases/download/24.35.30872.22/intel-opencl-icd_24.35.30872.22_amd64.deb
wget https://github.com/intel/compute-runtime/releases/download/24.35.30872.22/libigdgmm12_22.5.0_amd64.deb
#Verify sha256 sums for packages
wget https://github.com/intel/compute-runtime/releases/download/24.35.30872.22/ww35.sum
sha256sum -c ww35.sum
#install required dependencies
apt install ocl-icd-libopencl1
#Install all packages as root
sudo dpkg -i *.deb 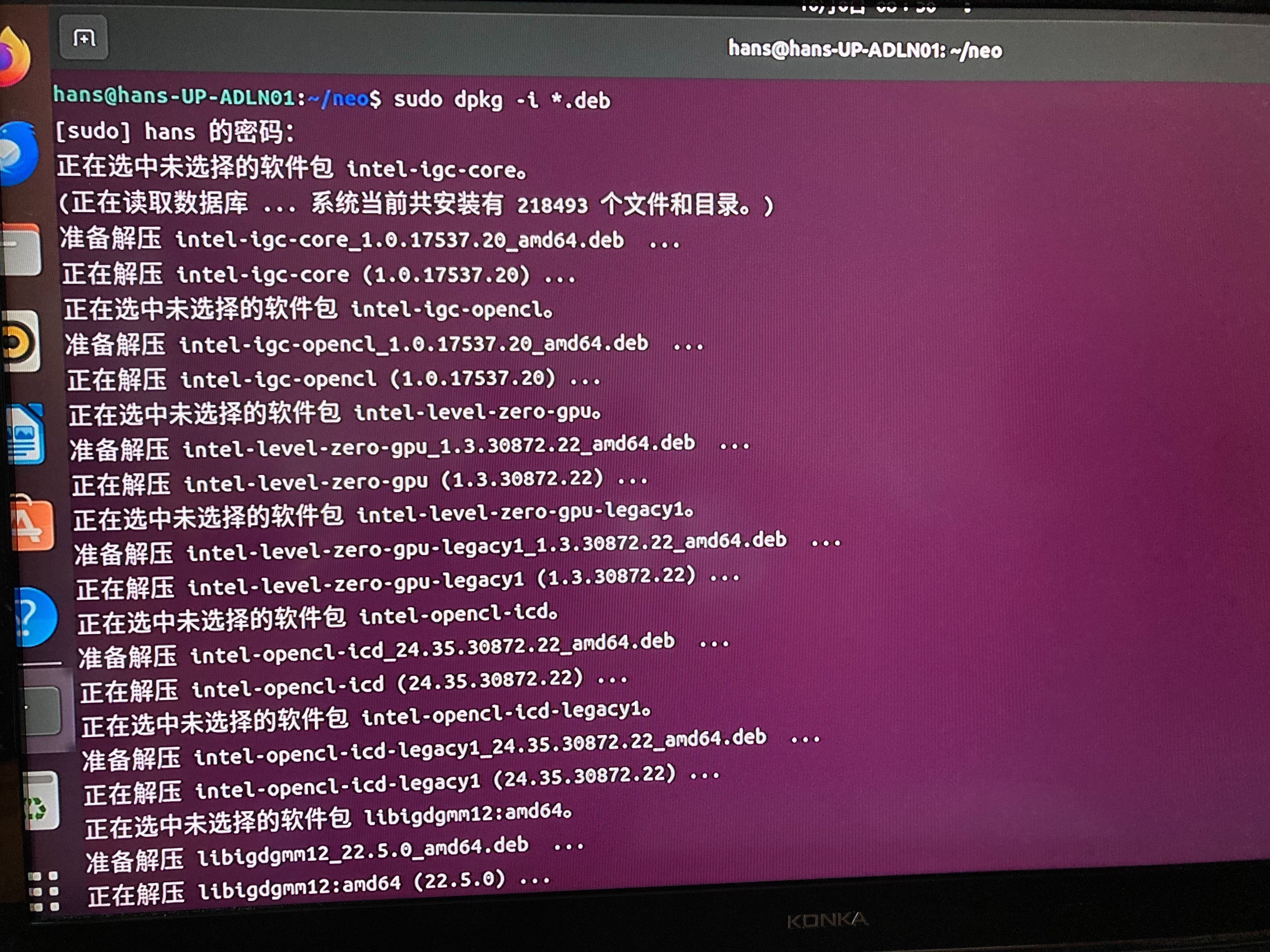
(二)模型下载和转换量化
1、模型下载
本次采用的大模型是Qwen 2.5-0.5B。Qwen2.5是阿里通义团队近期最新发布的文本生成系列模型,基于更富的语料数据集训练,相较于 Qwen2,Qwen2.5 获得了显著更多的知识(MMLU:85+),并在编程能力(HumanEval 85+)和数学能力(MATH 80+)方面有了大幅提升。此外,新模型在指令执行、生成长文本(超过 8K 标记)、理解结构化数据(例如表格)以及生成结构化输出特别是 JSON 方面取得了显著改进。Qwen2.5 模型总体上对各种 system prompt 更具适应性,增强了角色扮演实现和聊天机器人的条件设置功能。Qwen2.5 语言模型支持高达 128K tokens,并能生成最多 8K tokens 的内容。本次使用的是指令调优的0.5B模型,其特点如下:
类型:因果语言模型
训练阶段:预训练与后训练
架构:使用RoPE、SwiGLU、RMSNorm、注意力QKV偏置和绑定词嵌入的transformer***r/>参数数量:0.49亿
非嵌入参数数量:0.36亿
层数:24
注意力头数(GQA):查询14个,键值对2个
上下文长度:完整32,768token,生成最多8192token
下载模型首选魔搭社区,直接下载到Intel哪吒开发板上。
#安装lfs
git lfs install
#下载模型
git clone https://www.modelscope.cn/qwen/Qwen2.5-0.5B-Instruct.git
2、模型转换量化
在部署模型之前,我们首先需要将原始的 PyTorch 模型转换为 OpenVINO™ 的 IR 静态图格式,并对其进行压缩,以实现更轻量化的部署和最佳的性能表现。
(1)环境配置
新建一个虚拟环境,安装依赖。
python3 -m venv openvino_env
source openvino_env/bin/activate
python3 -m pip install --upgrade pip
pip install wheel setuptools
pip install -r requirements.txt
(2)转换和量化
通过 Optimum 提供的命令行工具 optimum-cli,我们可以一键完成模型的格式转换和权重量化任务。
optimum-cli export openvino --model './local_dir' --task text-generation-with-past --weight-format int4 --group-size 128 --ratio 0.8 Qwen2.5-0.5B-Instruct-int4-ov
我们也可以根据模型的输出结果,调整其中的量化参数,包括:
--weight-format:量化精度,可以选择fp32,fp16,int8,int4,int4_sym_g128,int4_asym_g128,int4_sym_g64,int4_asym_g64
--group-size:权重里共享量化参数的通道数量
--ratio:int4/int8 权重比例,默认为1.0,0.6表示60%的权重以 int4 表,40%以 int8 表示
--sym:是否开启对称量化
经过一个稍微漫长的等待,终于,转换成功! 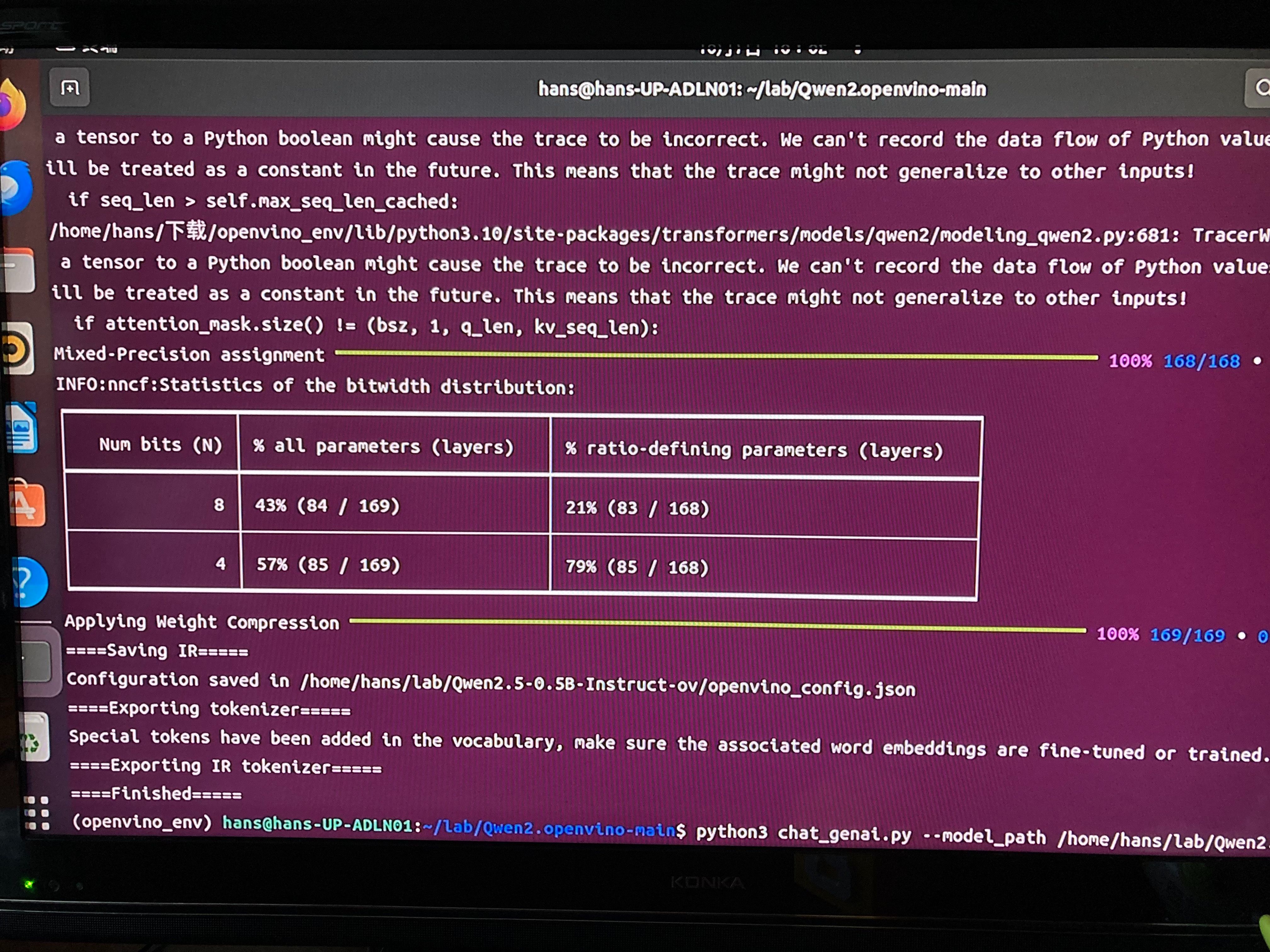
3、模型部署
OpenVINO™ 目前提供两种针对大语言模型的部署方案,一种是基于 Python 接口的 Optimum-intel 工具来进行部署,可以直接用 Transformers 库的接口来部署模型;另一种是GenAI API 方式,它同时支持 Python 和 C++ 两种编程语言,安装容量不到200MB,提供更极致的性能和轻量化的部署方式,更适合边缘设备上部署大模型。
本文采用的是后者,即GenAI API 方式。GenAI API 提供了 chat 模式的构建方法,通过声明 pipe.start_chat()以及pipe.finish_chat(),多轮聊天中的历史数据将被以 kvcache 的形态,在内存中进行管理,从而提升运行效率。
1、创建一个python文件。命名为chat_genai.py
import argparse
import openvino_genai
def streamer(subword):
print(subword, end='', flush=True)
return False
if __name__ == "__main__":
parser = argparse.ArgumentParser(add_help=False)
parser.add_argument('-h',
'--help',
action='help',
help='Show this help message and exit.')
parser.add_argument('-m',
'--model_path',
required=True,
type=str,
help='Required. model path')
parser.add_argument('-l',
'--max_sequence_length',
default=256,
required=False,
type=int,
help='Required. maximun length of output')
parser.add_argument('-d',
'--device',
default='CPU',
required=False,
type=str,
help='Required. device for inference')
args = parser.parse_args()
pipe = openvino_genai.LLMPipeline(arg***odel_path, args.device)
config = openvino_genai.GenerationConfig()
config.max_new_tokens = arg***ax_sequence_length
pipe.start_chat()
while True:
try:
prompt = input('question:\n')
except EOFError:
break
pipe.generate(prompt, config, streamer)
print('\n----------')
pipe.finish_chat()
2、运行流式聊天机器人
python3 chat_genai.py --model_path {your_path}/Qwen2.5-0.5B-Instruct-ov --max_sequence_length 4096 --device GPU
--model_path - OpenVINO IR 模型所在目录的路径。
--max_sequence_length - 输出标记的最大大小。
--device - 运行推理的设备。例如:"CPU","GPU"。
我们来问它一个简单的问题吧,让它自我介绍一下,看看它能不能答出来。 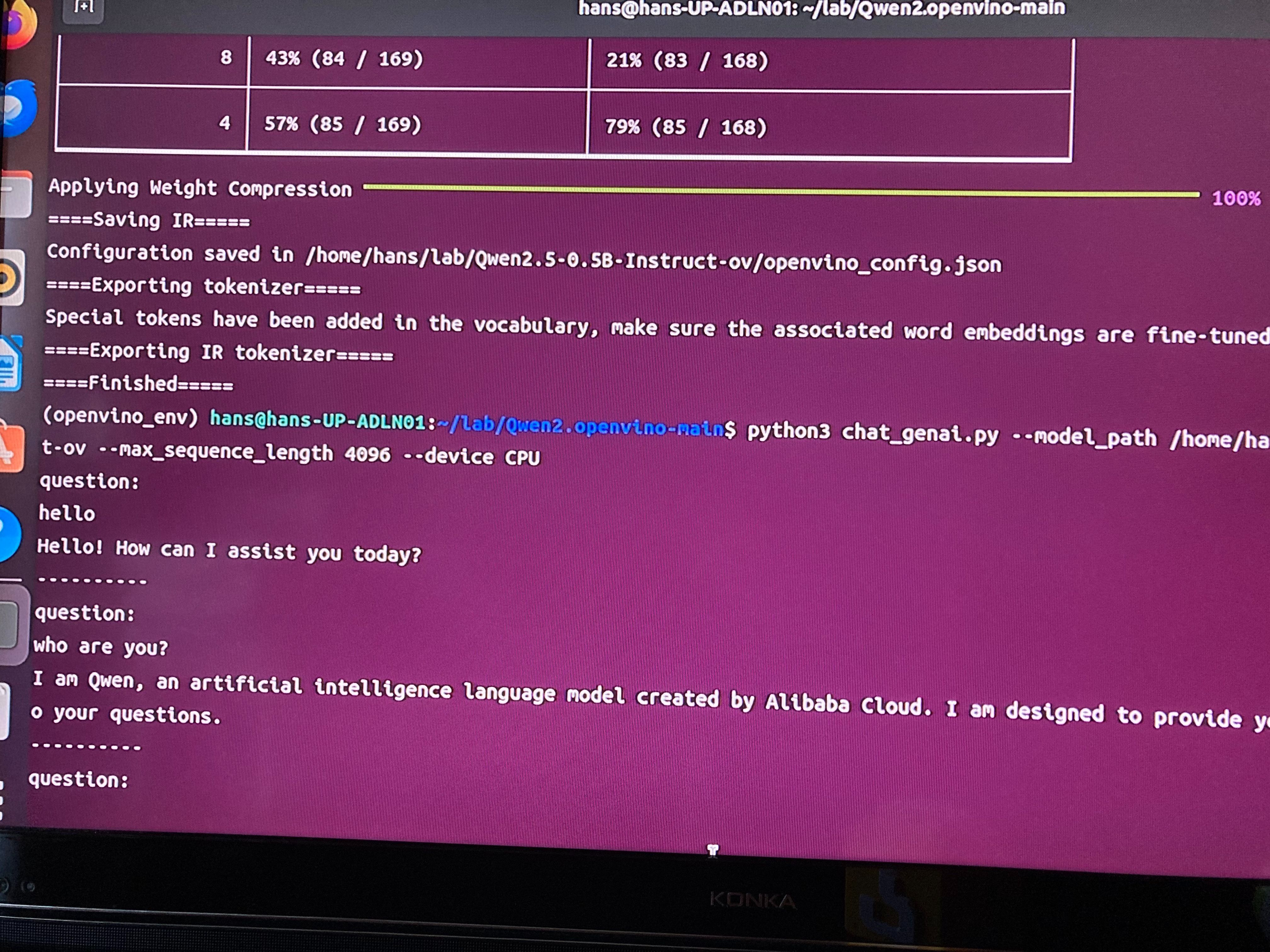
可以,它对自己有个清晰的认识,阿里巴巴开发的大语言人工智能模型。
三、Intel 哪吒开发套件上运行大模型Phi-3.5-mini
还不死心,继续上难度,再换一个尺寸更大的模型,看看Intel哪吒是否hold住?
这次我们选用的是Phi-3.5-mini,它是微软推出的新一代 AI 模型系列中的轻量级模型,专为资源受限的环境设计,特别适合在资源受限的环境中进行复杂的语言处理任务。该模型具有以下特点:
模型参数和结构:
Phi-3.5-mini 拥有38亿参数,是一个密集的仅解码器Transformer模型,使用与Phi-3 Mini相同的分词器。
该模型基于Phi-3的数据集构建,包括合成数据和经过筛选的公开网站数据,重点关注高质量、推理密集的数据。
应用和性能:
Phi-3.5-mini 特别适合在嵌入式系统和移动应用中进行快速文本处理和代码生成。
该模型在基准测试中的表现超越了GPT4o、Llama 3.1、Gemini Flash等同类模型,显示出其强大的性能。
设计目标和适用场景:
针对基础快速推理任务设计,适合在内存和算力受限的环境中运行,支持128k上下文长度。
该模型在处理长达128K个token的长上下文方面表现出色,这使其在多种语言处理任务中都非常有效。
技术优势:
经过严格的增强过程,包括监督微调和直接首选项优化,以确保精确地遵循指令和实施可靠的安全措施。
支持多语言处理和多轮对话能力,优化了处理高质量、推理密集数据的能力。
1、下载模型
这次我们偷懒一下,直接下载已经转换好的IR文件到Intel哪吒开发板上。
huggingface-cli download --resume-download OpenVINO/Phi-3-mini-4k-instruct-int4-ov --local-dir Phi-3-mini-4k-instruct-int4-ov
参数规模3.8B的Phi-3.5-mini,转换成IR格式后,模型大小为2.5G。
2、运行流式聊天机器人
继续采用GenAI API 方式,用iGPU推理。
python3 chat_genai.py --model_path {your_path}/Phi-3-mini-4k-instruct-int4-ov --max_sequence_length 4096 --device GPU 这次问它一个难一点的问题,比较一下python和rust两种编程语言的优劣。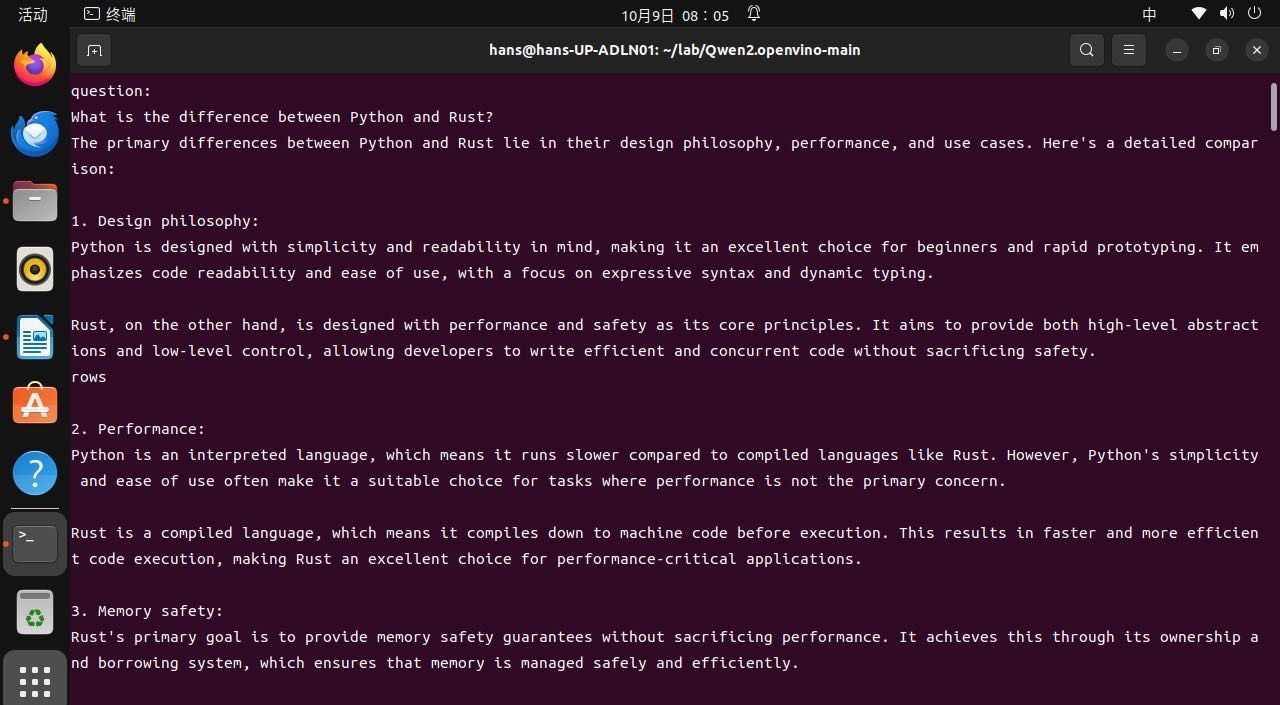
Phi-3.5模型真的名不虚传!简直人生开挂了,输出速度目测每秒10个token,整整持续输出了二十多分钟,共2903字,算上标点符合16285个。

令人难以想象这是在一个单片机上跑大模型的效果,要么是Phi-3.5模型,要么是Intel 哪吒厉害,要么是微软和英特尔联手特别厉害!
四、总结与鸣谢
在Intel哪吒开发套件上,配合OpenVINO,可以非常快速便捷的离线部署大模型,特别是一些SLM模型,非常适合做智能硬件的开发,很好地赋能创客基于成熟硬件,打造端云协同的AI应用。或者重新定义全新硬件,开发软硬件一体的AI产品。
最后,再次感谢Intel组织的这次2024 Intel®“走近开发者”互动活动让我有机会能试用到哪吒开发套件,也感谢OpenVINO的实战workshop,给我们这么好用的大模型工具。
参考文档:
1、实战精选 | 5分钟利用 OpenVINO™ 部署 Qwen2.5 https://community.modelscope.cn/66f10c6b2db35d1195eed3c8.html
2、开发者实战丨如何利用 OpenVINO™ 部署 Phi-3.5 全家桶。 https://mp.weixin.qq.com/s/yROq_Zu3G1a5x8eV7TUmDA