省钱还高效!OPEA+Dify在Intel® Arc™ GPU上构建基于DeepSeek的RAG工作流
 openlab_96bf3613
更新于 11月前
openlab_96bf3613
更新于 11月前
近年来,大语言模型(LLM)在问答系统、智能助手、文档检索等场景大放异彩。尤其是 RAG(Retrieval-Augmented Generation,检索增强生成)架构,通过结合“检索 + 生成”,在准确性、个性化、可控性等方面表现出强大优势。
为什么选择OPEA+Dify 打造RAG
RAG允许将私有数据纳入回答范围,可以显著降低模型幻觉,提升回答的准确度,在企业知识库问答,客服机器人,技术文档检索等领域表现优异。但理想很丰满,现实却很骨感。
当我们真的动手构建一个高质量的 RAG 系统时,现实问题接踵而至。
痛点一:部署LLM成本高,技术门槛大。
目前主流的LLM推理方案多数依赖Nvidia的GPU(如A100, L40, 4090等),成本相对较高。而且用户需要构建推理的各个组件,有一定的开发成本和试错成本。
痛点二: 公有云服务难以满足数据隐私需求
如果你的项目涉及企业的内部资料,敏感知识,员工行为数据等,在使用SaaS模型服务(如 GPT-4 等) 往往会面临数据上传风险,使用行为被记录,缺乏对模型的可控性等问题。
面对以上痛点,你会发现使用低成本的Intel® Arc™ GPU,借助OPEA的快速部署,用Dify构建灵活的RAG工作流的私有化部署将成为你的最优选项。
OPEA+Dify+DeepSeek打造高性价比、可控的私有化RAG系统
OPEA(Open Platform for Enterprise AI) 的使命,是打造一个开放、灵活、强大的平台生态,支持多模型、多服务商组合使用,帮助企业快速构建具备高度可控性的生成式 AI 解决方案。
OPEA 提供完整的三大核心能力:
LLM 推理服务
Embedding 向量化服务
Rerank 重排序服务
所有服务均可基于Intel® Arc™ GPU 部署,显著降低硬件成本。同时,OPEA支持在本地或私有云环境中运行,实现数据全流程的本地化处理与隐私可控。OPEA已对主流开源模型做过深入优化,兼具性能与兼容性。
搭配使用的 Dify,是一个极易上手的 LLM 应用开发平台,支持:
可视化配置 RAG 工作流
灵活导入自定义数据集、向量库
接入自定义模型服务
提供 Web UI 与 API 双入口,助力快速上线产品
DeepSeek 是当前国内最受欢迎的大语言模型之一,以其出色的理解能力和强大的多轮对话表现,在开源社区和企业场景中迅速走红。当前,OPEA 已对 DeepSeek 模型进行了适配与优化,支持其在Intel® Arc™ GPU 环境下流畅运行,可直接用于私有化部署,作为 RAG 系统中的核心生成引擎。
这套组合方案,不仅大幅降低了构建 RAG 系统的部署成本,更保障了数据安全性与可控性,真正为中小企业与独立开发者提供了一套 “能负担、能上线、能落地” 的一站式 GenAI 应用解决方案。
OPEA组件一键部署
目前基于OPEA的LLM推理服务在Ubuntu22.04 上可以发挥出最优性能,请先参照“成本打到6万以下 手把手教你用4路锐炫™ 显卡+至强® W跑DeepSeek”安装操作系统,以及安装 Intel® Arc™ GPU 驱动。驱动安装完成后,即可使用docker compose一键部署基于DeepSeek模型的OPEA推理服务以及其它RAG系统关键服务。
创建docker compose 部署文件 compose.yaml。
mkdir ~/opea
cd ~/opea
vim compose.yaml
在compose.yaml 中加入以下内容:
services:
tei-embedding-service:
image: ghcr.io/huggingface/text-embeddings-inference:cpu-1.5
container_name: tei-embedding-server
ports:
- "6006:80"
volumes:
- "/opt/opea/data:/data"
shm_size: 1g
command: --model-id ${EMBEDDING_MODEL_ID} --auto-truncate
tei-reranking-service:
image: ghcr.io/huggingface/text-embeddings-inference:cpu-1.5
container_name: tei-reranking-server
ports:
- "8808:80"
volumes:
- "/opt/opea/data:/data"
shm_size: 1g
environment:
HUGGINGFACEHUB_API_TOKEN: ${HUGGINGFACEHUB_API_TOKEN}
HF_HUB_DISABLE_PROGRESS_BARS: 1
HF_HUB_ENABLE_HF_TRANSFER: 0
command: --model-id ${RERANK_MODEL_ID} --auto-truncate
vllm-service:
image: intel****ytics/ipex-llm-serving-xpu:2.2.0-b14
container_name: vllm-service
ports:
- "9009:80"
privileged: true
devices:
- "/dev/dri:/dev/dri"
volumes:
- "/opt/opea/data:/data"
shm_size: ${SHM_SIZE:-8g}
environment:
HUGGINGFACE_HUB_CACHE: "/data"
LLM_MODEL_ID: ${LLM_MODEL_ID}
VLLM_TORCH_PROFILER_DIR: "/mnt"
DTYPE: ${DTYPE:-float16}
QUANTIZATION: ${QUANTIZATION:-fp8}
MAX_MODEL_LEN: ${MAX_MODEL_LEN:-2048}
MAX_NUM_BATCHED_TOKENS: ${MAX_NUM_BATCHED_TOKENS:-4000}
MAX_NUM_SEQS: ${MAX_NUM_SEQS:-256}
TENSOR_PARALLEL_SIZE: ${TENSOR_PARALLEL_SIZE:-1}
healthcheck:
test: ["CMD-SHELL", "curl -f http://localhost:9009/health || exit 1"]
interval: 10s
timeout: 10s
retries: 100
entrypoint: /bin/bash -c "export CCL_WORKER_COUNT=2 &&
export SYCL_CACHE_PERSISTENT=1 &&
export FI_PROVIDER=shm &&
export CCL_ATL_TRANSPORT=ofi &&
export CCL_ZE_IPC_EXCHANGE=sockets &&
export CCL_ATL_SHM=1 &&
export USE_XETLA=OFF &&
export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=2 &&
export TORCH_LLM_ALLREDUCE=0 &&
export CCL_SAME_STREAM=1 &&
export CCL_BLOCKING_WAIT=0 &&
export ZE_AFFINITY_MASK=$GPU_AFFINITY &&
python -m ipex_llm.vllm.xpu.entrypoints.openai.api_server \
--served-model-name $LLM_MODEL_I\
--model $LLM_MODEL_ID \
--port 80 \
--trust-remote-code \
--block-size 8 \
--gpu-memory-utilization 0.95 \
--device xpu \
--dtype $DTYPE \
--enforce-eager \
--load-in-low-bit $QUANTIZATION \
--max-model-len $MAX_MODEL_LEN \
--max-num-batched-tokens $MAX_NUM_BATCHED_TOKENS \
--max-num-seqs $MAX_NUM_SEQS \
--tensor-parallel-size $TENSOR_PARALLEL_SIZE \
--disable-async-output-proc \
--distributed-executor-backend ray"
networks:
default:
driver: bridge
通过环境变量分别指定需要运行的LLM Model, Embedding Model,和Rerank model。
export EMBEDDING_MODEL_ID="BAAI/bge-base-en-v1.5"
export RERANK_MODEL_ID="BAAI/bge-reranker-base"
export LLM_MODEL_ID="deepseek-ai/DeepSeek-R1-Distill-Qwen-32B"
在~/opea路径下通过以下命令运行opea的服务。该命令会下载docker镜像,并启动opea服务。
docker compose up -d
首次启动会花费较长的时间。服务首次启动时需要从远程下载容器镜像以及模型数据。
服务启动完成后,可以使用docker compose ps检查服务的运行状态。 此时会启动三个服务,分别是Embedding服务,Reranking 服务和LLM推理服务,分别暴露在6006,8808和9009端口。
至此,OPEA服务的精简部署完成了,接下来就是部署Dify。

Dify快速部署
我们以Dify社区版为例演示在Dify上构建OPEA的RAG工作流。Dify的详细部署流程可以参考Dify社区版部署文档。这里可以依照下列命令快速部署。git clone https://github.com/langgenius/dify.git
cd dify/docker
cp .env.example .env
docker compose up -d
Dify部署完成后,我们就可以通过主机IP的80端口访问Dify的WebUI进行工作流的配置。
我们需要创建一个管理员账户,并使用管理员账户登录。
首先我们需要安装两个模型供应商。登录完成后,点击右上角的用户头像→ 设置→ 模型供应商,安装OpenAI-API-compatible和Text Embedding Inference两个供应商。安装成功后可以在待配置中看到两个模型供应商。

Dify关联OPEA模型服务
接下来通过配置模型供应商调用OPEA提供的模型服务。首先配置LLM模型。点击OpenAI-API-compatible 供应商的添加模型。模型类型选择LLM,模型名称对应环境变量设置的模型名称deepseek-ai/DeepSeek-R1-Distill-Qwen-32B。API endpoint URL 设置为 http://$host_ip:9009/v1 (将$host_ip替换为你的实际IP地址,下文同样处理), 设置完成后点击保存。
这是RAG工作流的核心推理服务,我们将在工作流中通过LLM模型供应商调用DeepSeek的强大推理能力。
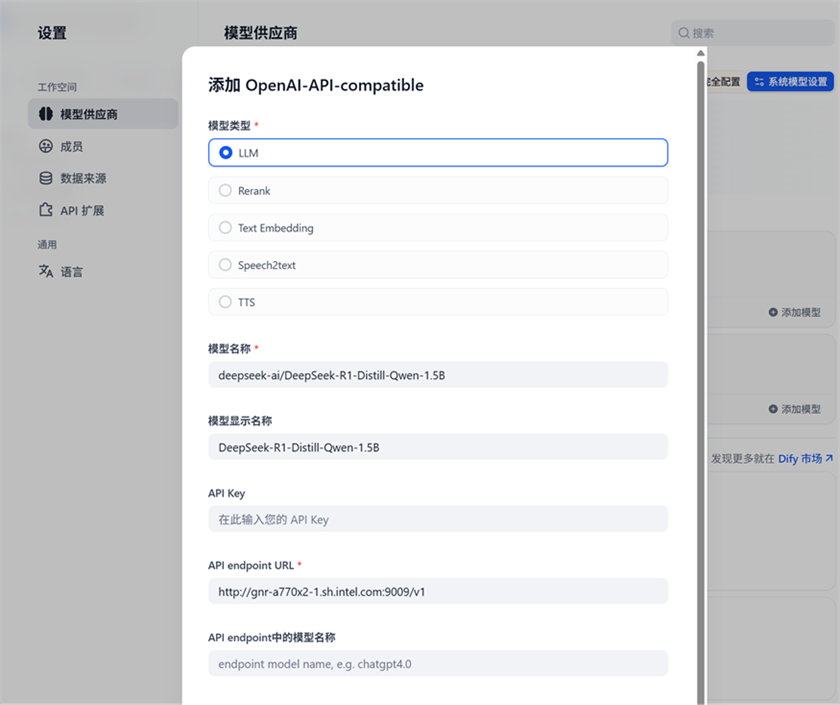
然后在Text Embedding Inference 供应商中增加Embedding模型。 点击Text Embedding Inference的添加模型,选择 Text Embeding, 输入模型名称BAAI/bge-base-en-v1.5, 然后填写服务器URL http://$host_ip:6006, 点击保存。
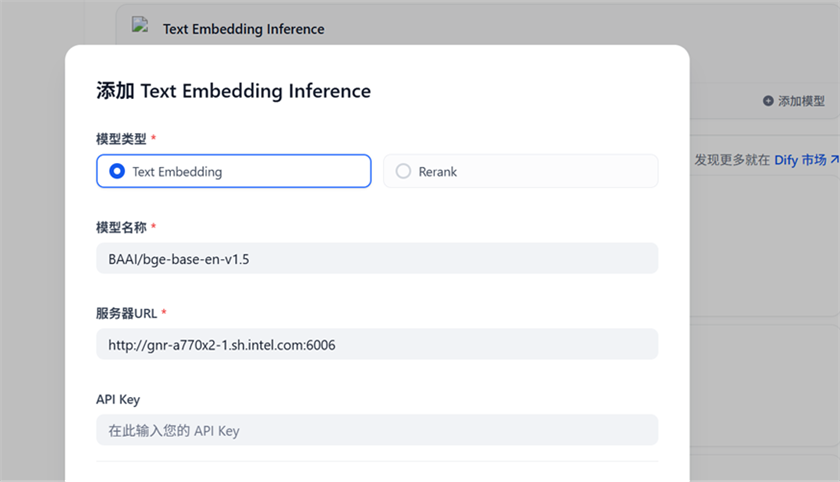
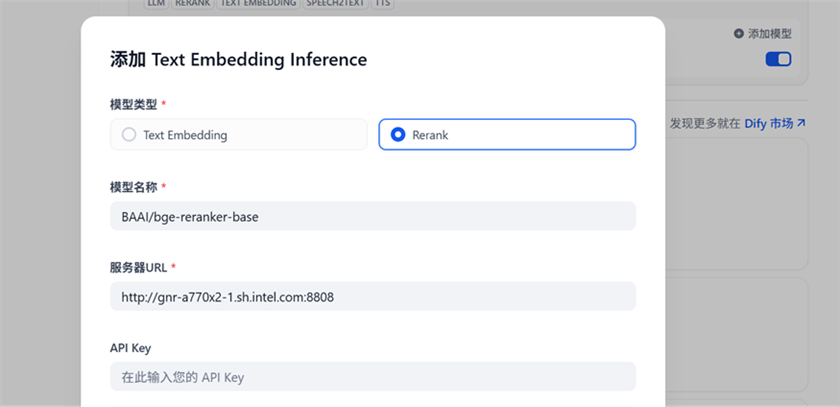
在Text Embedding Inference 供应商中增加ReRanking模型。 点击Text Embedding Inference供应商的添加模型,选择 Rerank, 输入模型名称BAAI/bge-reranker-base, 然后填写服务器URL http://$host_ip:8808, 点击保存。
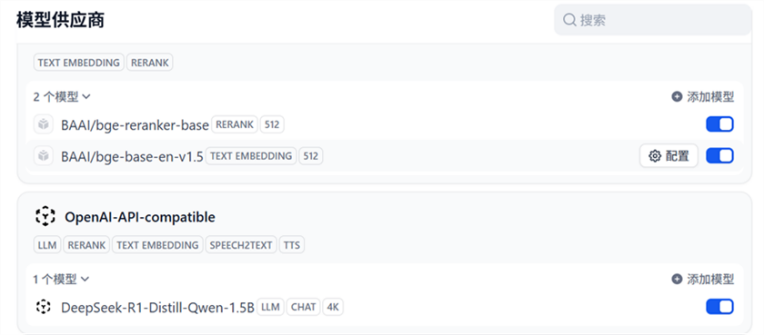
配置完成后,即可在模型供应商中看到如下结果。至此,OPEA的模型服务已经关联到了Dify,我们可以在知识库与工作流的配置中使用OPEA服务。
知识库配置
在知识库中点击创建知识库,此时可以导入已有文本,或者创建一个空的知识库。指定知识库的名字为OPEA-Knowledge, 索引方式选择高质量,Embedding模型选择前面配置好的BAAI/bge-base-en-v1.5。Rerank模型选择BAAI/bge-reranker-base ,配置完成后保存。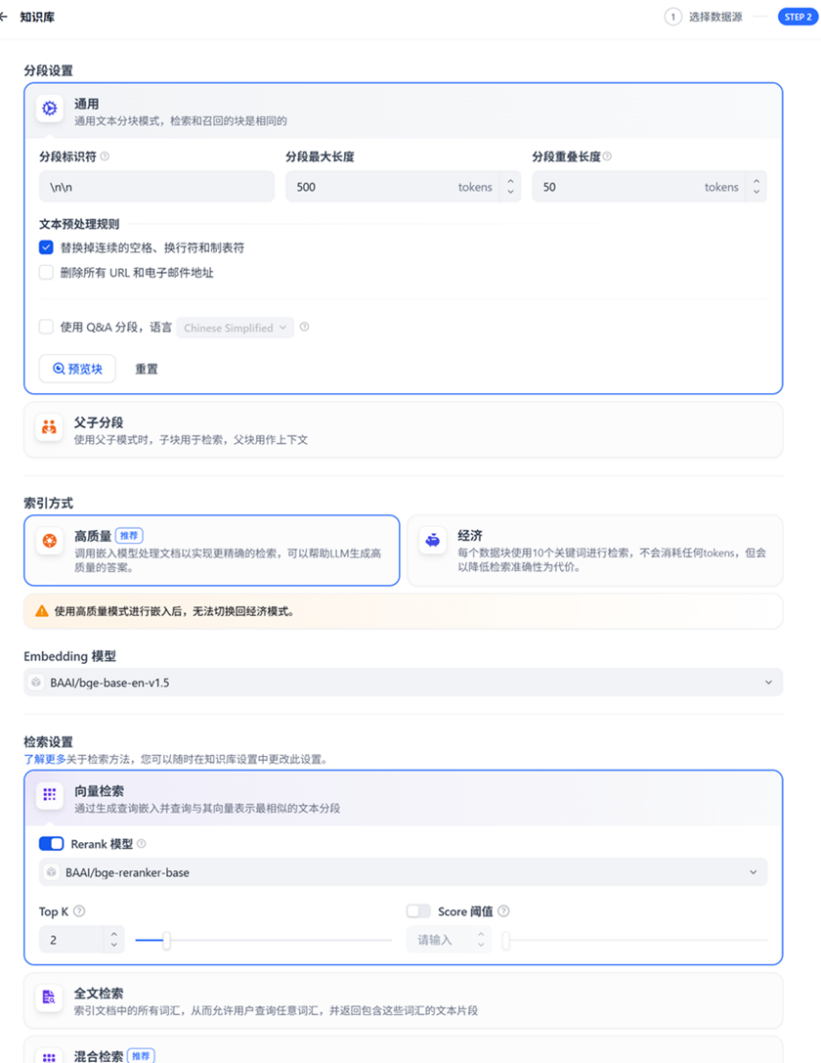
自定义RAG工作流
在工作室中,点击创建空白应用,新建一个chatflow,应用名称为OPEA-RAG。依次增加开始/知识检索/LLM/直接回复模块,构建一个简易的RAG工作流。默认情况下新建的工作流会自动添加开始/LLM/直接回复模块。只需在开始和LLM之间增加一个知识检索模块即可配置一个简易的RAG工作流。

在知识检索模块中增加前面创建的知识库OPEA-Knowledge。
然后在LLM模块中,选择前面设置的LLM模型deepseek-ai/DeepSeek-R1-Distill-Qwen-32B,使用知识检索的结果作为上下文,最后基于上下文构建一个提示词模板。这样我们的就可以将组织好的上下文传递给OPEA启动的DeepSeek大语言模型进行处理了。
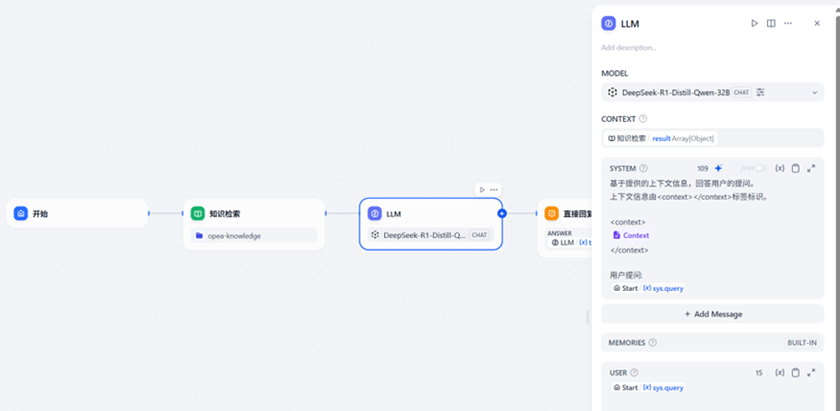
完成后,即可通过预览或者发布对工作流进行测试。
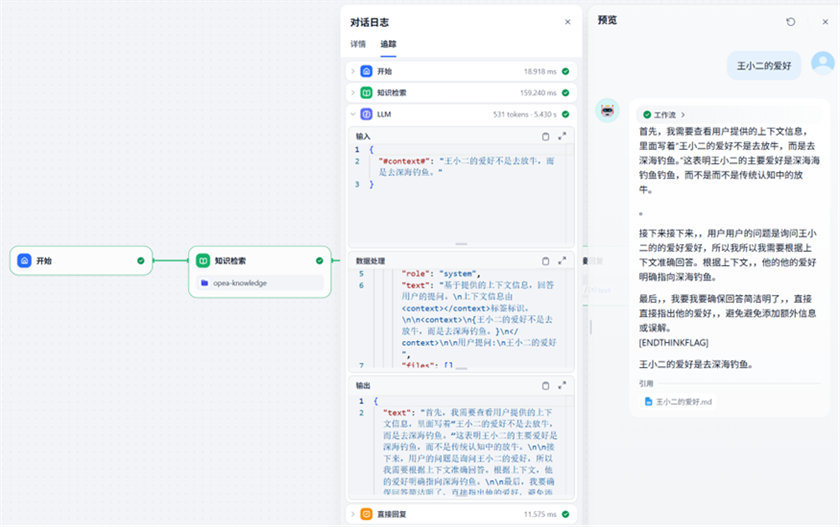
至此,一个基于 OPEA + Dify 构建、集成 DeepSeek 模型的简易 RAG 工作流已成功搭建完成。
借助 Intel® Arc™ GPU 的低成本计算优势,结合 DeepSeek 强大的推理能力与 RAG 架构在知识调用上的精准表现,该方案不仅显著降低了部署门槛,更为企业智能化升级提供了一个高性价比、可快速落地的路径。
在 OPEA 的加持下,依托 Intel® Arc™ GPU,你可以轻松实现基于 DeepSeek 的 RAG 工作流的本地私有化部署,既保障了数据隐私安全,又大幅降低了使用和维护成本。
OPEA 不止是工具,更是打造企业级 AI 的最强底座
如果你希望构建一个更强大、更灵活的生成式AI系统,OPEA 就是那个值得深入挖掘的“全能选手”。相比 Dify 提供的一个上手友好的前端框架,OPEA 从架构到服务能力都拉满了“企业级可落地”的标准线。OPEA 核心架构由 Microservices、Megaservices、Gateways 三大模块构成[1] ,为复杂 AI 工作流提供了高可扩展性与高可用性保障。你不仅可以轻松搭建 ChatBot,更可以构建功能更复杂、链路更长、上下游联动的 RAG 系统 和 AI Agent 应用。
例如:
代码生成/优化 Agent
用 OPEA 的 CodeGen 服务,支持自动代码补全、重构建议、单元测试生成等功能,一个 Agent 顶一个资深工程师。
多模态 AI
支持文生图(Text2Image)、图生图(Image2Image)、图文混合理解等微服务模块,快速对接你的内容平台或创意引擎。
知识密集型企业应用
搭配私有化知识库 + 多模型协同策略,RAG系统能高效整合文档、图谱、数据库等多源信息,构建企业级“AI大脑”。
OPEA 不是为了“演示能跑”,而是真正为“能落地、能扩展、能支撑业务”而生。
企业需要的那一套,它全有。你想象得到的未来,它已经在路上。
欢迎持续关注 OPEA 社区,第一时间获取更新与实践经验。
0个评论