一键加载GGUF!OpenVINO™ GenAI让大模型推理更快更轻
 openlab_96bf3613
更新于 5月前
openlab_96bf3613
更新于 5月前
作者:武卓,AI软件布道师;杨粟, AI软件解决方案工程师;陈天萌,AI软件解决方案工程师
引言
大语言模型(LLM)正日益被优化,以适应本地端和边缘设备的部署。在众多轻量化推理格式中,GGUF(General Graph Unified Format,通用图统一格式)是最受欢迎的格式之一。它由 llama.cpp 社区提出,用于高效存储量化后的模型权重,以实现快速的 CPU 和 GPU 推理。
与传统的 PyTorch 或 ONNX 格式不同,GGUF 专为运行时效率而设计。它将模型张量以紧凑的二进制结构存储,支持内存映射(memory mapping)与低延迟加载。这使得它成为社区驱动模型的首选格式,尤其适用于在 AI PC 上进行本地、离线推理的场景。
然而,虽然 GGUF 模型可以在 llama.cpp 中无缝运行,但过去若要在英特尔硬件上加速推理,仍需先将 PyTorch 模型离线转换为 OpenVINO™ IR 格式(参考工具 GGUF-to-OpenVINO:https://github.com/yangsu2022/GGUF-to-OpenVINO)。
有了最新的 OpenVINO™ 2025.3 版本,这一情况发生了改变。
开发者现在可以直接加载 GGUF 模型,即时创建 OpenVINO™ 计算图,并在 CPU/GPU 上进行推理。这一新的 GGUF Reader 功能 构建了社区模型与 OpenVINO™ 优化运行时之间的桥梁,实现了跨 CPU 与 GPU 的统一工作流。
目前,OpenVINO™ GenAI 2025.3 已支持部分 GGUF 量化类型(Q4_0、Q4_K_M、Q8_0、FP16),并可在 CPU 与 GPU 上运行。该功能目前为预览版,支持的模型拓扑包括 SmolLM、Qwen2.5、Qwen3 以及 Llama-3.1 / 3.2。
对于其他模型或架构,建议仍通过 huggingface/OpenVINO/llm(https://huggingface.co/OpenVINO/llm) 下载官方 IR 模型,或使用 optimum-intel 工具将 PyTorch 模型转换为 IR 格式。详情请参考 Generative Model Preparation Using Optimum-intel (Generative Model Preparation Using Optimum-intel:https://docs.openvino.ai/2025/openvino-workflow-generative/genai-model-preparation.html)。
接下来,让我们一起看看如何通过 OpenVINO™ GenAI 快速运行 GGUF 模型推理!
目录
1. 工作流概览
2. 分步教程
- 安装 OpenVINO™ GenAI
- 使用 LLMPipeline 加载 GGUF 模型
- 生成文本
- 保存转换后的模型以便重用
3. 总结
1. 工作流概览
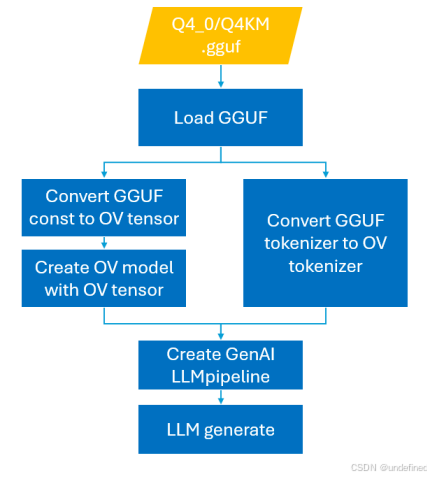
新的 GGUF Reader 工作流非常简单,如下图所示:
核心特性:
一键加载:在单个 API 调用中,直接读取、解包并转换 GGUF 压缩张量为 OpenVINO™ 格式。
即时图构建:无需中间 PyTorch 模型,免去使用 optimum-cli 进行离线转换的步骤。
集成反量化(Dequantization):在推理过程中自动执行反量化,省去额外存储和预处理。
依赖简化:不再依赖 PyTorch 或 Optimum。
模型保存:可将生成的 ov::Model 序列化为 IR 格式,以便下次更快构建 LLMPipeline。
2. 分步教程
第一步:安装 OpenVINO™ GenAI
确保已安装最新版的 OpenVINO™ GenAI(2025.3),可使用以下命令:
pip install openvino-genai
第二步:使用 OpenVINO™ GenAI 加载 GGUF 模型
要使用 GGUF 模型执行推理,只需在创建 LLMPipeline 对象时提供 .gguf 文件路径:
import openvino_genai
pipe = openvino_genai.LLMPipeline("SmolLM2-135M.F16.gguf", "CPU")
第三步:生成文本
config = openvino_genai.GenerationConfig()
config.max_new_tokens = 100
pipe.generate("The Sun is yellow because", config)
第四步:保存转换后的模型以便重用
为加快后续加载速度,可启用模型序列化:
pipe.enable_save_ov_model = True
output = pipe.generate("Once upon a time", config)
这会在同目录下生成以下 OpenVINO™ IR 文件:
SmolLM2-135M.F16.xmlSmolLM2-135M.F16.bin
之后即可直接加载这些 IR 文件:
pipe = ov_genai.LLMPipeline("SmolLM2-135M.F16.xml", "GPU")
进阶用法(视频示例中演示)
enable_save_ov_model 属性会将从 GGUF 文件生成的 OV 模型(包含 tokenizer)序列化为 XML/BIN 文件。
示例视频演示了两种运行方式:
1. 直接输入 GGUF 文件;
2. 输入转换后生成的 OV 模型路径。
可通过设置环境变量 OPENVINO_LOG_LEVEL 查看加载和序列化时间。
示例代码请参考官方博客:OpenVINO™ Blog | OpenVINO™ GenAI GGUF Feature Update:https://intel-openvino-blog.webflow.io/blog-posts/openvino-genai-gguf-feature-update。
总结
通过 OpenVINO™ GenAI 2025.3 新增的 GGUF Reader,开发者可以轻松在英特尔硬件上运行社区量化的 LLM 模型,打通从 GGUF 到高效推理的完整路径。
无论你是在测试轻量级模型 SmolLM,还是部署更复杂的 Qwen 与 Llama 系列,OpenVINO™ 都能提供:
更简洁的工作流
更快的模型加载
一致的 CPU / GPU 推理体验
这一特性标志着 AI PC 无缝模型部署 迈出了重要一步,将开源社区的灵活性与英特尔的优化能力完美融合。
延伸阅读
OpenVINO™ Blog | OpenVINO™ GenAI 支持 GGUF 模型:https://intel-openvino-blog.webflow.io/blog-posts/openvino-genai-supports-gguf-models
OpenVINO™ Blog | OpenVINO™ GenAI GGUF 功能更新:
https://intel-openvino-blog.webflow.io/blog-posts/openvino-genai-gguf-feature-update
相关资源
OpenVINO™ GenAI 官方文档:https://docs.openvino.ai/2025/index.html
OpenVIN™ Notebooks 示例:https://github.com/openvinotoolkit/openvino_notebook***r/>
反馈与问题提交:https://github.com/openvinotoolkit/openvino.genai/issues