开箱即用的文档解析:PaddleOCR-VL + OpenVINO™(表格 / 图表 / 公式一次搞定)
 openlab_96bf3613
更新于 2月前
openlab_96bf3613
更新于 2月前
作者: 武卓,赵红博
如果你最近在做文档智能(合同/票据/财报/论文/报表),你一定遇到过这种尴尬:传统 OCR 能把字识别出来,但一到表格、图表、公式,要么结构丢失,要么后处理成本爆炸。PaddleOCR-VL 的出现,把“文档解析”从 OCR 升级成了更接近“读懂页面”的能力:同一套模型可以覆盖 OCR / Table / Chart / Formula 等任务,并且资源效率很高,适合做端侧落地。
好消息是:在 OpenVINO™开发者与社区贡献的推动下,PaddleOCR-VL 已经可以通过 OpenVINO™ 转成 IR模型格式 并在 Intel AI PC、独立显卡等平台上完成推理加速;相关流程也沉淀成了一个可复现的开源仓库:从 IR 获取/转换、PyTorch 与 OpenVINO™ 输出对齐验证,到 Gradio 交互 Demo,基本做到“照着跑就能跑起来”。
接下来,我们不讲概念堆砌,只做三件事:
-
搭好环境,并拿到可用的 OpenVINO™ IR 模型
-
跑通推理,并验证 PyTorch vs OpenVINO™ 输出一致性(parity)
-
一键起一个 Gradio Demo,做到“可交互、可展示、可复现”
PaddleOCR-VL 简介:它“先进”在哪?
PaddleOCR-VL 是面向“文档解析(document parsing)”的视觉语言模型体系,核心模型为 PaddleOCR-VL-0.9B。它把 NaViT 风格的动态分辨率视觉编码器与轻量 ERNIE-4.5-0.3B 语言模型结合,使模型能在较低资源消耗下更好地处理复杂文档元素(文本、表格、公式、图表等),并覆盖多语言场景(https://github.com/PaddlePaddle/PaddleOCR 提到可支持 109 种语言)。
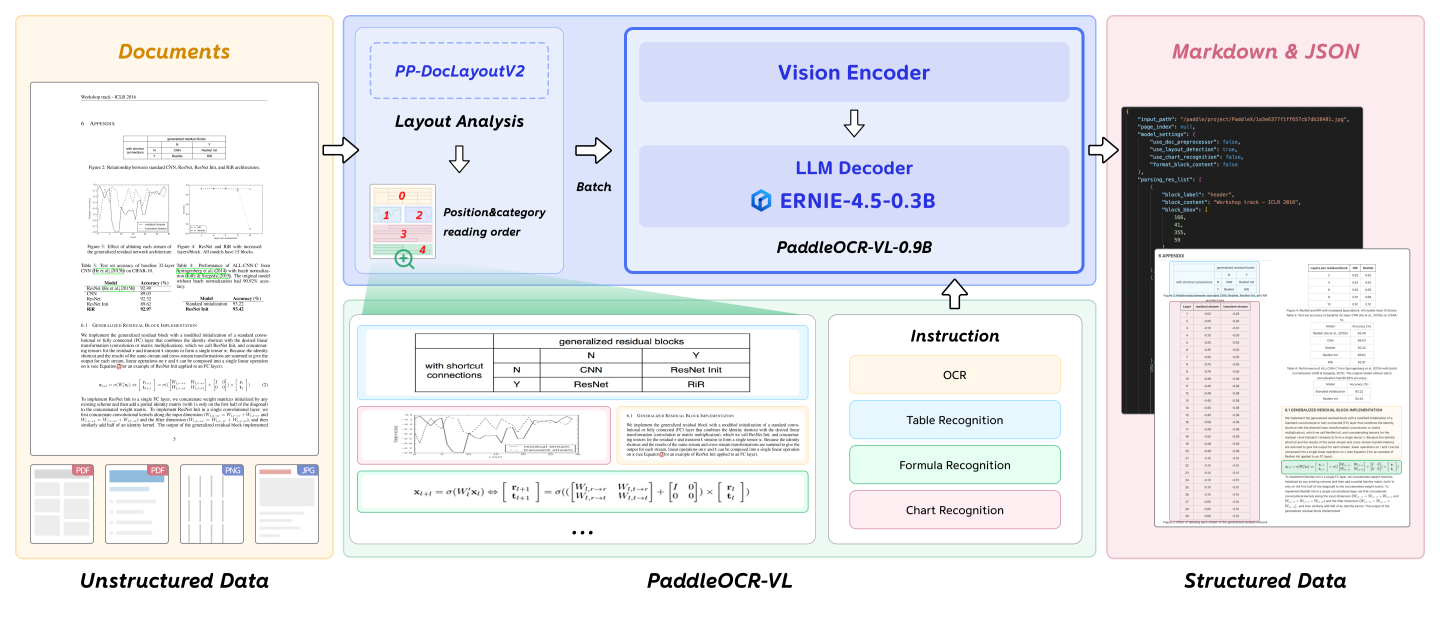
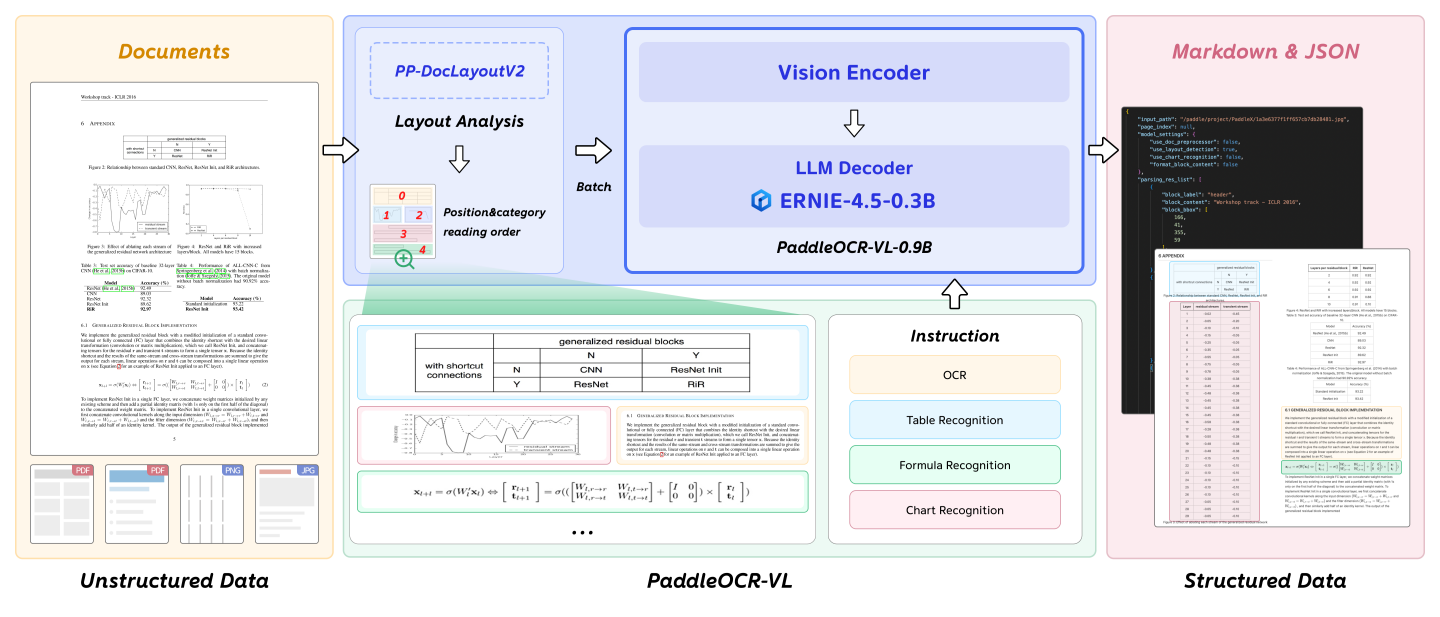
用OpenVINO™加速及部署PaddleOCR-VL的分步指南
步骤1:克隆 PaddleOCR-VL on OpenVINO™ 仓库(把“脚手架”先拿到手)
要把 PaddleOCR-VL 跑在 OpenVINO™ 上,最省心的方式就是直接从社区已经打通的仓库开始。这个仓库把你最容易踩坑的几件事都准备好了:IR 获取/转换脚本、PyTorch vs OpenVINO™ 的输出对齐验证(parity)、以及 Gradio 可视化 Demo。换句话说,你不需要从零搭“转换链路”和“推理链路”,照着跑就能复现。
git clone https://github.com/zhaohb/paddleocr_vl_ov.gitcd paddleocr_vl_ov
步骤2:为推理与验证安装依赖(Python 环境一次配好)
跑 PaddleOCR-VL 这种“文档解析 + VLM 推理”的工程,最怕的不是代码,而是依赖冲突。所以这里建议你直接按仓库的推荐方式来:Python 3.12 + requirements + OpenVINO™(含 tokenizers/genai)。先把环境配到“能稳定跑起来”,后面再考虑升级版本或做性能实验。
-
创建并激活 Python 环境(推荐 conda)
conda create -n paddleocr_vl_ov python=3.12conda activate paddleocr_vl_ov
-
安装仓库依赖
pip install -r requirements.txt

-
安装 OpenVINO™(含 tokenizers / genai)
仓库示例使用的是预发布(nightly/rc)轮子,目的是确保推理流水线所需组件齐全。你可以先照抄安装,跑通后再按需测试替换为其它版本。
pip install --pre openvino==2025.4.0rc3 openvino-tokenizers==2025.4.0.0rc3 openvino-genai==2025.4.0.0rc3 --extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightly
步骤3:下载并准备 OpenVINO™ IR 模型(推荐“直接拿现成的”,想详细了解模型转换过程再自己转换)
把模型“跑起来”的关键,是你手里要有一份可用的 OpenVINO™ IR。这里你有两条路:
方案 A(推荐):直接下载社区已转换好的 IR —— 最快、最稳、最像“开箱即用”。
方案 B(可选):你自己从原始模型转换 IR —— 适合你要换权重版本、或想完全掌控转换细节。
-
方案 A(推荐):一键下载已转换 IR(最短路径)
pip install modelscopepython -c "from modelscope import snapshot_download; snapshot_download('zhaohb/PaddleOCR-Vl-OV')"
下载完成后,建议你把模型文件统一放到仓库下的 models/ 目录,命名固定下来,后面所有命令就都不用改路径:
paddleocr_vl_ov/└─models/└─ov_paddleocr_vl_model/ #最终推理就指向这个目录
-
方案 B(可选):从原始模型手动转换 IR(需要你有原始模型目录)
如果你要自己转换,有一个步骤非常关键:先把仓库提供的 modeling_paddleocr_vl.py 替换进原始模型目录(这一步本质是在对齐一个更适合转换/推理的模型实现)。
1)替换 modeling 文件
cp modeling_paddleocr_vl.py <你的原始模型目录>\modeling_paddleocr_vl.py
2)运行转换脚本生成 IR
python ov_model_convert.py \--pretrained_model_path ..\test\PaddleOCR-VL \--ov_model_path ..\test\ov_paddleocr_vl_model
步骤4:运行推理并验证输出一致性
很多“模型加速”文章会直接晒速度,但对开发者来说,更重要的是先确认两件事:
1)模型在 OpenVINO™ 上能稳定跑通;
2)输出和原始实现(PyTorch/Transformers)一致,至少在同一张图、同一任务下,结果不会“跑偏”。
仓库已经把这件事写成了现成脚本 torch_ov_test.py:它会在同一输入上分别跑 Transformers(PyTorch) 和 OpenVINO™,然后把结果打印出来,帮助你快速做 sanity check。
支持的任务类型包括:ocr / table / chart / formula。建议你先用仓库自带的 chart1.png 来复现。
-
(推荐)同时跑 PyTorch & OpenVINO™,做对齐验证
python torch_ov_test.py \--pretrained_model_path ..\test\PaddleOCR-VL \--ov_model_path ..\test\ov_paddleocr_vl_model \--image_path test_images\chart\chart1.png \--task chart \--ov_device GPU
其中,可选的task包括:
-
ocr - OCR 文字识别
-
table – 表格识别
-
chart – 图表识别
-
formula – 公式识别
-
(更快)只跑 OpenVINO™,跳过 PyTorch(用于确认“IR 推理没问题”)
如果你已经不关心 PyTorch 对齐,只想确认 IR 推理能跑、速度如何,可以直接跳过 Transformers:
python torch_ov_test.py \--ov_model_path ..\test\ov_paddleocr_vl_model \--image_path test_images\chart\chart1.png \--task chart \--skip_torch
步骤5:启动 Gradio Demo(把“开箱即用”真正做成可交互展示)
当你在命令行里确认推理跑通后,下一步就是把它变成一个“别人一眼就能懂”的 Demo:上传图片 → 选择任务 → 直接看到解析结果和可视化展示。仓库已经提供了现成的 Gradio 脚本,基本一条命令就能起服务。
-
一键启动 Gradio
python paddleocr_vl_grdio.py
在我的AI PC上运行效果如下:
到这里,你已经完成了 PaddleOCR-VL 在 Intel 平台上的 OpenVINO™ 部署闭环:环境一次配好 → IR 模型直接可用(或可自行转换)→ 推理跑通并完成 parity 验证 → 一键启动 Gradio 做可交互展示。这意味着 PaddleOCR-VL 不再只是“云端才能玩”的文档解析能力,而是可以更轻量、更可控地落到本地设备上,用同一套 OpenVINO™ 推理链路去支撑 OCR / Table / Chart / Formula 等任务。详细开源代码地址在这里:https://github.com/zhaohb/paddleocr_vl_ov
更重要的是,这篇文章并不追求“堆概念”,而是把社区已经沉淀好的脚手架变成一条可**的最短路径:你只需要按步骤执行命令、对照“你应该看到的输出”做校验,就能在自己的环境里稳定复现并交付一个可展示的 Demo。后续开发者们可以在此基础上继续深入:要么把 Gradio Demo 工程化成 API/服务,对接真实文档工作流;要么做更严格的 benchmark 与精度策略(量化/配置)验证,把这条链路从“能跑”进一步推到“好用、可上线”。