秒级克隆,“声”而不凡!使用 OpenVINO™ 玩转 Qwen3-TTS 语音合成
 openlab_96bf3613
更新于 1月前
openlab_96bf3613
更新于 1月前
作者:杨亦诚
引言
继语音识别(ASR)之后,阿里巴巴通义团队再次发力,推出了全新的 Qwen3-TTS 系列模型。这不仅是一个高质量的文本转语音工具,更是一个支持 10 种全球语言、具备“语音合成”与“情感适配”能力的声学引擎。
基于离散多码本 LM 架构,Qwen3-TTS 绕过了传统架构的性能瓶颈,实现了真正意义上的端到端语音建模。本文将带你深度体验如何利用 Intel® OpenVINO™ 工具套件,在 Intel 平台上赋予 Qwen3-TTS 极致的推理速度,让丝滑的语音合成触手可及。
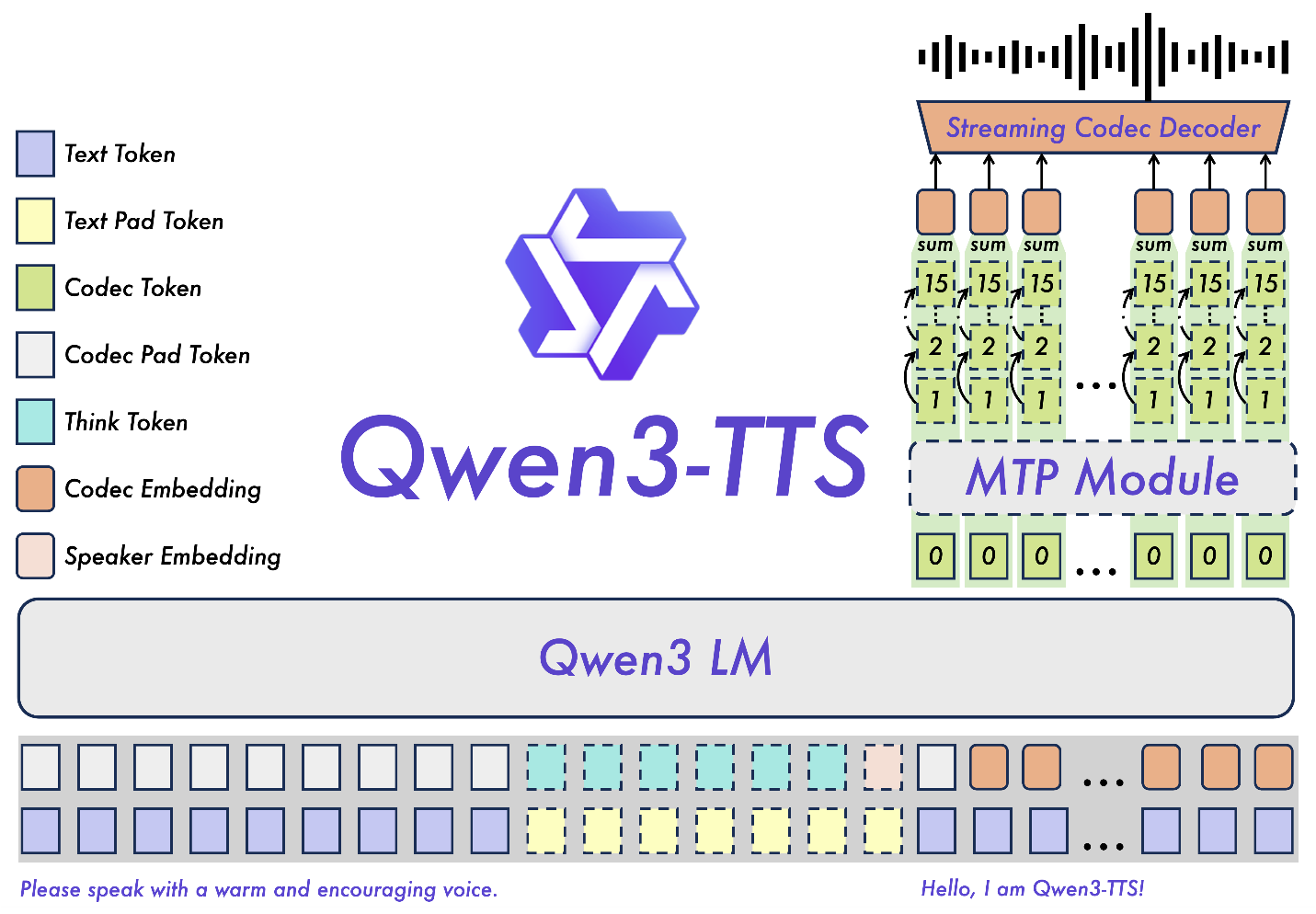
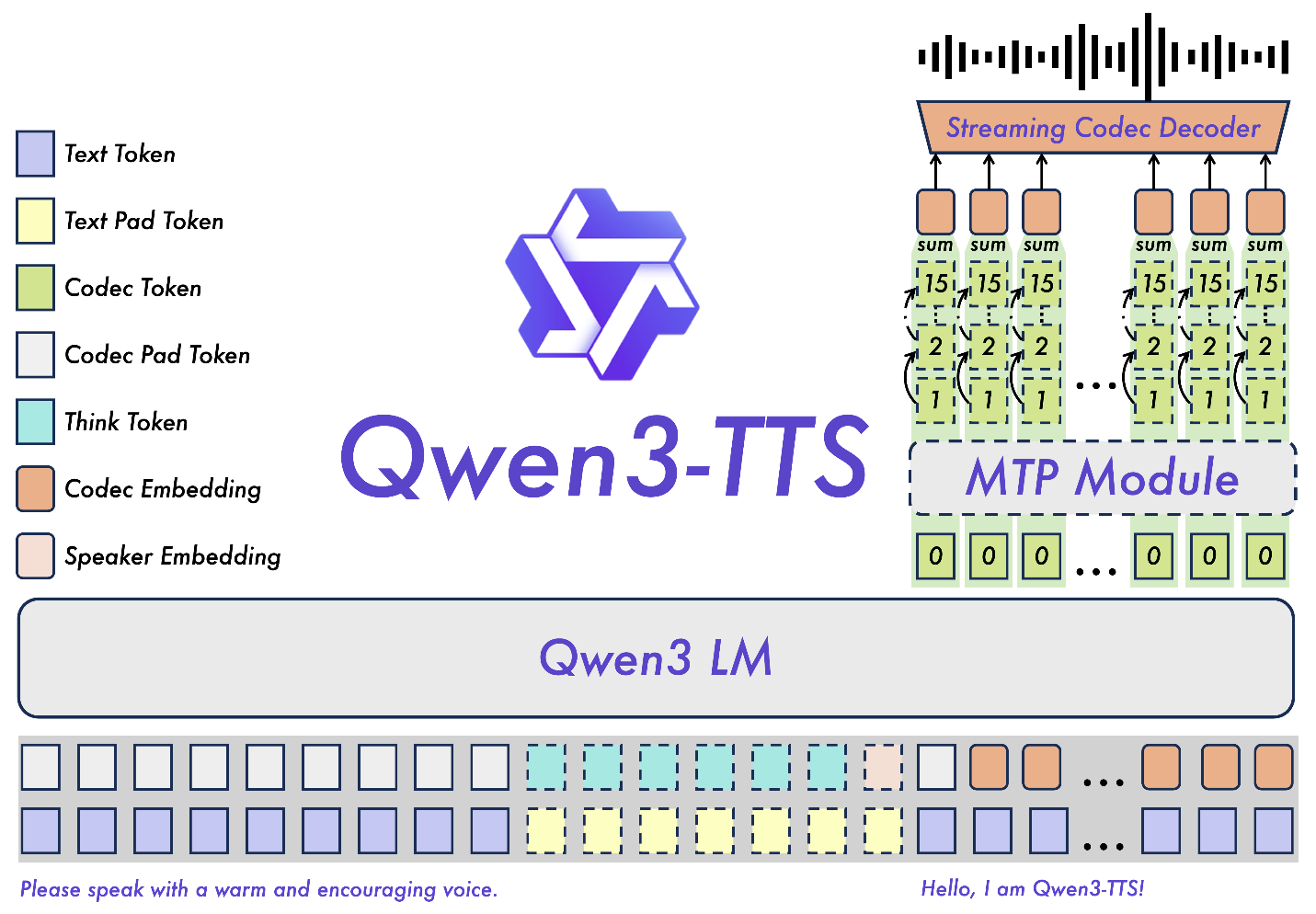
模型特性
多语言**:原生支持中、英、日、韩、德、法等 10 种主要语言。
语音合成:仅需极短的参考音频,即可复刻特定人物的音色。
极致稳健:强大的上下文理解能力,能根据语义自动调节语调、语速和情感表达,对噪性文本具有极高的容错率。
高效架构:采用轻量化非 DiT 架构,配合 Qwen3-TTS-Tokenizer-12Hz,实现高保真的语音重构。
第一步:环境准备
首先,我们需要构建支持 OpenVINO™ 加速的 Python 环境。请确保您的系统已安装 Python 3.9+。
# 1. 安装核心依赖(要求 OpenVINO >= 2025.4.0)pip install -q --extra-index-url https://download.pytorch.org/whl/cpu \"torch==2.8.0" "torchaudio==2.8.0" "openvino>=2025.4.0" \"nncf" "gradio>=4.0" "huggingface_hub" "scipy" "qwen-tts"# 2. 获取 OpenVINO 适配辅助脚本(参考 Notebook 逻辑)# 建议从 OpenVINO Notebooks 官方仓库获取 qwen_3_tts_helper.py
第二步:模型下载与转换
为了在 Intel 硬件上实现最佳性能,我们需要将原始的 PyTorch 模型转换为 OpenVINO™ 的 IR 静态图格式。转换过程会处理音频编码、语义建模等多个核心组件。
from pathlib import Pathfrom qwen_3_tts_helper import convert_qwen3_tt***odel# 1. 定义模型 ID 和输出路径model_id = "Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice"model_name = model_id.split("/")[-1]ov_model_dir = Path(f"{model_name}-OV")# 2. 执行一键转换# 转换脚本会处理 Tokenizer 与推理网络print(f" 开始转换 Qwen3-TTS 模型到 OpenVINO IR 格式...")convert_qwen3_tt***odel(model_id=model_id,output_dir=ov_model_dir,quantization_config=None, # 可选:设置 NNCF 配置进行 INT8 量化)print(f" 模型已成功保存至: {ov_model_dir}")
这里你也可以将model_id通过以下方式替换成原始模型的本地路径进行转换:
convert_qwen3_tt***odel(
model_id=local_model_dir,
output_dir=ov_model_dir,
quantization_config=None, # 可选:设置 NNCF 配置进行 INT8 量化
use_local_dir=False
)
原始模型建议从魔搭社区下载获取:https://modelscope.cn/collections/Qwen/Qwen3-TTS
现在,我们已经将 Qwen3-TTS 模型转换为 OpenVINO™ 中间表示(IR)格式。转换过程将导出以下组件:
Talker Embedding Model (openvino_talker_embedding.xml):编解码器标记(Codec token)嵌入层。
Talker Text Embedding Model(openvino_talker_text_embedding.xml):文本标记(Text token)嵌入层。
Talker Text Projection Model (openvino_talker_text_projection.xml):用于投影文本嵌入。
Talker Language Model(openvino_talker_language_model.xml):支持 KV-cache 的主解码器。
Code Predictor Embedding Model(openvino_talker_code_predictor_embedding.xml):代码预测器嵌入层。
Code Predictor Model(openvino_talker_code_predictor.xml):用于预测额外的语音代码。
Speaker Encoder(openvino_speaker_encoder.xml):用于提取说话人嵌入。
第三步:模型部署与推理
在模型部署阶段,我们使用 OVQwen3TTSModel 来加载优化后的 IR 文件。该接口完美兼容原始 API,让你可以轻松实现语音合成。
1. 基础推理示例
import soundfile as sffrom qwen_3_tts_helper import OVQwen3TTSModel# 加载模型到指定硬件ov_model = OVQwen3TTSModel.from_pretrained("/home2/ethan/intel/qwen3-tts/Qwen3-TTS-12Hz-1.7B-CustomVoice-OV",device="GPU",)# 执行推理wavs, sr = ov_model.generate_custom_voice(text="其实我真的有发现,我是一个特别善于观察别人情绪的人。",language="Chinese", # Pass `Auto` (or omit) for auto language adaptive; if the target language is known, set it explicitly.speaker="Vivian",instruct="用特别愤怒的语气说", # Omit if not needed.)# 保存结果sf.write("output_custom_voice_ov.wav", wavs[0], sr)
2. 搭建交互式 Demo
借助 OpenVINO™ Notebooks 提供的辅助工具,几行代码即可启动一个支持语音合成功能的 Web 界面。
from gradio_helper import make_demo# 创建并启动 Gradio 演示界面demo = make_demo(ov_model, model_type=ov_model.tt***odel_type)demo.launch()
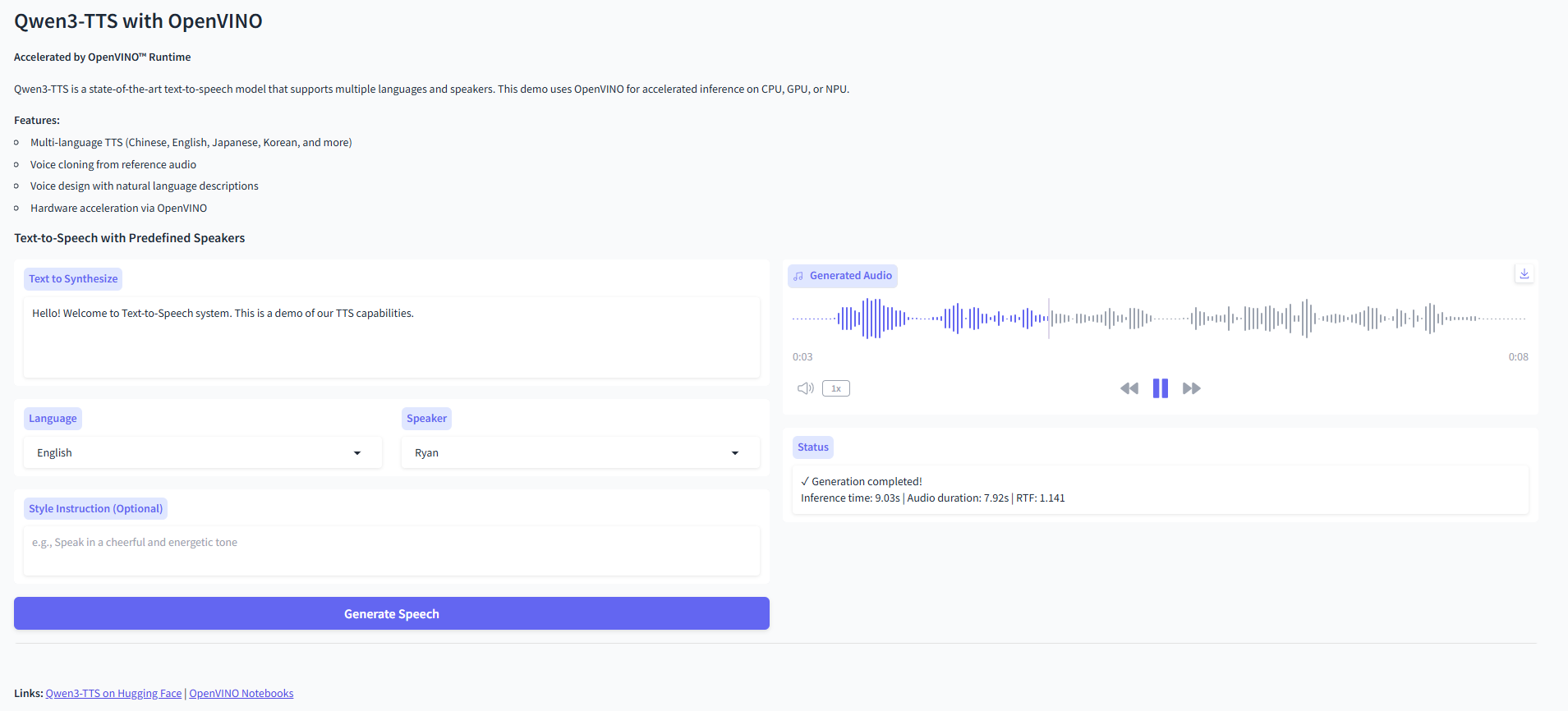
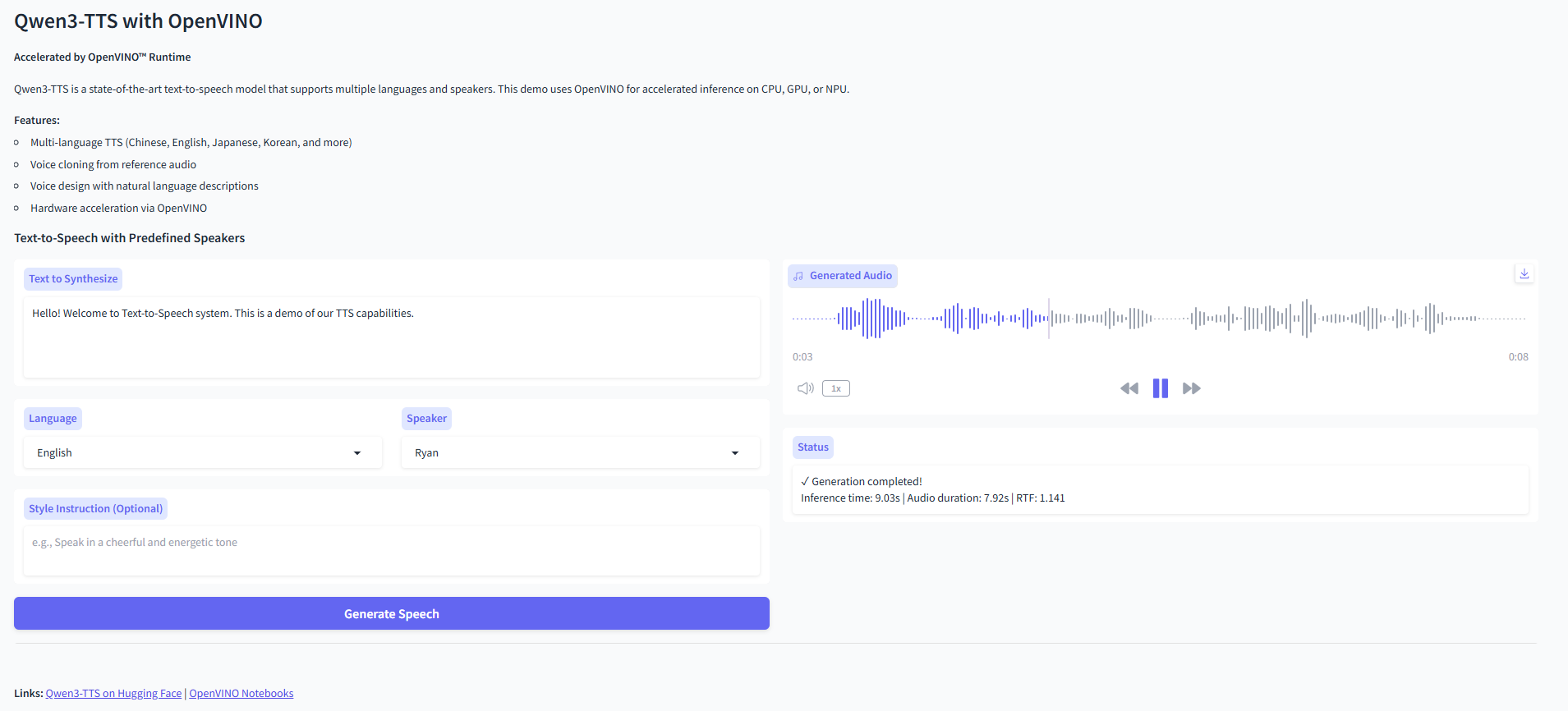
总结
通过 OpenVINO™ 的赋能,Qwen3-TTS 在 Intel CPU 和集成显卡上展现出了令人惊叹的生成效率。从文本到高保真语音的转换不再需要昂贵的 GPU 资源,在边缘侧设备上也能实现自然、流畅的语音交互。
无论你是想打造智能客服、有声书,还是极具个性的 AI 助手,Qwen3-TTS + OpenVINO™ 都是你目前最值得尝试的技术组合!
参考来源:
Qwen3-TTS 官方仓库: https://github.com/QwenLM/Qwen3-TTS
Qwen3-TTS OpenVINO Notebooks 完整部署示例: https://github.com/openvino-dev-samples/openvino_notebook***lob/63132a061d24e1817eff9b282beb72f84cfaf289/notebooks/qwen3-tts/qwen3-tts.ipynb
OpenVINO 小助手微信 : OpenVINO-China
如需咨询或交流相关信息,欢迎添加OpenVINO小助手微信,加入专属社群,与技术专家实时沟通互动。