OpenVINO™ 开发者说:Intel NPU 为什么可以跑大语言模型?
 openlab_96bf3613
更新于 8小时前
openlab_96bf3613
更新于 8小时前
【开篇寄语】本文为 OpenVINO™ 社区开发者的实践分享。作者从技术原理、工程实现、生态演进角度,深度拆解了 Intel NPU 运行大语言模型的核心逻辑,其中关于编程模型、算子生态等讨论也为我们理解 NPU 当前架构与演进方向提供参考价值。作为开源 AI 工具套件,OpenVINO™ 鼓励大家结合自身场景验证、交流、分享,共同推动技术实践进步。
【作者简介】陶文,开源投屏软件“屏易连”作者,专注端侧大模型推理与投屏技术的结合应用。
第一部分:问题
KV Cache 是什么,为什么需要它
LLM 生成文本时是逐 token 产出的。用户问 "什么是NPU",模型不是一次性蹦出完整答案,而是先输出"NPU",再输出"是",再输出"一种"……每一步都要重新做 attention 计算。
Attention 的核心操作是:当前 token 去"查看"前面所有 token 的信息,决定该关注谁。具体来说,模型会把每个 token 的向量分别乘以三个不同的权重矩阵,得到三组投影向量:
-
Q (Query)、K (Key)、V (Value) —— 这三个名字只是代号。Q/K/V 的具体数值由训练决定,没有人类可解释的语义。重要的不是它们"代表什么意思",而是它们在计算中扮演的角色。
Attention 的计算过程是:用当前 token 的 Q 和所有历史 token 的 K 做点积(Q×K^T,得到 token 之间的相关度矩阵),经过 softmax 归一化为权重,再用这些权重对所有 V 做加权求和,得到输出。
问题来了:生成第 100 个 token 时,前 99 个 token 的 K 和 V 和上一步完全一样——它们是只由各自的输入决定的,不会因为新 token 的到来而改变。如果每次都重新算 99 个 token 的 K 和 V,就是纯粹的浪费。
KV Cache 就是这个问题的解决方案:把已经算过的 K 和 V 缓存起来,下次直接用。生成第 100 个 token 时,只需要计算第 100 个 token 的 Q、K、V,然后把新的 K、V 追加到缓存里,用缓存里全部 100 个 K、V 做一次 attention。
这就引出了 LLM 推理的两个阶段:
Prefill(预填充): 处理用户输入的整个 prompt。比如 "什么是NPU" 被分词为 4 个 token,模型一次性计算这 4 个 token 的 Q、K、V,做一次完整的 attention,得到第一个输出 token。同时,这 4 个 token 的 K 和 V 被存入 KV cache。这一步是计算密集型的——所有 token 同时参与计算。
Decode(解码/生成): 逐 token 生成回答。每一步只有 1 个新 token,计算它的 Q、K、V,把新的 K、V 追加到 cache,然后用这 1 个 Q 去查整个 cache。这一步是内存带宽密集型的——计算量不大,但每次都要读取整个 KV cache。
为什么 KV Cache 在 NPU 上是个难题
KV cache 有一个天然的动态特性:每生成一个 token,cache 就增长一行。生成到第 10 个 token 时 cache 有 14 行(4 个 prompt + 10 个生成),到第 100 个 token 时有 104 行。大小一直在变。
GPU 和 CPU 处理这种动态性很自然——运行时动态分配内存就行。GPU 上的 vLLM 甚至发明了 PagedAttention,像操作系统管理内存页一样按需分配 KV cache 空间。
NPU 不行。 原因在于 NPU 的执行模型和 GPU 有本质区别。
NPU 的工作方式更像是"执行一个预编译的程序",而不是"动态调度指令"。NPU 编译器在编译阶段就要确定:
-
每个 tensor 的精确 shape 和内存地址
-
每次 DMA 搬运的源地址、目标地址、数据量
-
DPU 和 SHAVE 每个任务的执行参数
-
所有任务之间的 barrier 同步关系
这些信息被打包成一个叫 blob 的二进制文件,提交给 NPU 固件执行。blob 的格式是标准的 ELF(和 Linux 可执行文件同一种格式),里面包含权重数据、DPU 任务描述、DMA 搬运指令、SHAVE kernel 的机器码、barrier 配置等多个 section。blob 里几乎所有的地址和大小都是在编译时固定下来的——运行时 NPU 不能临时改变 tensor 的 shape 或重新分配内存。唯一的例外是输入/输出 tensor 的地址:它们在 blob 中是占位符,驱动加载时通过 ELF 重定位把占位符替换为实际的设备内存地址。
所以,一个 [batch, heads, seq_len, head_dim] 的 KV cache tensor,其中 seq_len 不能是"随着生成逐渐增长的变量"——它必须在编译时就确定为一个具体的数字。
这就是核心矛盾:KV cache 天然是动态的,但 NPU 只能执行静态 shape 的计算图。
解决方案:预分配 + Attention Mask
思路其实很直接:既然 NPU 需要固定大小,那就预分配一个足够大的缓冲区,把"动态增长"变成"在固定空间内移动写入位置"。
具体做法是在编译时设定 KV cache 的最大容量。NPUW(NPU 的运行时包装层,后面会详细介绍)使用两个参数:
-
MAX_PROMPT_LEN:prefill 能处理的最大 prompt 长度(默认 1024 个 token) -
MIN_RESPONSE_LEN:预留给生成阶段的 token 数(默认 128)
KV cache 的总容量 = 1024 + 128 = 1152。编译时,KV cache tensor 的 seq_len 维度就固定为 1152。
但是,生成第 1 个 token 时,cache 里只有 4 行有效数据(prompt 的 4 个 token),后面 1148 行全是空的。怎么让模型知道哪些位置是有效数据、哪些是填充?
答案是 attention mask——一个和序列长度等长的 0/1 向量。1 表示"这个位置有有效数据,attention 应该看它",0 表示"这个位置是空的,忽略它"。
以 "什么是NPU" 为例,prompt 4 个 token,KV cache 容量 1152:
生成第 1 个 token 时:
KV cache: [K₁ K₂ K₃ K₄ 0 0 ... 0 ] (4 个有效 + 1148 个空)
attention_mask: [1 1 1 1 0 0 ... 0]
生成第 2 个 token 时:
KV cache: [K₁ K₂ K₃ K₄ K₅ 0 ... 0 ] (5 个有效 + 1147 个空)
attention_mask: [1 1 1 1 1 0 ... 0]
生成第 100 个 token 时:
KV cache: [K₁ K₂ K₃ K₄ K₅ ... K₁₀₃ 0 ... 0] (103 个有效 + 1049 个空)
attention_mask: [1 1 1 1 1 ... 1 0 ... 0]

Softmax 在计算 attention 分数时,会把 mask=0 的位置设为负无穷大,这样经过 softmax 后这些位置的权重就变成 0,相当于完全忽略。
KV cache 的物理大小从未改变(始终是 1152),变化的只是"有效数据的边界"和 attention mask 中 1 的个数。 这样,NPU 每次执行的 blob 完全相同,只是输入数据不同。
第二部分:软件栈怎么管理 KV Cache
三层软件栈的分工
在深入细节之前,先搞清楚三个代码仓库各自负责什么。
openvino.genai(最上层)是面向用户的应用框架。它的 StatefulLLMPipeline 负责分词、采样策略(贪心/top-k/top-p)、聊天历史管理。它决定什么时候做 prefill、什么时候做 decode、什么时候对话历史太长需要截断。对用户来说,这是唯一直接打交道的层。
openvino(中间层)是推理引擎。其中的 NPUW(NPU Wrapper,NPU 包装器)是 LLM 推理在 NPU 上的核心调度器。NPUW 做的事包括:
-
把一个动态 shape 的 LLM 模型拆成 prefill 和 generate 两个静态 shape 的子模型
-
分别编译成 NPU blob
-
管理 KV cache 缓冲区——分配、清零、在 prefill 和 generate 之间搬运
-
处理 chunked prefill(prompt 太长时分块处理)
-
通过 Level Zero(Intel 的底层硬件接口 API,类似 Vulkan 之于 GPU)向 NPU 提交推理任务
npu_compiler(最底层)是编译器。它把 OpenVINO IR(模型的中间表示)编译成 NPU blob。编译器不知道什么是 "KV cache"——它看到的只是一些标记为"有状态"的 tensor。编译器把它们转换成 blob 的普通输入/输出,让 NPUW 来管理持久化。
一句话总结:genai 决定何时推理,NPUW 决定怎么推理,compiler 决定 NPU 硬件执行什么。
NPU 里的两套执行单元:DPU 和 SHAVE
第一部分提到 blob 里有 DPU 任务和 SHAVE 任务。在继续讲 KV cache 的软件管理之前,先建立对这两套硬件的基本认知——后面的内容会反复提到它们。
DPU(Data Processing Unit,数据处理单元) 是固定功能硬件。它只做几件事:卷积、池化、矩阵乘法(以及 element-wise 的加法/乘法)。能做的操作是芯片出厂时就决定好的,没有可编程性,但速度极快。LLM 中最耗时的操作——Q×K^T 和 Score×V 两个矩阵乘法、QKV 投影、FFN 的两层全连接——全部由 DPU 执行。DPU 还有一个附属的 PPE(Post-Processing Engine),可以在矩阵乘法之后紧接着做缩放(乘常数)和加偏置,不需要额外的任务。
SHAVE(Streaming Hybrid Architecture Vector Engine) 是一颗可编程的 DSP 处理器。它有自己的指令集(基于 SPARC 架构改造的 VLIW 向量指令集)、自己的 ELF 可执行文件,能执行任意的数值计算逻辑。DPU 做不了的操作全部交给 SHAVE——激活函数(ReLU、GELU、SiLU)、归一化(Softmax、RMSNorm)、旋转位置编码(RoPE)、注意力机制(SDPA、Flash SDPA)、量化/反量化(dynamic_dequantize)等等。npu_compiler 仓库里预编译了 719 个 SHAVE kernel ELF 文件,覆盖 195 个算子家族。


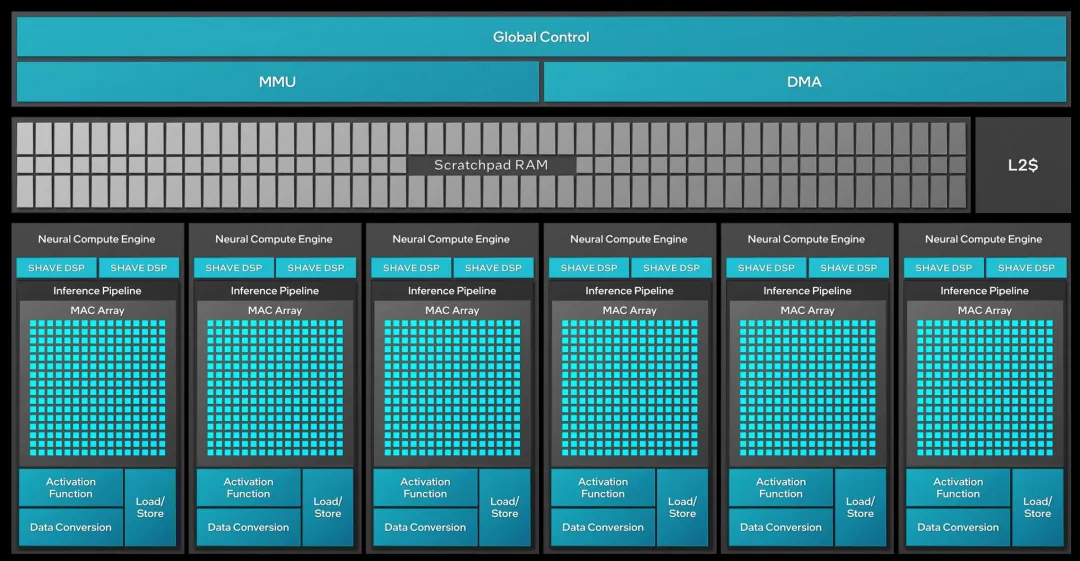
分工原则:编译器逐层判断每个操作交给谁。优先给 DPU——如果满足硬件约束(对齐要求、数据类型、tensor shape 限制)就直接走 DPU。DPU 做不了的,看 DMA 能不能处理(有些操作本质上只是数据搬运和重排)。都不行的,交给 SHAVE。DPU 是专才,SHAVE 是通才。
对 KV cache 来说,理解 DPU/SHAVE 分工很重要:attention 计算中的矩阵乘法走 DPU,softmax 和 mask 处理走 SHAVE(或在优化路径中融合进 SHAVE 的 attention kernel)。GPTQ 量化场景中,权重的矩阵乘法走 DPU,但权重表的准备工作(PopulateWeightTable)走 SHAVE——SHAVE 做的是控制面(准备地址和格式),DPU 做数据面(实际的乘加计算)。
NPUW 的核心设计:两个模型,一份 KV Cache
NPU 上的 LLM 推理不是一个模型跑到底——NPUW 把同一个模型拆成两个静态 shape 的版本:
Prefill 模型:input_ids 的 seq_len = 1024(处理整个 prompt),KV cache 输出 shape 是 [batch, heads, 1024, head_dim]。
Generate 模型:input_ids 的 seq_len = 1(每次只处理 1 个新 token),KV cache 的输入和输出 shape 是 [batch, heads, 1152, head_dim]。
为什么不能用一个模型?因为两个阶段的 input_ids shape 不同——prefill 时 seq_len 可能是几百上千,decode 时 seq_len 固定为 1。NPU 的 blob 里每个 tensor 的 shape 是固定的,不能一个 blob 既接受 seq_len=1024 又接受 seq_len=1。
两个模型分别编译成独立的 blob,推理时的流程是:
-
用户输入 prompt
-
调用 prefill blob 处理整个 prompt → 输出第一个 token + KV cache
-
把 prefill 的 KV cache 拷贝到 generate 模型的输入缓冲区(
copy_kvcache()) -
循环调用 generate blob,每次输入 1 个 token → 输出下一个 token + 更新后的 KV cache
-
直到遇到结束符或达到最大长度
第 3 步值得细说。Prefill 模型的输出里有一组叫 present.0.key、present.0.value ... 的 tensor,包含了刚计算出的所有 K 和 V。Generate 模型的输入里有对应的 past_key_values.0.key、past_key_values.0.value ...。copy_kvcache() 把 present 拷贝到 past——但两个模型的 KV cache shape 不一样(prefill 是 1024,generate 是 1152),所以它用 tensor 切片:从 prefill 的 present 里取出有效部分(比如实际 prompt 长度是 4,就取 [0:4]),写入 generate 的 past 的 [0:4] 位置。这个拷贝对 32 层 × 2(K 和 V)= 64 个 tensor 并行执行(ov::parallel_for)。
第 4 步的 KV cache 更新也不是整体拷贝。update_kvcache_for() 函数只**新增的那一行:把 generate 输出的 present(只有新 token 的 K、V)写入 past 的下一个空位。一个计数器 num_stored_tokens 记录当前已经存了多少行,每次写入后加 1。
应对现实:Generate 变体和 Chunked Prefill
上面的设计能跑,但遇到真实场景会碰到两个问题:prompt 很短时算力浪费,prompt 很长时放不进模型。NPUW 用两个机制分别应对。
Generate 变体:避免浪费算力
只用一个 generate 模型有个问题:如果编译时 KV cache 容量是 1152,但用户只输入了 20 个 token,那每次 decode 时 NPU 都要处理一个 seq_len=1152 的 KV cache——其中 1130 多个位置都是填充的零。虽然 attention mask 会让模型忽略这些位置,但 DMA 搬运和部分计算仍然要遍历完整的 1152 长度,这是实实在在的浪费。
NPUW 的解决方案:编译多个 generate 变体,每个变体有不同的 KV cache 容量,比如 256、512、1024、1152。推理开始时,select_generate_request() 根据 prompt 长度选择最小的够用的变体:
prompt 长度 20 + 预留 128 = 需要 148 → 选择 256 的变体
prompt 长度 400 + 预留 128 = 需要 528 → 选择 1024 的变体
prompt 长度 1000 + 预留 128 = 需要 1128 → 选择 1152 的变体
一个巧妙的优化是:所有变体共享同一块内存缓冲区。 最大变体(1152)分配一整块内存,较小变体只是指向这块内存前面的一段切片。4 个变体不需要 4 倍内存,只需要 1 倍。
代价是编译时间——每个变体都要单独编译一个 blob,NPU 编译本身就慢(几十秒),多个变体意味着更长的冷启动。好在编译结果可以通过 EXPORT_BLOB 缓存到磁盘,下次启动直接加载。
Chunked Prefill:当 Prompt 太长
如果用户输入超过 MAX_PROMPT_LEN(1024)个 token 怎么办?prefill 模型的 input_ids shape 是固定的 1024,塞不下更长的 prompt。
NPUW 的做法是分块处理:
用户输入 2048 个 token,MAX_PROMPT_LEN = 1024
第一轮 prefill:处理 token[0:1024]
→ 输出 KV cache 包含前 1024 个 token 的 K、V
→ update_kvcache_for(): 把 present 写回 past
第二轮 prefill:处理 token[1024:2048]
→ 输入中包含第一轮积累的 KV cache(past)
→ 输出 KV cache 包含全部 2048 个 token 的 K、V
→ update_kvcache_for(): 更新 past
切换到 generate 模型:
copy_kvcache(prefill → generate)
开始逐 token 生成
每一轮 prefill 结束后,present 输出被追加到 past 输入,积累已处理的 KV 状态。所有 chunk 处理完毕后,完整的 KV cache 被拷贝到 generate 模型。
编译器:有状态模型变成无状态函数
在 OpenVINO 的模型表示(IR)中,KV cache 用一对特殊操作表示:
-
ReadValue("kv_k_layer0")— 从一个叫kv_k_layer0的"变量"中读取值(上一次推理保存的 K cache) -
Assign("kv_k_layer0", new_value)— 把新的 K cache 写回这个"变量"
这是 OpenVINO 处理有状态模型的通用机制——不只是 KV cache,任何需要在多次推理之间持久化的数据都用这对操作。
但 NPU 编译器生成的 blob 是一个纯粹的"输入 → 输出"函数,没有"变量"这个概念。所以编译器有一个专门的 pass(ConvertAssignReadValueToReturnsAndInputs),把有状态操作拆解为无状态的函数签名:
转换前(有状态):
func @main(%input_ids) {
%past_k = ReadValue("kv_k_0") // 从"变量"读
%new_k = compute(...)
Assign("kv_k_0", %new_k) // 写回"变量"
return %logits
}
转换后(无状态):
func @main(%input_ids, %read_kv_k_0) -> (%logits, %assign_kv_k_0) {
// ReadValue 变成了一个普通的函数输入参数
// Assign 变成了一个普通的函数输出值
%new_k = compute(...)
return %logits, %new_k
}
转换后的 blob 只是一个纯函数:KV cache 从输入进来,更新后的 KV cache 从输出出去。"记住上一次的状态"这件事完全交给 NPUW 来做——它在 Level Zero 内存中维护 KV cache 缓冲区,每次推理前把 past 缓冲区绑定为 blob 输入,推理后把 blob 输出(present)写回 past 缓冲区,准备下一次调用。
具体来说,ZeroVariableState 类管理这些缓冲区。它做的事很简单:
-
持有一块 Level Zero 内存(NPU 可访问的设备内存)
-
set_state(): 更新缓冲区内容 -
get_state(): 读取当前内容 -
reset():memset(0)清零——新对话开始时调用
编译器不关心 KV cache 的语义,NPUW 不关心 blob 内部的计算逻辑,各管各的。
第三部分:NPU 硬件怎么执行
NPU 的内存架构:DDR 和 CMX
要理解 KV cache 在硬件层面的处理,先要理解 NPU 的内存架构,因为 KV cache 的存放位置直接决定了性能。
NPU 有两层存储:
DDR(系统内存): 就是你笔记本的内存条。容量大(几 GB 到几十 GB),但访问慢。模型权重、KV cache、输入/输出 tensor 都存在这里。NPU 通过 64 位虚拟地址访问 DDR。
CMX(Connection Matrix): NPU 芯片内部的高速 SRAM。每个 NPU tile(计算单元)有自己的 CMX,容量很小(几百 KB 到几 MB 级别),但访问极快。DPU 和 SHAVE 做计算时,数据必须先搬到 CMX 里。
数据在 DDR 和 CMX 之间的搬运靠 DMA 引擎。编译器在编译阶段就规划好了所有 DMA 搬运:什么时候把权重从 DDR 搬到 CMX、什么时候把计算结果从 CMX 写回 DDR。DMA 搬运和 DPU/SHAVE 计算可以通过 barrier 同步实现流水并行——DMA 搬下一块数据的同时,DPU 在处理上一块。
对于 KV cache 来说,它太大了(几百 MB),不可能整个放进 CMX。编译器会把 KV cache 分 tile 处理:每次只把当前需要的一小块 KV 数据从 DDR 搬到 CMX,attention 计算完后把结果写回,再搬下一块。这就是为什么 Flash SDPA 要做 tiling——不只是为了数值稳定性,也是因为 CMX 放不下完整的 attention 矩阵。
32 层 Transformer 怎么跑:一个 blob,一次提交,没有循环
一个 7B 参数的 LLM 有 32 个 Transformer 层,每层包含 attention + FFN,权重总共约 3-4 GB(INT4 量化后)。NPU 的 CMX 只有几 MB——连一层的权重都放不下,更不用说 32 层了。
所以 NPU 是逐层执行的:一层的权重从 DDR 搬进 CMX,计算完,结果写回 DDR,再搬下一层。 这和 GPU 不同——GPU 通常把所有权重一次性加载到显存,然后直接访问。NPU 没有足够大的本地存储来这么做。
一个自然的问题是:这个"逐层"是 host 端的 for 循环在驱动吗?不是。没有任何循环。
编译器把整个 32 层 Transformer 展开(unroll)成一个扁平的任务列表,写进同一个 blob。这个列表可能有几千条任务(DMA + DPU + SHAVE),按依赖关系排好序。每一层的操作(QKV 投影、attention、FFN 等)在任务列表中是连续的,但层与层之间没有明确的分界线。
任务描述符和权重一样,在 blob 加载时就已经写入了 NPU 可访问的 DDR 内存。Host 提交的只是一个很小的命令——本质上就是一个指针,指向 DDR 中的 MappedInference 结构(任务列表的"总目录")。不存在"指令队列放不下"的问题,因为任务描述符就在 DDR 里,有几个 GB 的空间,放几千条描述符绰绰有余。
那谁来逐条读取并执行这些任务?NPU 芯片内部有自己的嵌入式处理器。 这不是 x86 CPU——NPU 是一颗独立的芯片,里面除了 DPU 和 SHAVE,还有专门的管理核:
-
37xx(Meteor Lake):两颗 Leon 处理器(32 位 SPARC 内核)。LeonRT 负责和 host 通信,LeonNN 负责神经网络推理调度——读取任务列表、管理 barrier、派发 DMA/DPU/SHAVE 任务。
linux-npu-driver/firmware/include/api/vpu_nnrt_api_37xx.h中有直接的注释提到LeonRT/LeonNN,以及 "same sizeof() on x86 compilation and Sparc compilation"。 -
40xx(Lunar Lake):管理核换成了 RISC-V。
vpu_j**_job_cmd_api.h中提到 "RISC-V facilitates cache-bypas****emory access"。
完整的硬件图景:
x86 CPU (host)
│
│ DRM ioctl / Level Zero
│
NPU 芯片
├── Leon / RISC-V ── 管理核:接收 host 命令,读取任务列表,调度执行
├── DMA 引擎 ── DDR ↔ CMX 数据搬运
├── DPU ── 矩阵乘法、卷积
├── SHAVE ── softmax、RoPE、激活函数等
└── CMX ── 片上高速 SRAM
Host 的 x86 CPU 只负责提交命令和等待完成。一旦命令提交到 NPU,所有的任务调度都在 NPU 芯片内部完成——x86 CPU 完全不参与中间过程。这也是 NPU 能做到低功耗的原因之一:推理期间 x86 CPU 可以闲着甚至降频。
关键的性能优化是 DMA/计算重叠(也叫 prefetching 或 double buffering):
时间 →
DMA: [搬第1层权重] [搬第1层KV] [搬第2层权重] [搬第2层KV] [搬第3层权重]...
DPU: [第1层MatMul] [第2层MatMul]
SHAVE: [第1层Softmax] [第2层Softmax]
↑ ↑
barrier barrier
当 DPU 在做第 1 层的矩阵乘法时,DMA 已经在搬第 2 层的权重了。当 SHAVE 在做第 1 层的 softmax 时,DPU 可能已经开始第 2 层的计算。三条流水线通过 barrier 同步——管理核检查 barrier 的 producer/consumer 计数,一个任务等到它依赖的所有前置任务完成后才被派发执行。
这个调度是编译器在编译时就规划好的。**FeasibleMemoryScheduler** 是核心的调度器,它做的事情包括:
-
CMX 容量管理:用线性扫描算法追踪 CMX 的使用情况,确保同一时刻加载的数据不超过 CMX 容量
-
Prefetch 提前量:控制 DMA 提前几步开始搬运后续任务的数据(
prefetchingLevelLimit) -
动态溢出(Spilling):如果 CMX 满了,把不急用的数据暂时写回 DDR,腾出空间
-
Ping-Pong 缓冲:两块 CMX buffer 交替使用——一块供计算读,另一块让 DMA 写新数据
所以,虽然 NPU 没有 GPU 那样的大容量本地显存,但通过精心的编译时调度,它可以让 DMA 搬运和计算高度重叠,从而隐藏大部分数据搬运延迟。运行时管理核只是按编译器规划好的顺序执行,不需要做任何调度决策。
Attention 在 NPU 上的完整实现
KV cache 最终被 attention 算子消费。NPU 编译器提供了三种实现路径,按硬件能力和场景选择。
分解路径(Decompose SDPA)
如果目标硬件不支持专用 attention 算子,编译器把 SDPA 分解为独立的操作序列:
Q × K^T → DPU(NCE MatMul)
× scale → DPU(PPE,后处理引擎,融合在上一步 MatMul 里)
+ attention_mask → DPU(NCE Eltwise)或 SHAVE
Softmax → SHAVE(没有对应的 DPU 硬件单元)
× V → DPU(NCE MatMul)
这里有一个细节:DPU 的后处理引擎(PPE)可以在矩阵乘法后直接做缩放(乘常数)和加偏置(加逐 channel 常数),但它不能加一个完整的 2D 空间 mask——因为 attention mask 的形状是 [seq_len, seq_len],不是简单的逐 channel 常数。所以 mask 加法需要作为一个独立的 Eltwise Add 任务,由 DPU(如果 tensor shape 满足对齐要求)或 SHAVE 执行。
分解路径的中间结果需要在 CMX 和 DDR 之间搬运。如果 Vertical Fusion 生效(见后面"Tiling"一节),部分中间结果可以留在 CMX 中直接传给下一步。
Flash SDPA 路径
对于较新的硬件,编译器把整个 attention 作为一个 SHAVE kernel 执行。Mask 处理被融合进 kernel 内部——FlashSDPAOp 直接把 attentionMask 作为输入参数,在 tiled attention 循环中完成 mask 加法,不需要额外的任务或中间 tensor。
KV cache 可能很长(上千个 token),如果一次性计算完整的 attention 分数,中间结果(Q×K^T 矩阵)大到放不进 CMX。Flash SDPA 的做法是把 KV cache 沿 seq_len 维度切成多个 tile,每个 tile 独立计算局部 attention,然后用数学方**确合并。
合并需要维护三个"滚动状态":running_output(当前最优输出)、running_max(当前最大 attention 分数,用于数值稳定)、running_sum(归一化分母)。为什么需要 running_max?因为 softmax 涉及指数运算,直接对很大的数取指数会溢出。每处理一个新 tile,如果发现更大的分数,就用新的最大值重新校正之前所有 tile 的结果。编译器的 UnrollFlashSDPA pass 负责把一个 FlashSDPA 操作展开成多个 tile 的链式调用,tile 之间传递这三个状态。
增量 SDPA(incremental_sdpa)
Decode 阶段的专用优化。当 query 只有 1 个 token 时,Q × K^T 从矩阵乘法退化为向量和矩阵的乘法,计算特征完全不同——计算量很小但要读取整个 KV cache。incremental_sdpa 是为这种 "1 query × N keys" 场景专门优化的 SHAVE kernel,mask 同样在内部处理。
从 SHAVE kernel 库的 git 历史能看到演进轨迹:先有通用的 sdpa,然后为 decode 场景加入 incremental_sdpa,最后为 prefill 长序列加入 flash_sdpa。三个 kernel 对应三种不同场景。
Position IDs 和 RoPE:模型怎么知道 token 的顺序
Attention 本身是一个"**操作"——它只看 Q 和 K 的点积,不关心 token 的先后顺序。但语言显然是有顺序的——"狗咬人"和"人咬狗"的含义完全不同。
Position IDs 是告诉模型"这个 token 在第几个位置"的输入。Prefill 阶段,如果 prompt 有 4 个 token,position_ids 就是 [0, 1, 2, 3]。Decode 阶段,每次生成一个新 token,position_ids 就是 [4]、[5]、[6]...
模型用 RoPE(Rotary Positional Embedding,旋转位置编码) 把位置信息编码进 Q 和 K 向量。具体做法是:根据 position_id 计算出一组 cos 和 sin 值,然后对 Q 和 K 向量做旋转变换。这样,两个 token 的 attention 分数会自然地受到它们之间距离的影响。
在 NPU 上,RoPE 是一个专门的 SHAVE kernel(rope.3720xx.elf / rope_ilv.3720xx.elf)。编译器通过 fuse_rope pass 识别模型中的 Sin/Cos/Multiply 模式,把它们融合成一个高效的 RoPEOp。注意 RoPE 操作的输入不是 position_ids 本身,而是预计算好的 cos/sin tensor——position_ids 到 cos/sin 的转换在模型的更上层完成。
Position IDs 在 NPU 上也面临静态 shape 的问题。Generate 模型的 position_ids tensor shape 是固定的(和 input_ids 一样),但每次只需要填一个值。NPUW 的处理方式是右对齐——把实际的 position 值放在 tensor 的最右边,左边用 0 填充。pad_position_ids() 函数负责这个工作。
position_ids 的值怎么算?很简单:数 attention_mask 里有多少个 1。如果 mask 是 [1,1,1,1,1,0,...,0](5 个 1),那下一个 token 的 position_id 就是 4(从 0 开始数,所以是 sum(mask[0:seq_len-1]))。
Tiling:谁决定怎么切分
一个大操作怎么切成 CMX 放得下的小块?这是编译器中多个 pass 协作完成的:
DPU Tiling(DpuTiler): 负责切分 DPU 操作。一个大的卷积或矩阵乘法,可能需要把输入 tensor 沿 H(高度)或 C(通道)维度切成多个 tile,每个 tile 的输入+权重+输出能放进 CMX。每个 tile 变成一个 DPUVariant——同一个 DPUInvariant(硬件配置不变)下的不同工作负载。
SHAVE Tiling(TileActShaveKernelTask): 负责切分 SHAVE 操作。和 DPU 类似,但 SHAVE 操作的 tiling 逻辑不同——它会优先选择不产生 strided memory access 的维度来切分(strided access 需要额外的 DMA 操作来重排数据,代价高)。
Vertical Fusion(PipeliningVFSche****ng): 把多个连续的操作(比如 MatMul + RoPE + Softmax)融合成一个"垂直融合区域"。融合后,中间结果可以留在 CMX 里直接传给下一个操作,不用写回 DDR 再读回来。这对 attention 块特别有用——QKV 投影的输出可以直接在 CMX 中被 RoPE 和 SDPA 消费。
所有这些决定都在编译时做出,结果编码在 blob 的任务列表里。运行时管理核只是按顺序派发,不需要做任何切分决策。
第四部分:从 Host 到 NPU 硬件
一次推理调用的完整路径
Generate 阶段每个 token 都是一次独立的 NPU 推理调用。那是不是每个 token 都要"重启"NPU?
不是。NPU 不需要重启,blob 也不需要重新编译。编译是一次性的,后续每次推理只是提交已编译好的 blob。 整个路径分为两部分:初始化时做一次的重活,和每个 token 都要做的轻活。
Blob 加载(只做一次)
驱动中的 ELF Parser 解析 blob 文件,创建一个叫 HostParsedInference(HPI)的对象。HPI 负责:
-
读取 blob 的 ELF section,为不同类型的数据分配不同属性的 NPU 内存:
-
-
可执行代码(SHAVE kernel)→
WriteCombineFw内存 -
SHAVE 数据段 →
WriteCombineShave内存 -
DMA 描述符和其他数据 →
WriteCombineDma内存
-
-
执行静态重定位——blob 中各个 section 之间有交叉引用(比如 DMA 任务描述符引用权重数据的地址),这些引用在编译时是相对偏移,加载时要修补为实际的 NPU 设备地址
-
提取元数据——输入/输出 tensor 的名称、shape、数据类型,供上层 NPUW 使用
编译本身可能花几十秒,但 NPUW 支持通过 EXPORT_BLOB 把编译好的 blob 缓存到磁盘文件,下次启动直接加载,跳过编译。
每次推理:地址修补 → 提交 → 等待
每个 token 的推理路径:
NPUW 准备输入 tensor(input_ids、attention_mask、position_ids、past KV cache)
→ JIT 重定位:把输入/输出的实际地址写入 blob
→ 提交 command list 到 NPU 命令队列
→ 管理核读取任务列表,调度 DMA/DPU/SHAVE
→ 所有任务完成,写 fence value
→ host 检测到完成
→ NPUW 读取输出(logits + present KV cache)
→ update_kvcache_for() 把 present 追加到 past
→ 采样下一个 token
→ 重复
其中 JIT 重定位(applyInputOutput) 是关键步骤。KV cache 的内存地址在每次推理时可能不同(尤其是切换 generate 变体时),驱动需要把新地址写进已加载的 blob:
blob 中的 DMA 任务描述符引用了输入 tensor(包括 past KV cache)的地址。
这些地址在 blob 中是占位符(符号引用,标记为 VPU_SHF_USERINPUT)。
applyInputOutput() 遍历所有这类重定位项,
把 NPUW 提供的 KV cache 缓冲区的 NPU 虚拟地址写入对应位置。
这样,管理核派发 DMA 任务时,DMA 引擎就知道去哪个地址取 KV cache 数据。
如果驱动版本足够新(>= 1.0),NPUW 可以用 Mutable Command Lists——Level Zero 的一个扩展特性。第一次推理时创建 command list,后续只调用 updateMutableCommands() 更新其中的 tensor 指针,不用每次重建整个 command list。这相当于在一个已经录好的"脚本"上只改几个参数,而不是重新录一遍。
提交和等待。 修补完成后,驱动调用 Level Zero API 把 command list 提交给 NPU 的硬件命令队列(底层是 DRM_IVPU_CMDQ_SUBMIT ioctl)。管理核收到任务后,按 MappedInference 中的任务列表调度执行。完成后,管理核写一个 "fence value" 到约定的内存地址。Host 侧有两种等待方式:
-
中断等待(
DRM_IVPU_BO_WAIT):省电,但延迟较高——需要内核中断唤醒用户态进程 -
轮询等待(
UMONITOR/UMWAIT):用 x86 的硬件指令监视内存地址变化,延迟更低但更耗电
真正的瓶颈不是调度
实际上,LLM decode 的瓶颈是内存带宽,不是调度开销。每生成一个 token,NPU 都要从 DDR 中读取整个模型的权重(7B 模型约 3-4 GB),但只做很少的计算(1 个 token 的矩阵向量乘法)。这是典型的内存带宽瓶颈(memory-bound)。NPU 的调度延迟在微秒级,而一次 decode 推理在毫秒级,调度开销占比很小。
不过,和 GPU 相比,NPU 目前缺少一些关键的性能优化:
-
不支持 continuou***atching——GPU 上的 vLLM 可以同时处理多个请求,用计算换带宽
-
不支持 PagedAttention——KV cache 必须是连续的固定大小缓冲区,不能按需分页
-
batch_size 只能是 1——
StatefulLLMPipeline明确限制
这些限制和 NPU 的静态执行模型直接相关:continuou***atching 需要运行时动态调整 batch,PagedAttention 需要运行时动态映射内存页——而 NPU 的 blob 在编译时就固定了一切。
第五部分:完整例子与总结
端到端流程示例
用一个具体例子把前四部分串起来。假设用户用一个 7B 参数量化 LLM 问 "Hello"(tokenize 为 1 个 token [15496])。KV cache 容量 1152,generate 变体有 256 和 1152 两种。
═══════════════════════════════════════════════════════════
初始化(只做一次,后续对话复用)
═══════════════════════════════════════════════════════════
openvino.genai:
→ 检测到 NPU 设备,设置 NPUW_LLM=YES
→ NPUW 克隆模型为 prefill (seq_len=1024) 和 generate (seq_len=1)
npu_compiler:
→ 编译 prefill blob:ReadValue/Assign 消解、FlashSDPA 展开、
32 层 unroll 为扁平任务列表、输出 ELF 格式 blob
→ 编译 generate blob × 2 个变体(256 和 1152)
→ 缓存到磁盘(EXPORT_BLOB)
linux-npu-driver:
→ ElfParser 解析 blob → 分配 NPU 设备内存 → 静态重定位
→ 创建 HostParsedInference 对象
═══════════════════════════════════════════════════════════
新对话开始
═══════════════════════════════════════════════════════════
NPUW: prepare_for_new_conversation(prompt_length=1)
→ memset(0) 清零所有 KV cache 缓冲区
→ num_stored_tokens = 0
→ select_generate_request(1):
需要 1 + 128 = 129 个位置 → 选择 256 变体
═══════════════════════════════════════════════════════════
Prefill
═══════════════════════════════════════════════════════════
NPUW 准备输入:
input_ids = [15496, 0, 0, ..., 0] 长度 1024,只有第 1 个有效
attention_mask = [1, 0, 0, ..., 0] 1 个 1 + 1023 个 0
position_ids = [0, 0, 0, ..., 0] 第 1 个有效
past KV = 全零 新对话,无历史
驱动: applyInputOutput() JIT 重定位 → 提交 command list
NPU 芯片内部执行(管理核按任务列表派发,32 层已展开为连续任务序列):
→ DMA: 搬第 1 层权重 DDR → CMX
→ DPU: W_q × input → Q, W_k × input → K, W_v × input → V
→ SHAVE: RoPE(Q, cos, sin), RoPE(K, cos, sin)
→ SHAVE: FlashSDPA(Q, K, V, mask) → attention_output
→ DPU: FFN 两层矩阵乘 + SHAVE: 激活函数
→ DMA: 写回 DDR,同时开始搬第 2 层权重(流水重叠)
→ ... 重复 32 层 ...
管理核写 fence value → host 检测到完成
输出:
logits → 采样得到 token "是"(假设 id=123)
present KV cache: 每层 2 个 tensor,各含 1 个 token 的 K/V
═══════════════════════════════════════════════════════════
Prefill → Generate 切换
═══════════════════════════════════════════════════════════
NPUW: copy_kvcache()
→ 64 个 tensor 并行拷贝(32 层 × K + V):
prefill present[0:1] → generate(256 变体) past[0:1]
→ num_stored_tokens = 1
═══════════════════════════════════════════════════════════
Generate 循环(每个 token 重复)
═══════════════════════════════════════════════════════════
--- 生成第 2 个 token ---
NPUW: infer_generate()
input_ids = [0, ..., 0, 123] 右对齐
position_ids = [0, ..., 0, 1] 右对齐,值 = sum(mask) - 1
attention_mask = [1, 0, ..., 0, 1] 1 个历史 + 253 个 0 + 1 个当前
past KV = [K₁, 0, 0, ..., 0] 256 长度,位置 0 有数据
驱动: Mutable Command List 更新 tensor 地址 → 提交
NPU 执行(generate blob,任务更少——seq_len=1 计算量小):
→ DPU: Q/K/V 投影
→ SHAVE: RoPE(1 个 token)
→ SHAVE: incremental_sdpa(1 个 Q vs 2 个 KV)
→ DPU: FFN
NPUW: update_kvcache_for()
→ make_tensor_slice(past, dim=seq, start=1, end=2)
→ 把 present 写入 past[1]
→ num_stored_tokens = 2
采样得到下一个 token...
--- 生成第 3 个 token ---
position_ids = [0, ..., 0, 2]
attention_mask = [1, 1, 0, ..., 0, 1] 2 个历史 + 252 个 0 + 1 个当前
past KV = [K₁, K₂, 0, ..., 0]
→ incremental_sdpa: 1 个 Q vs 3 个 KV
... 如此重复,直到生成 EOS 或达到 256 容量上限 ...
═══════════════════════════════════════════════════════════
结束
═══════════════════════════════════════════════════════════
openvino.genai:
→ 检测到 EOS token(或达到最大长度)
→ detokenize 所有生成的 token → 返回文本给用户
填充副作用与进阶优化
静态 shape 方案有一个隐蔽的问题:padding 区域里的"垃圾数据"可能影响某些计算的正确性。 Attention mask 能让 softmax 忽略 padding 位置,但 LayerNorm 和 reduction 操作会对整个 tensor 计算均值或求和——它们不感知 mask。npu_compiler 用 DynamicDataMask 操作在这些操作之前把 padding 区域清零,作为静态 shape 方案的正确性补丁。
NPUW 还实现了几个面向实际部署的优化:
Prefix Caching。 多轮对话通常共享相同的 system prompt。PrefixCachingHelper 缓存公共前缀的 KV cache,新一轮对话直接复用,跳过重复的 prefill。
Speculative Decoding。 投机解码用小模型快速猜多个 token,大模型验证。被拒绝的 token 需要从 KV cache 撤回——trim_kvcache_for_speculative_decoding() 把 cache 截断到最后一个被接受的位置。
LM Head 分离。 模型最后一层(LM Head)是一个 hidden_size × vocab_size 的大矩阵乘法。如果 NPU 做这个不如 CPU 快,NPUW 可以把它切出来跑在 CPU 上,NPU 只负责 Transformer 主干。
当前限制
NPU 上的 KV cache 管理有几个现实限制:
固定容量。 KV cache 大小在编译时确定。如果对话超过预设容量(默认 1152 个 token),要么报错,要么截断历史重新 prefill。GPU 上的 PagedAttention 没有这个限制。
Batch size = 1。 当前 NPU 不支持同时处理多个请求。这对笔记本上的单用户对话不是问题,但意味着 NPU 不适合服务端的高并发推理。
KV cache 搬运开销。 Prefill 到 generate 的 copy_kvcache() 是一次大规模内存操作。以一个 32 层、32 heads、head_dim=128 的 7B 模型为例:
32 层 × 2(K+V)× 32 heads × 1024 seq_len × 128 head_dim × 2 bytes(FP16)
= 512 MB
虽然 NPUW 会尝试通过 bind_past_kv 共享内存来避免拷贝,但并不总是可行。
多次编译。 多个 generate 变体意味着多次 NPU 编译,冷启动时间更长。好在编译结果可以缓存到磁盘。
这些限制也解释了 NPU 的定位:它更适合笔记本上的单用户本地 LLM 推理——batch_size=1 是常态,固定容量足够覆盖大多数对话长度,而 NPU 相比 GPU 的优势在于低功耗和不占用 GPU 资源(你可以一边用 GPU 打游戏一边让 NPU 跑 AI 助手)。
第六部分:编程模型的反思——为什么不能 ONNX 了事
从前五部分看到了什么
回顾前五部分描述的 NPU 推理全景,一个模式反复出现:所有决策都在编译时做出,运行时只是按剧本执行。
-
Tiling 策略?编译器的
DpuTiler和TileActShaveKernelTask在编译时决定。 -
DMA 搬运计划?
FeasibleMemoryScheduler在编译时规划好 prefetch 提前量、ping-pong 缓冲、溢出策略。 -
Attention 用哪种实现?编译器根据硬件能力选择分解路径、Flash SDPA 还是 incremental SDPA。
-
KV cache 怎么切分?编译器把
UnrollFlashSDPA展开成固定的 tile 链。 -
甚至"KV cache 能装多少 token"?都是编译时的
MAX_PROMPT_LEN + MIN_RESPONSE_LEN决定的。
这套模型在已知场景下运转良好。前五部分描述的 LLM 推理流程——prefill/generate 分离、chunked prefill、generate 变体选择、incremental SDPA——每一个都是精心设计的解决方案,由 OpenVINO 团队在编译器和运行时中实现。
但问题是:这些解决方案全部是 OpenVINO 团队写的,不是算子作者写的,更不是模型作者写的。
"编译器包揽一切"的代价
前五部分其实已经暴露了这套模型的裂缝,只是没有点破。
裂缝一:每种 attention 变体都需要专门的 SHAVE kernel。
从 SHAVE kernel 库的演进能看到:先有通用的 sdpa,发现 decode 场景性能不行,加了 incremental_sdpa;发现 prefill 长序列放不进 CMX,加了 flash_sdpa。三个 kernel 对应三种场景,每一个都是编译器团队手工编写的 SHAVE ELF 二进制。
如果明天出现一种新的 attention 变体——比如 Sliding Window Attention(窗口化注意力,只看最近 N 个 token)、Cross Attention(跨模态注意力)、或者 Linear Attention(线性复杂度注意力)——会怎样?答案是:等编译器团队写一个新的 SHAVE kernel,加一个新的 compiler pass 来识别并路由到这个 kernel,测试,发布。周期以月计。
裂缝二:静态 shape 方案的每个副作用都需要专门的补丁。
第五部分提到 DynamicDataMask——因为 padding 区域的垃圾数据会污染 LayerNorm 的计算,编译器要在特定操作前插入清零。这不是一个通用方案,而是一个针对"静态 shape + padding"这种特定策略的特定补丁。如果换一种 KV cache 管理策略(比如 ring buffer、或者 token dropping),LayerNorm 的问题可能消失但会冒出新的问题,需要新的补丁。
裂缝三:generate 变体是用蛮力弥补灵活性的缺失。
编译器不知道运行时 prompt 会多长,所以编译 4 个不同容量的 blob。这是一种"提前猜测所有可能的运行时状态"的策略——本质上是在编译时枚举运行时的动态性。如果参数空间更大(不只是 KV cache 长度,还有 batch size、beam width、speculative decoding 的猜测长度……),排列组合会爆炸。
裂缝四:KV cache 搬运是架构决策的直接后果。
Prefill 和 generate 分成两个 blob,因为 input_ids 的 shape 不同。但它们的 KV cache 本质上是同一份数据,只是被迫存在两个不同 shape 的容器里。512 MB 的 copy_kvcache() 不是算法的需要,而是"blob 必须静态 shape"这个约束的代价。如果算子作者能控制内存布局——比如让两个 blob 共享同一块 KV cache 内存,只是用不同的 view 去读——这次拷贝可能完全不需要。
ONNX 的边界在哪里
ONNX 是一种模型交换格式。它描述的是计算图:节点是操作(MatMul、Softmax、Add),边是 tensor。它告诉推理引擎"做什么",不说"怎么做"。
对于标准操作,这足够了。一个 MatMul 节点,推理引擎知道该怎么映射到 DPU;一个 Softmax 节点,引擎知道该分配给 SHAVE。ONNX 的价值在于可移植性——同一个模型可以跑在 CPU、GPU、NPU 上,各自的引擎各自优化。
但 ONNX 表达不了的东西,恰好是性能关键的东西:
ONNX 表达不了 tiling 策略。 Flash Attention 的核心不是"Q 乘 K 再乘 V"——ONNX 能表达这些基础操作。Flash Attention 的核心是怎么切 tile、怎么在 tile 之间传递 running_max 和 running_sum、怎么在有限的片上存储中完成整个 attention。这是一种特定的执行策略,不是一种新的数学操作。ONNX 的 SDPA 算子只说"请做 Scaled Dot-Product Attention",不说"请用 Flash 的方式做"。
ONNX 视角:
SDPA(Q, K, V, mask) → output
// 一个黑盒。怎么实现是推理引擎的事。
Flash Attention 视角:
for each tile of K, V:
local_scores = Q @ K_tile.T / sqrt(d)
local_max = max(local_scores)
correction = exp(running_max - new_max) // 数值稳定性校正
running_output = running_output * correction + exp(local_scores - new_max) @ V_tile
running_max = new_max
running_sum = running_sum * correction + sum(exp(local_scores - new_max))
output = running_output / running_sum
// 不只是"做什么",更是"按什么顺序、用多大的块、怎么在有限内存中完成"
推理引擎可以选择用 Flash 的方式实现 SDPA——NPU 编译器确实这么做了(UnrollFlashSDPA)。但这个实现是编译器团队硬编码的,不是模型作者指定的。如果算法有变化——比如 Flash Attention 3 引入了异步 warp sche****ng,或者 Ring Attention 需要跨设备传递 KV tile——编译器团队要重新实现。
ONNX 表达不了内存布局偏好。 KV cache 存成 [batch, heads, seq_len, head_dim] 还是 [batch, seq_len, heads, head_dim]?对算**确性没影响,但对 DMA 效率影响巨大——前者在遍历 seq_len 时内存连续,后者在遍历 heads 时内存连续。incremental SDPA 需要沿 seq_len 扫描整个 KV cache,所以 heads 和 seq_len 的相对位置直接决定了 DMA 是否产生 strided access(第三部分提到 SHAVE tiling 会优先避免 strided access,正是因为它代价高)。ONNX 不表达布局,布局由推理引擎决定。
ONNX 表达不了"哪些中间结果值得留在片上"。 Vertical Fusion——把 MatMul 的输出留在 CMX 里直接给 RoPE 用,不写回 DDR——是一个巨大的性能优化。但 ONNX 只描述了操作的依赖关系,不描述哪些操作应该融合、哪些中间 tensor 应该常驻片上存储。这个决策目前由编译器的 PipeliningVFSche****ng pass 自动做出。大多数时候它的选择是对的,但"大多数时候"和"总是"之间的差距,就是性能调优的空间。
cuTile 的启示:第三条路
GPU 生态面临的问题和 NPU 完全一样,只是规模更大。
在 cuTile 之前,GPU 上写高性能算子有两个选择:
-
用 ONNX/PyTorch → 框架自动优化 → 性能"还行"但不是最优
-
写 raw CUDA → 手管 shared memory、warp 调度、bank conflict、DMA → 性能最优但开发成本极高
CUTLASS(NVIDIA 的矩阵乘法模板库)就是第二条路的产物:几万行 C++ 模板,为每种 GPU 架构手工调优,连 shared memory 的 swizzle 模式都要手写。Flash Attention 的原始实现也是如此——Tri Dao 的论文之所以重要,不只是算法创新,更是因为他用 raw CUDA 实现了一个高效的 tiled attention,这本身就是一个工程壮举。
cuTile 开辟了第三条路:
抽象层级:
ONNX / PyTorch → "做 Attention" → 推理引擎自己想办法
cuTile → "按这个 tile 大小做" → 编译器处理 DMA 和硬件映射
raw CUDA / SHAVE ASM → "这样管 shared memory" → 开发者处理一切
cuTile 代码长什么样?以 attention 的一个 tile 为例:
@ct.kernel
def attention_tile(Q, K, V, output):
block_id = ct.bid(0)
# 算子作者决定:tile 大小是 64(这是性能关键参数)
q_tile = ct.load(Q, index=(block_id,), shape=(64, HEAD_DIM))
running_max = ct.full((64,), float('-inf'))
running_sum = ct.zeros((64,))
running_out = ct.zeros((64, HEAD_DIM))
# 算子作者决定:KV cache 沿 seq_len 切成 128 大小的 tile
for kv_block in range(NUM_KV_BLOCKS):
k_tile = ct.load(K, index=(kv_block,), shape=(128, HEAD_DIM))
v_tile = ct.load(V, index=(kv_block,), shape=(128, HEAD_DIM))
scores = q_tile @ k_tile.T / math.sqrt(HEAD_DIM)
new_max = ct.maximum(running_max, ct.max(scores, dim=-1))
# Flash Attention 的核心:在线 softmax 校正
correction = ct.exp(running_max - new_max)
running_out = running_out * correction[:, None] + ct.exp(scores - new_max[:, None]) @ v_tile
running_sum = running_sum * correction + ct.sum(ct.exp(scores - new_max[:, None]), dim=-1)
running_max = new_max
output_tile = running_out / running_sum[:, None]
ct.store(output, index=(block_id,), tile=output_tile)
注意算子作者控制了什么:
-
Q tile 大小是 64(不是 32,不是 128——这取决于 GPU shared memory 容量和 warp 利用率)
-
KV tile 大小是 128(不同于 Q tile——因为 K/V 的访问模式不同)
-
tile 间的 running_max/running_sum 传递逻辑(这是 Flash Attention 的数学核心)
-
循环结构(先遍历 KV blocks,每个 block 内做 matmul + softmax 校正)
注意算子作者没有控制什么:
-
ct.load()背后的 DMA 怎么发起——是同步的还是异步 prefetch?编译器决定 -
q_tile 存在 shared memory 的哪个地址——bank conflict 怎么避免?编译器决定
-
matmul 映射到哪些 Tensor Core 指令——用
mma.sync还是wgmma?编译器决定 -
多个 block 怎么在 SM 上调度——是否需要 persistent kernel?编译器决定
这就是"有一定的自由度,但不用关心 DMA"的含义。算子作者表达的是算法层面的 tiling 决策,编译器负责硬件层面的资源映射。
假设 NPU 有 cuTile
如果把 cuTile 的思路搬到 NPU 上,前五部分中的很多问题可能有不同的解法。
Flash SDPA 不再需要编译器团队手写 SHAVE kernel。 算子作者用类似 cuTile 的 DSL 写一个 tiled attention,指定 tile 大小和 running state 传递逻辑。NPU 的 Tile IR 编译器负责把它映射到 SHAVE 指令集、安排 DMA 搬运、处理 CMX 分配。新的 attention 变体不需要等编译器发版,算子作者自己就能写。
Tiling 策略可以根据模型特点调整。 当前编译器的 tiling 是通用策略——DpuTiler 根据 CMX 容量和对齐要求自动切分。但不同模型的最优 tiling 可能不同:长上下文模型(128K tokens)可能需要更大的 KV tile 来摊薄 DMA 开销;小模型(1B 参数)可能 CMX 放得下整层权重,根本不需要 tiling。如果算子作者能指定 tile 大小,这些模型级别的调优就不需要改编译器。
新算法的验证周期从月缩短到天。 想试试 Sliding Window Attention?写一个只 load 最近 N 个 token 的 tile 循环就行,不需要改 npu_compiler。想试试 GQA(Grouped Query Attention)?改一下 K/V tile 的 load 模式——多个 Q head 共享同一个 KV tile。这些实验目前需要深入理解 SHAVE 指令集和 npu_compiler 的内部结构,门槛极高。
为什么 ONNX 不够:一张对比表
回到最初的问题——为什么不能直接 ONNX 了事?
|
维度 |
ONNX |
cuTile 式 DSL |
|---|---|---|
| 表达什么 |
计算图(做什么操作、操作间的依赖) |
Tiled 算法(tile 多大、tile 间怎么传递状态、循环怎么走) |
| Tiling |
不表达。推理引擎自动决定 |
算子作者指定 tile shape,编译器映射到硬件 |
| DMA/内存搬运 |
不表达。推理引擎自动决定 |
不表达。编译器自动决定(和 ONNX 一样隐藏了 DMA) |
| 新算子 |
要么用已有算子组合(性能差),要么等引擎支持新算子(周期长) |
算子作者直接写 tiled 实现 |
| 调优空间 |
几乎为零。引擎配置参数极少 |
tile 大小、循环顺序、数据分区策略 |
| 可移植性 |
极好(跨硬件) |
好(跨同厂商的硬件代际,Tile IR 的目标) |
| 开发门槛 |
极低(导出模型即可) |
中等(需要理解 tiling 概念,但不需要硬件知识) |
关键的洞察是:cuTile 和 ONNX 都隐藏了 DMA,但 cuTile 暴露了 tiling。 这个差异看起来小,实际上是决定性的。
为什么?因为 tiling 是算法和硬件之间的接口。
-
往上看,tiling 决策依赖算法知识——Flash Attention 需要在 tile 间传递 running_max,这是算法特性;Sliding Window Attention 只需要 load 最近 N 个 tile,这也是算法特性。只有算法作者知道这些。
-
往下看,每个 tile 的执行方式依赖硬件知识——CMX 容量、DMA 带宽、DPU 对齐要求、SHAVE 向量宽度。这些只有编译器知道。
ONNX 把 tiling 也交给了编译器,所以编译器既要理解算法(识别 SDPA 模式、选择 Flash 实现),又要理解硬件(安排 DMA、管理 CMX)。cuTile 在 tiling 这个层面切了一刀:算法知识归算子作者,硬件知识归编译器。
现实的另一面:ONNX 的价值不该被否认
上面的分析可能给人一个印象——ONNX 不好用。事实恰恰相反。
对 99% 的用户来说,ONNX + 推理引擎是正确的选择。 大多数模型使用标准的 attention、标准的 FFN、标准的归一化。OpenVINO 编译器已经为这些标准操作实现了足够好的优化路径。用户导出 ONNX,运行 optimum-cli export,就能在 NPU 上跑起来。不需要理解 DMA,不需要理解 tiling,不需要理解 CMX。
cuTile 面向的不是这些用户。它面向的是那 1% 的算子作者——写 Flash Attention 的人、写新激活函数的人、为特定硬件调优矩阵乘法的人。他们的工作成果最终会被包进推理引擎,让 99% 的用户受益。问题是他们的生产力:如果写一个新算子需要 3 个月(理解 SHAVE 指令集 + 改编译器),那一年只能发布 4 个新算子;如果只需要 3 天(用 cuTile 式 DSL 写 tiled 算法),一年能发布几十个。
这就是 NVIDIA 写 cuTile 的真正原因:不是为了替代 ONNX/PyTorch,而是为了加速推理引擎内部的算子开发。 最终,ONNX 用户什么都不用改,但他们享受到的 SDPA 实现更快了,因为算子作者的迭代周期缩短了。
对 NPU 生态的启示
Intel NPU 当前的编程模型是前五部分描述的三层栈:genai → NPUW → npu_compiler。算子实现完全锁在 npu_compiler 内部,以预编译的 SHAVE ELF 二进制形式存在(719 个文件,覆盖 195 个算子家族)。
这意味着:
-
算子创新的速度被编译器团队的人力瓶颈卡住。 每个新算子都需要理解 SHAVE VLIW 指令集、npu_compiler 的 pass 管线、以及 DMA/barrier 调度机制的人来写。全世界有这个能力的人可能不超过几十个。
-
模型作者和算子作者之间有一堵墙。 模型作者不能试验新的 attention 模式在 NPU 上的效果——他只能用编译器已经支持的那些。这限制了 NPU 生态的创新速度。
-
性能调优是不透明的。 如果一个模型跑得慢,用户不知道是 tiling 策略不好、DMA 调度不好、还是 SHAVE kernel 本身不好。他也没有工具去调。唯一的选择是报 bug 给 OpenVINO 团队。
这些不是批评——对于一个定位为"笔记本低功耗 AI 助手"的设备来说,这套模型是合理的。绝大多数用户不需要写自定义算子。但如果 NPU 想要更广泛的生态(不只跑 LLM,还跑新的架构、新的应用场景),某种形式的"算子作者可编程性"——不管叫不叫 cuTile——可能是绕不开的。
前五部分展示了 NPU 在已知问题上的精巧工程。这一部分想说的是:硬件的天花板不只是算力和带宽,也是编程模型允许多少人为它写高效代码。
OpenVINO 小助手微信: OpenVINO-China
如需咨询或交流相关信息,欢迎添加OpenVINO小助手微信,加入专属社群,与技术专家实时沟通互动。