Intel 第一时间支持腾讯混元 Hy-MT2系列模型
 openlab_96bf3613
更新于 1月前
openlab_96bf3613
更新于 1月前
一、导语:Hy-MT2 发布即可在 Intel 平台一键部署
2026 年 5 月 21 日,腾讯混元正式开源了全新一代翻译模型家族 Hy-MT2,覆盖 1.8B、7B、30B-A3B(MoE)三档规格,支持 33 种语言互译,并配套上线了「腾讯Hy翻译」小程序。同一天,OpenVINO™ Notebooks 仓库的 PR #3464(add hy-mt2)也完成提交,将 tencent/Hy-MT2-1.8B 与tencent/Hy-MT2-7B 接入了既有的 Hunyuan Translation Notebook,并把默认推理目标切换到了 Hy-MT2 系列。
这意味着开发者从模型发布的Day-0起就可以在任意 Intel CPU / iGPU / 独立显卡 / NPU 上,通过 optimum-intel + openvino-genai 的标准工具链,把 Hy-MT2 高效地跑起来。本文将基于 PR #3464 的最新代码,给出一条完整、可**的端到端部署路径。
二、Hy-MT2 模型亮点
根据腾讯混元官方发布稿,Hy-MT2 在多个维度做了系统性升级,本节先梳理几个对部署侧最具参考价值的特征。
2.1 三档规格,覆盖端到云
Hy-MT2-1.8B:面向端侧、轻量部署,适合个人 PC、AI PC、Intel iGPU/NPU。
Hy-MT2-7B:面向均衡场景,质量与算力开销折中,独立显卡(Arc)或更高规格 iGPU 推荐。
Hy-MT2-30B-A3B:MoE 架构,激活参数约 3B,面向专业领域翻译。
2.2 翻译质量:33 语言、对标头部模型
在 FLORES-200 通用翻译榜上,Hy-MT2 系列平均水平已经非常接近目前业内表现最好的翻译模型 Gemini 3.1 Pro;
Hy-MT2-7B / 30B-A3B 在国内主流通用大模型对比中处于领先位置;
1.8B 这个轻量档位,整体效果优于头部商业翻译 API(含微软等);
在金融、政治、教育等真实业务场景测试集上,30B-A3B 部分效果超越主流翻译模型。
2.3 指令遵循能力(IFMT Bench)
Hy-MT2 相比上一代最大的提升是可控翻译:用户可以通过 prompt 直接要求术语对齐、语气风格、输出格式甚至字数限制,例如「翻译结果简洁精炼,去掉冗余表达,每句不超过 15 个字」。混元自建的 IFMT Bench 也已开源,便于业务方做自有场景评测。
2.4 量化矩阵与极致压缩
官方提供了 FP16 / INT8 / INT4 / 2-bit / 1.25-bit 多档权重,其中 1.25-bit 版本仅需约 440MB 存储即可部署到主流手机芯片,在苹果 A15 上相比 Hy-MT1.5 4-bit 推理速度提升约 1.5 倍(数据来源:腾讯混元官方发布,2026-05-21)。在 Intel 平台上,我们重点利用 OpenVINO™ + NNCF 的 INT4/INT8 通用量化方案,下面给出完整流程。
三、为什么选 OpenVINO™ 部署 Hy-MT2
optimum-intel:一行optimum-cli export openvino 即可把 Hugging Face 模型转成 OpenVINO™ IR,并内置 NNCF 权重压缩,免写转换脚本。
openvino-genai:高阶 LLM 推理 API,自带 KV-Cache、采样、流式输出、Chat 模板,几行就能跑出生产级别 pipeline。
全平台一致体验:相同的 IR 模型可以无差别跑在 Intel CPU、酷睿 Ultra iGPU、Arc 独立显卡和 NPU 上,仅需切换 device 字符串。
四、端到端部署 Hy-MT2
下文所有命令与代码均来源于notebooks/hunyuan-translation/hunyuan-translation.ipynb,对照 notebook 阅读体验最佳。
4.1 环境准备
建议 Python 3.10 及以上,先创建并激活一个干净的虚拟环境,再依次安装依赖:
python -m venv hymt2-env# Windows: hymt2-env\Scripts\activate# Linux / macOS: source hymt2-env/bin/activatepip install -U openvino-genaipip install --extra-index-url https://download.pytorch.org/whl/cpu \"git+https://github.com/huggingface/optimum-intel.git" \# https://github.com/openvino-dev-samples/optimum-intel.git@HYV3 for tencent/Hy-MT2-30B-A3B"nncf>=2.18.0" \"torch>=2.8" \"transformers>=4.57.0" \"accelerate" \"gradio>=6.0" \"huggingface-hub"# macOS 用户额外执行:# pip install "numpy<2.0.0"
4.2 一键导出量化 IR 模型
推荐使用 INT4 权重压缩,体积约为 FP16 的 1/4,精度损失可控:
optimum-cli export openvino \--model tencent/Hy-MT2-1.8B \--task text-generation-with-past \--weight-format int4 \--ratio 0.8 \--group-size 128 \Hy-MT2-1.8B/INT4
--ratio 0.8 表示 80% 的权重走 INT4,剩余 20% 保留为更高精度的混合精度配置(典型为 INT8),用于对量化更敏感的层;--group-size 128 是 NNCF 分组量化的组大小,是社区在 LLM 上验证较稳的一档默认值。
如果想要更高的质量或更小的文件,分别有:
# INT8 权重压缩(质量更高、体积约为 FP16 一半)optimum-cli export openvino --model tencent/Hy-MT2-1.8B \--task text-generation-with-past --weight-format int8 \Hy-MT2-1.8B/INT8# FP16 全精度(最大质量、最大体积)optimum-cli export openvino --model tencent/Hy-MT2-1.8B \--task text-generation-with-past --weight-format fp16 \Hy-MT2-1.8B/FP16# 切换为 7B 时只需替换 model 参数optimum-cli export openvino --model tencent/Hy-MT2-7B \--task text-generation-with-past --weight-format int4 \--ratio 0.8 --group-size 128 \Hy-MT2-7B/INT4
4.3 选择推理设备
Notebook 内置了一个简易的设备选择 widget,原型如下:
from notebook_utils import device_widgetdevice = device_widget(default="CPU")device # 在 Jupyter 中渲染下拉框:CPU / GPU / NPU / AUTO
CPU:兼容性最好,1.8B INT4 即可获得不错的交互速度。
GPU:包含酷睿 Ultra iGPU 与 Arc 独立显卡,是 7B 模型的首选。
NPU:酷睿 Ultra 平台的低功耗 AI 加速器,适合长时间运行端侧翻译。
AUTO:交给 OpenVINO™ 自动决策,便于跨平台分发。
4.4 用 OpenVINO™ GenAI 构建推理管线
import openvino_genai as ov_genaimodel_dir = "Hy-MT2-1.8B/INT4"pipe = ov_genai.LLMPipeline(model_dir, device.value) # 例如 "GPU"generation_config = ov_genai.GenerationConfig()generation_config.max_new_tokens = 256
LLMPipeline 内部已经处理好 KV-Cache、采样器、tokenizer 装载等细节。如果需要更可控的输出,可以补上 temperature、top_p、repetition_penalty 等字段。
4.5 中英双向 Prompt 模板
PR #3464 内置了一份中英双向的 prompt 构造函数:源/目标语言任一为中文时使用中文 prompt,否则使用英文 prompt。
CHINESE_LANGUAGES = {"Chinese", "Traditional Chinese"}LANGUAGE_MAP = {"Chinese": "中文", "English": "English", "Japanese": "日本語"}def build_translation_prompt(source_text, source_lang, target_lang):target_name = LANGUAGE_MAP.get(target_lang, target_lang)if source_lang in CHINESE_LANGUAGES&nb********sp;target_lang in CHINESE_LANGUAGES:return (f"将以下文本翻译为{target_name},"f"注意只需要输出翻译后的结果,不要额外解释:\n\n{source_text}")return (f"Translate the following segment into {target_name}, "f"without additional explanation.\n\n{source_text}")
4.6 一次完整的翻译推理(流式输出)
import sysdef streamer(subword: str) -> bool:print(subword, end="", flush=True)sys.stdout.flush()return False # 返回 True 可中断生成# 示例 1:中文 → 英文prompt_en = build_translation_prompt(source_text="OpenVINO 第一时间支持了腾讯混元最新一代翻译模型 Hy-MT2。",source_lang="Chinese",target_lang="English",)pipe.generate(prompt_en, generation_config, streamer)# 示例 2:英文 → 中文prompt_cn = build_translation_prompt(source_text="OpenVINO supports Tencent Hunyuan'***rand-new Hy-MT2 translation model on day one.",source_lang="English",target_lang="Chinese",)pipe.generate(prompt_cn, generation_config, streamer)
五、可选:启动 Gradio 多语言翻译 Web Demo
Notebook 在最后还提供了一个开箱即用的 Gradio 演示界面,可以让产品、运营同学在浏览器中直接体验:
from gradio_helper import make_demodemo = make_demo(pipe, build_translation_prompt)demo.launch(server_name="0.0.0.0", server_port=7860)
默认会启动一个本地 Web 服务,左侧选源语言、目标语言并填入要翻译的文本,右侧实时流式输出翻译结果,便于与同事一起评估翻译质量。
六、性能与精度建议
对于个人 AI PC(英特尔酷睿 Ultra),1.8B INT4 在 iGPU 上即可获得流畅的交互体验,是最推荐的入门档位。
对于 7B 模型,建议使用 Arc A 系列独显或 Arc B 系列以获得稳定的 token/s。
若对翻译质量有更高要求,可将 INT4 切到 INT8 或 FP16。
七、应用集成
如果您是一位技术小白,可以选择使用Herd**an-牧马人本地推理引擎,通过可视化界面的简单操作,快速完成Hy-MT2 1.8B翻译模型的本地部署
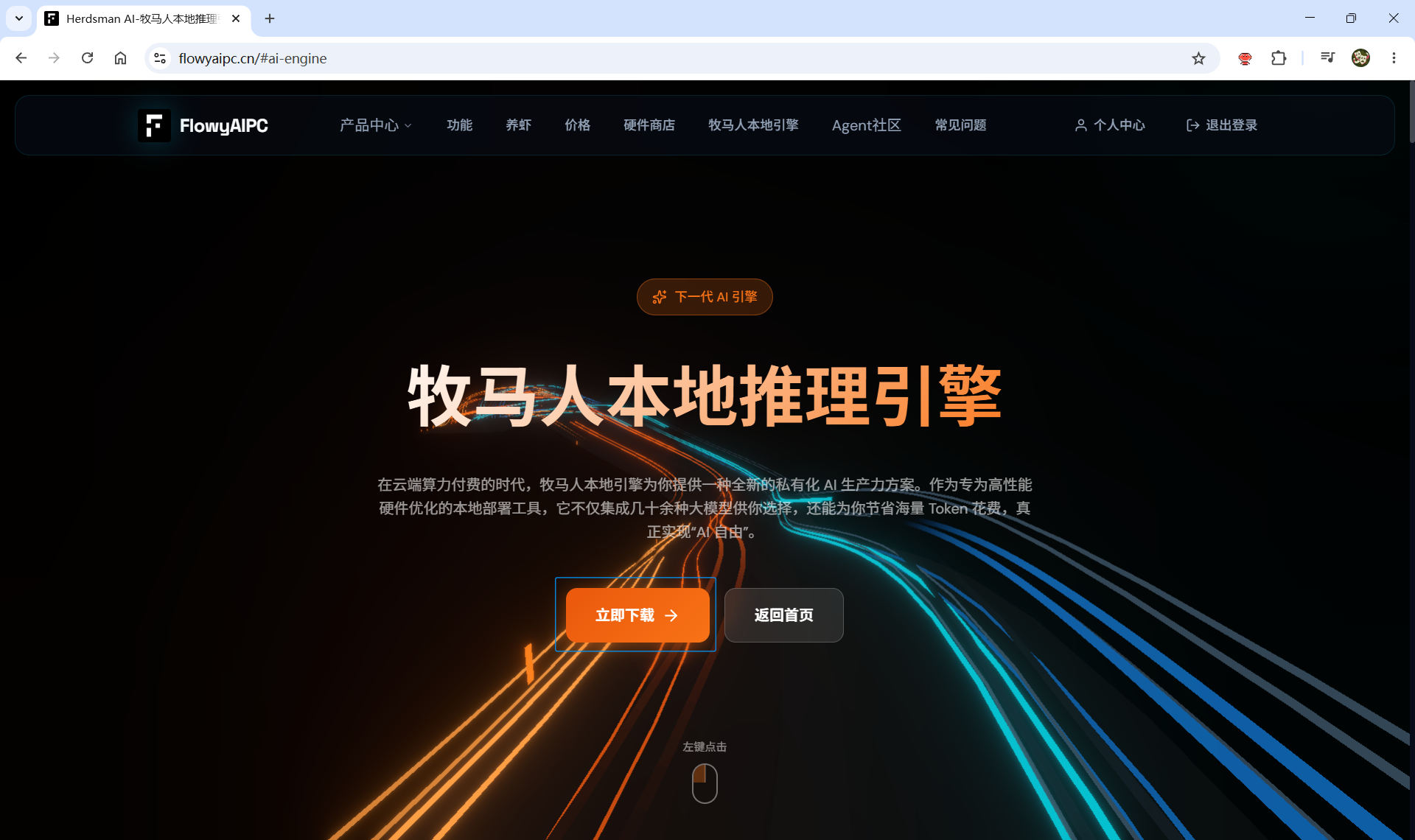
7.1 快速下载herd**an,免安装
访问herd**an官网(地址:https://flowyaipc.cn/#ai-engine),点击立即下载,下载以后直接打开,无需安装
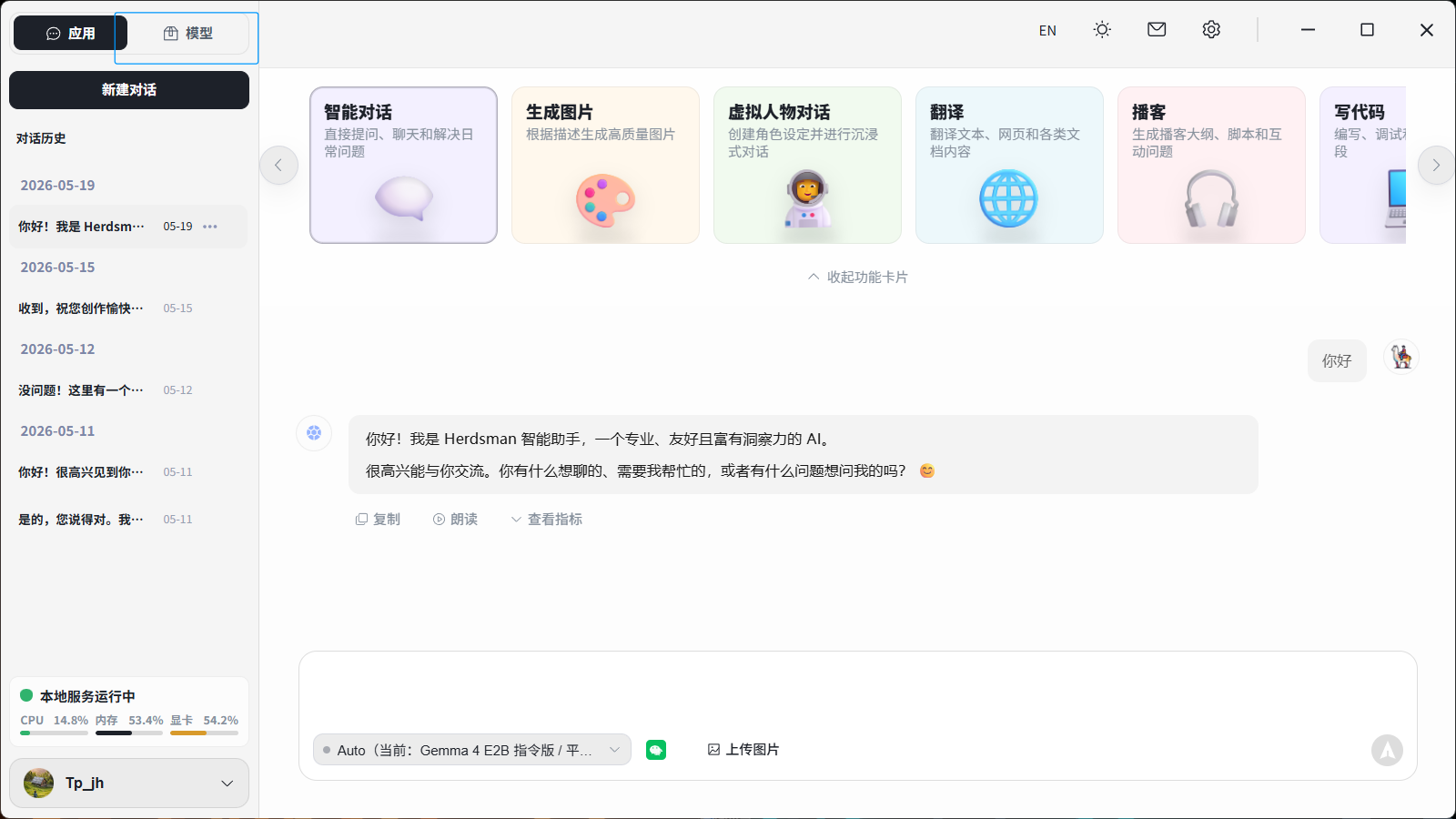
7.2 打开Herd**an模型中心
打开Herd**an 首页,点击左上角进入模型区域
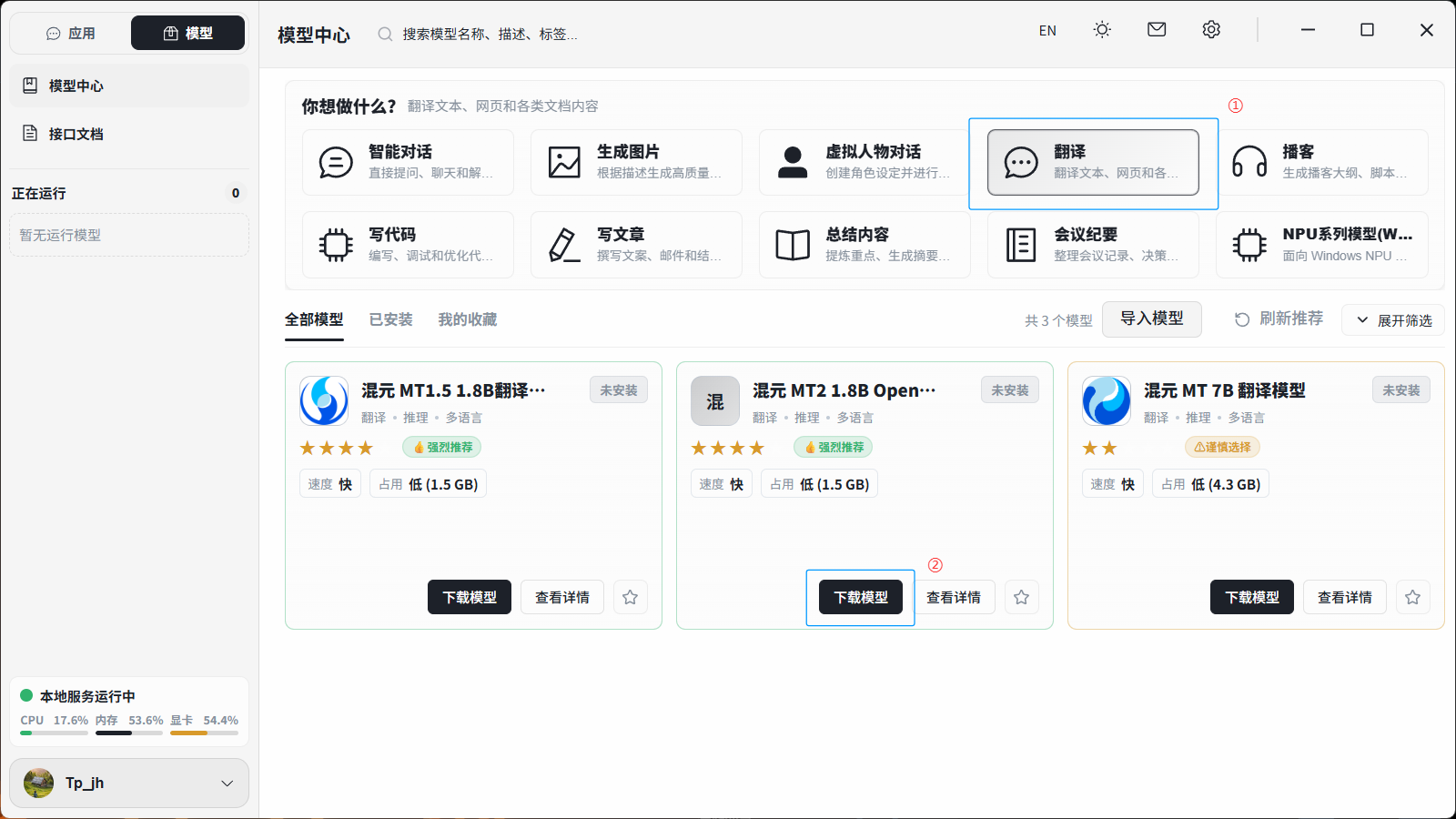
7.3 下载Hy-MT2 1.8B模型
进入模型中心,打开翻译,便可以看到腾讯混元MT2 1.8B 翻译模型,点击下载模型
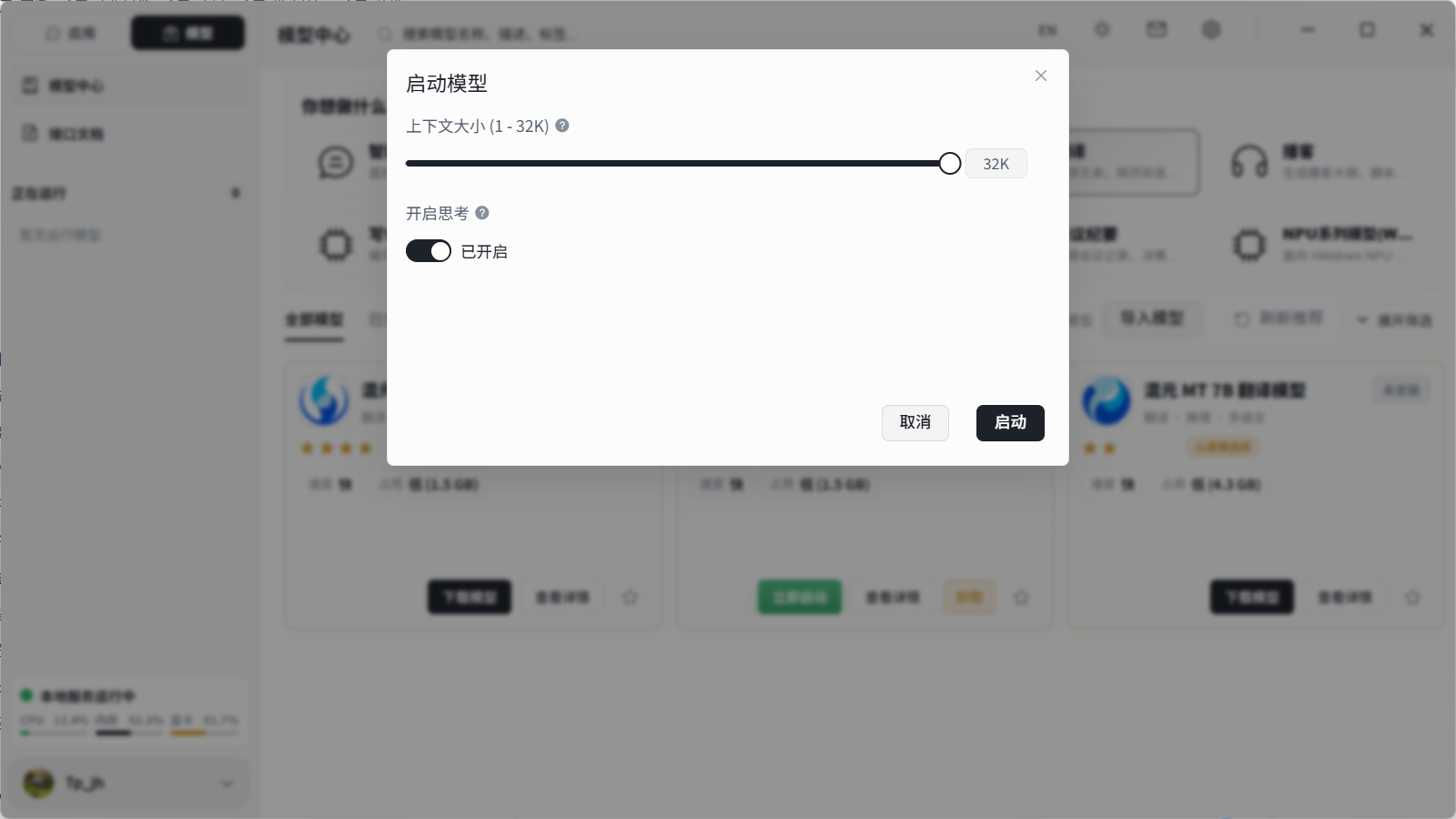
7.4 启动模型
模型下载好以后,点击立即启动,把模型上下文大小拉到最大,并且开启思考模式,再次点击启动,等待模型启动即可
7.5 开始翻译
返回应用界面,选择翻译,切换MT2模型,即可开始翻译
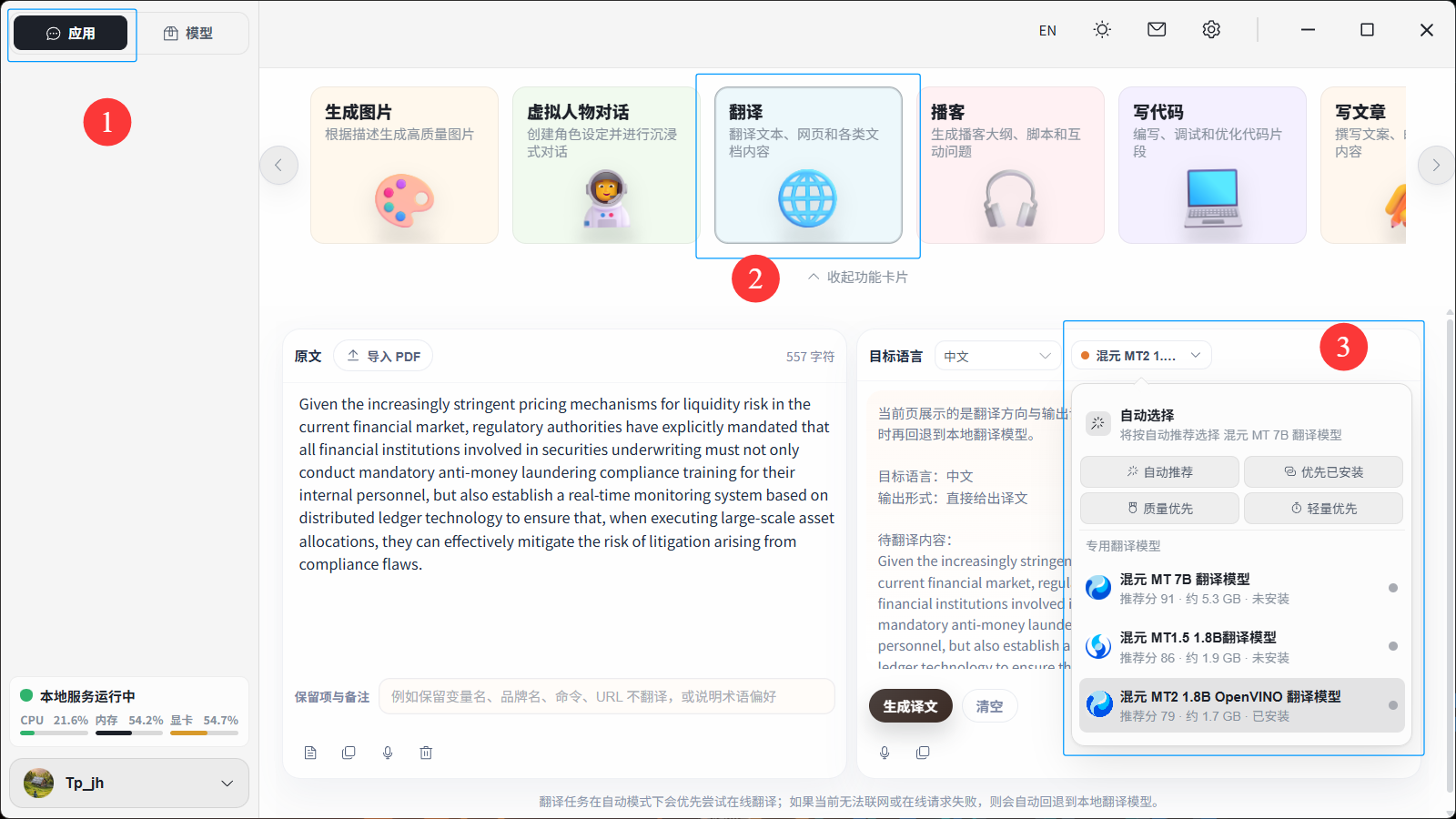
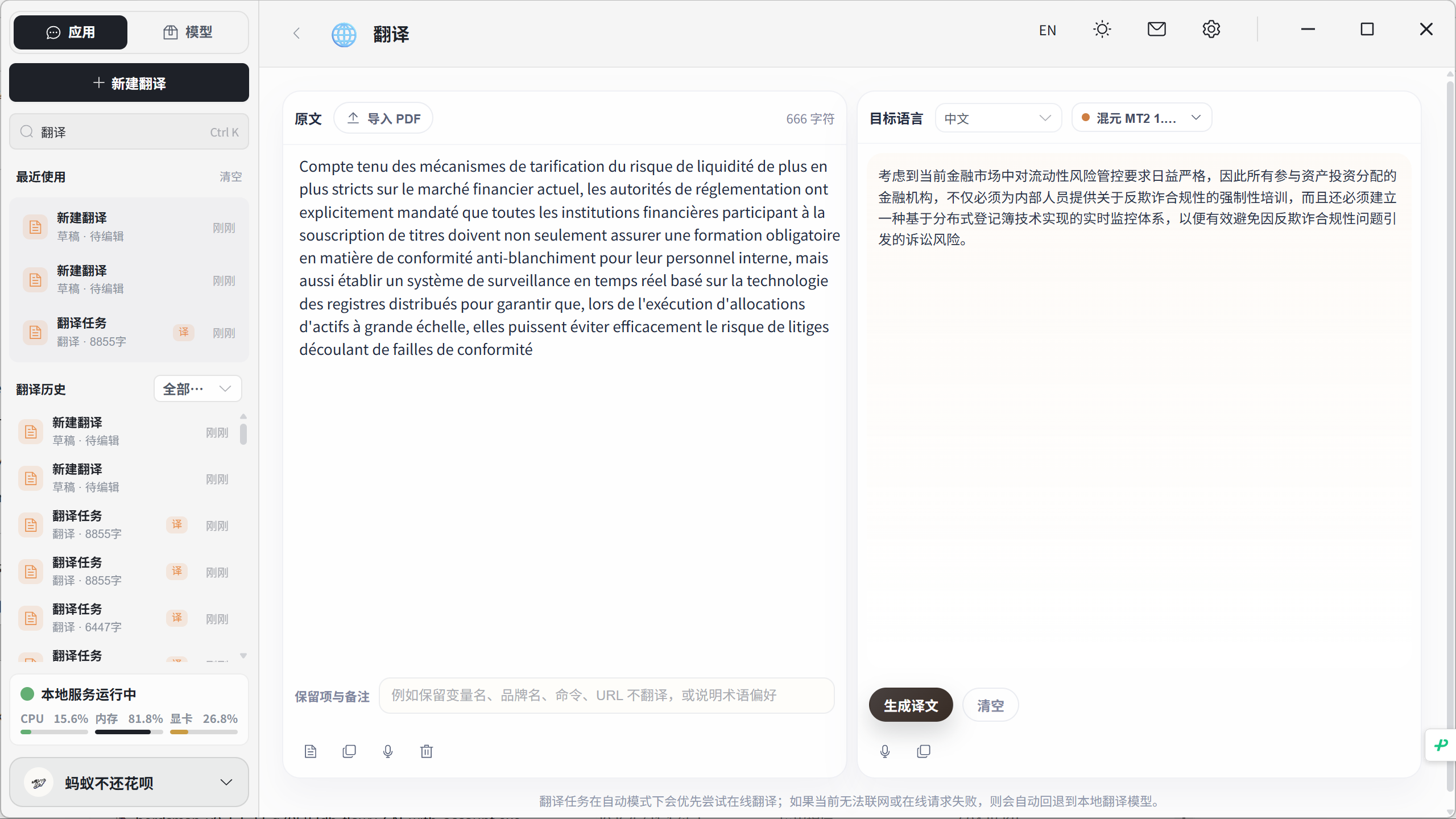
支持导入PDF,语音实时翻译,翻译时可以加入一些保留项与备注(如保留变量名、品牌名、不翻译URL等)
八、总结与资源链接
在 Hy-MT2 发布的同一天,OpenVINO™ 工具链就完成了对其的端到端支持,开发者只需 1 条 optimum-cli 命令 + 几行 openvino-genai 代码,即可在 Intel CPU / GPU / NPU 上获得高质量、可控、可流式输出的多语言翻译能力。
OpenVINO™ Notebooks PR #3464: https://github.com/openvinotoolkit/openvino_notebooks/pull/3464
Hugging Face 模型**: https://huggingface.co/collections/tencent/hy-mt2
ModelScope 模型**: https://modelscope.cn/collections/Tencent-Hunyuan/Hy-MT2
GitHub: https://github.com/Tencent-Hunyuan/Hy-MT2
optimum-intel: https://github.com/huggingface/optimum-intel
NNCF: https://github.com/openvinotoolkit/nncf
OpenVINO™ GenAI: https://github.com/openvinotoolkit/openvino.genai
数据来源:腾讯混元官方发布稿(2026 年 5 月 21 日);OpenVINO Notebooks PR #3464。本文涉及的 FLORES-200、IFMT Bench、A15 推理加速 1.5× 等数字均为厂商公布数据,Intel 平台上的实际表现请以读者自有硬件 benchmark 为准。